泪流满面的 11 个 Git 面试题
目录
在今年的 Stack Overflow 开发者调查报告中,超过 70% 的开发者使用 Git,使其成为世界上使用人数最多的版本控制系统。Git 通常用于开源和商业软件开发,对个人、团队和企业都颇有益处。
Q1: 什么是 Git 复刻(fork)?复刻(fork)、分支(branch)和克隆(clone)之间有什么区别?
主题:Git 难度:⭐⭐
- 复刻(fork) 是对存储仓库(repository)进行的远程的、服务器端的拷贝,从源头上就有所区别。复刻实际上不是 Git 的范畴。它更像是个政治/社会概念。
- 克隆(clone) 不是复刻,克隆是个对某个远程仓库的本地拷贝。克隆时,实际上是拷贝整个源存储仓库,包括所有历史记录和分支。
- 分支(branch) 是一种机制,用于处理单一存储仓库中的变更,并最终目的是用于与其他部分代码合并。
🔗来源: stackoverflow.com
Q2: “拉取请求(pull request)”和“分支(branch)”之间有什么区别?
主题:Git 难度:⭐⭐
- 分支(branch) 是代码的一个独立版本。
- 拉取请求(pull request) 是当有人用仓库,建立了自己的分支,做了些修改并合并到该分支(把自己修改应用到别人的代码仓库)。
🔗来源: stackoverflow.com
Q3: “git pull”和“git fetch”之间有什么区别?
主题:Git 难度:⭐⭐
简单来说,git pull 是 git fetch + git merge。
- 当你使用
pull,Git 会试着自动为你完成工作。它是上下文(工作环境)敏感的,所以 Git 会把所有拉取的提交合并到你当前处理的分支中。pull则是 自动合并提交而没有让你复查的过程。如果你没有细心管理你的分支,你可能会频繁遇到冲突。 - 当你
fetch,Git 会收集目标分支中的所有不存在的提交,并将这些提交存储到本地仓库中。但Git 不会把这些提交合并到当前分支中。这种处理逻辑在当你需要保持仓库更新,在更新文件时又希望处理可能中断的事情时,这将非常实用。而将提交合并到主分支中,则该使用merge。
🔗来源: stackoverflow.com
Q4: 如在 Git 恢复先前的提交?
主题:Git 难度:⭐⭐⭐
假设你的情形是这样,其中 C 是你的 HEAD,(F) 是你文件的状态。
|
1
2
3
4
|
(F)
A–B–C
↑
master
|
- 要修改提交中的更改:
|
1
|
git reset —hard HEAD~1
|
现在 B 是 HEAD,因为你使用了 --hard,所以你的文件将重置到提交 B 时的状态。
- 要撤销提交但保留更改:
|
1
|
git reset HEAD~1
|
现在我们告诉 Git 将 HEAD 指针移回(后移)一个提交(B),并保留文件原样,然后你可以 git status 来显示你已经检入 C 的更改。
- 撤销提交但保留文件和索引:
|
1
|
git reset —soft HEAD~1
|
执行此操作后,git status,你讲看到索引中的文件跟以前一致。
🔗来源: stackoverflow.com
Q5: 什么是“git cherry-pick”?
主题:Git 难度:⭐⭐⭐
命令 git cherry-pick 通常用于把特定提交从存储仓库的一个分支引入到其他分支中。常见的用途是从维护的分支到开发分支进行向前或回滚提交。
这与其他操作(例如:合并(merge)、变基(rebase))形成鲜明对比,后者通常是把许多提交应用到其他分支中。
小结:
|
1
|
git cherry–pick <commit–hash>
|
🔗来源: stackoverflow.com
Q6: 解释 Forking 工作流程的优点
主题:Git 难度:⭐⭐⭐
Forking 工作流程 与其他流行的 Git 工作流程有着根本的区别。它不是用单个服务端仓库充当“中央”代码库,而是为每个开发者提供自己的服务端仓库。Forking 工作流程最常用于公共开源项目中。
Forking 工作流程的主要优点是可以汇集提交贡献,又无需每个开发者提交到一个中央仓库中,从而实现干净的项目历史记录。开发者可以推送(push)代码到自己的服务端仓库,而只有项目维护人员才能直接推送(push)代码到官方仓库中。
当开发者准备发布本地提交时,他们的提交会推送到自己的公共仓库中,而不是官方仓库。然后他们向主仓库提交请求拉取(pull request),这会告知项目维护人员有可以集成的更新。
🔗来源: atlassian.com
Q7: 告诉我 Git 中 HEAD、工作树和索引之间的区别?
主题:Git 难度:⭐⭐⭐
- 该工作树/工作目录/工作空间是你看到和编辑的(源)文件的目录树。
- 该索引/中转区(staging area)是个在
/.git/index,单一的、庞大的二进制文件,该文件列出了当前分支中所有文件的 SHA1 检验和、时间戳和文件名,它不是个带有文件副本的目录。 - HEAD是当前检出分支的最后一次提交的引用/指针。
🔗来源: stackoverflow.com
Q8: 你能解释下 Gitflow 工作流程吗?
主题:Git 难度:⭐⭐⭐
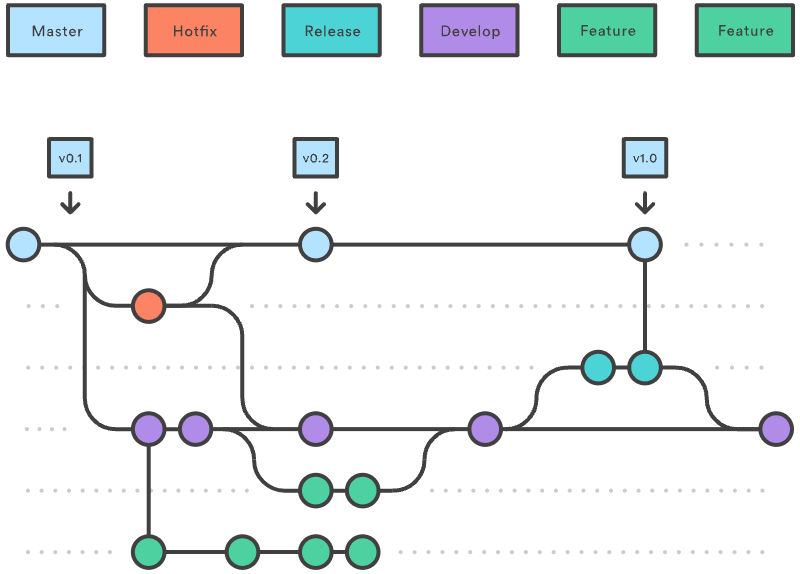
Gitflow 工作流程使用两个并行的、长期运行的分支来记录项目的历史记录,分别是 master 和 develop 分支。
- Master,随时准备发布线上版本的分支,其所有内容都是经过全面测试和核准的(生产就绪)。
- Hotfix,维护(maintenance)或修复(hotfix)分支是用于给快速给生产版本修复打补丁的。修复(hotfix)分支很像发布(release)分支和功能(feature)分支,除非它们是基于
master而不是develop分支。
- Hotfix,维护(maintenance)或修复(hotfix)分支是用于给快速给生产版本修复打补丁的。修复(hotfix)分支很像发布(release)分支和功能(feature)分支,除非它们是基于
- Develop,是合并所有功能(feature)分支,并执行所有测试的分支。只有当所有内容都经过彻底检查和修复后,才能合并到
master分支。- Feature,每个功能都应留在自己的分支中开发,可以推送到
develop分支作为功能(feature)分支的父分支。
- Feature,每个功能都应留在自己的分支中开发,可以推送到
🔗来源: atlassian.com
Q9: 什么时候应使用 “git stash”?
主题:Git 难度:⭐⭐⭐
git stash 命令把你未提交的修改(已暂存(staged)和未暂存的(unstaged))保存以供后续使用,以后就可以从工作副本中进行还原。
回顾:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
$ git status
On branch master
Changes to be committed:
new file: style.css
Changes not staged for commit:
modified: index.html
$ git stash
Saved working directory and index state WIP on master: 5002d47 our new homepage
HEAD is now at 5002d47 our new homepage
$ git status
On branch master
nothing to commit, working tree clean
|
我们可以使用暂存(stash)的一个地方是,如果我们发现在上次提交中忘记了某些内容,并且已经开始在同一分支中处理下一个提交了:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# Assume the latest commit was already done
# start working on the next patch, and discovered I was missing something
# stash away the current mess I made
$ git stash save
# some changes in the working dir
# and now add them to the last commit:
$ git add –u
$ git commit —ammend
# back to work!
$ git stash pop
|
🔗来源: atlassian.com
Q10: 如何从 git 中删除文件,而不将其从文件系统中删除?
主题:Git 难度:⭐⭐⭐⭐
如果你在 git add 过程中误操作,你最终会添加不想提交的文件。但是,git rm 则会把你的文件从你暂存区(索引)和文件系统(工作树)中删除,这可能不是你想要的。
换成 git reset 操作:
|
1
2
|
git reset filename # or
echo filename >> .gitingore # add it to .gitignore to avoid re-adding it
|
上面意思是,git reset <paths> 是 git add <paths> 的逆操作。
🔗来源: codementor.io
Q11: 是么时候使用“git rebase”代替“git merge”?
主题:Git 难度:⭐⭐⭐⭐⭐
这两个命令都是把修改从一个分支集成到另一个分支上,它们只是以非常不同的方式进行。
考虑一下场景,在合并和变基前:
|
1
2
3
4
|
A <– B <– C [master]
^
\
D <– E [branch]
|
在 git merge master 之后:
|
1
2
3
4
|
A <– B <– C
^ ^
\ \
D <– E <– F
|
在 git rebase master 之后:
|
1
|
A <– B <– C <– D <– E
|
使用变基时,意味着使用另一个分支作为集成修改的新基础。
何时使用:
- 如果你对修改不够果断,请使用合并操作。
- 根据你希望的历史记录的样子,而选择使用变基或合并操作。
更多需要考虑的因素:
- 分支是否与团队外部的开发人员共享修改(如开源、公开项目)?如果是这样,请不要使用变基操作。变基会破坏分支,除非他们使用
git pull --rebase,否则这些开发人员将会得到损坏的或不一致的仓库。 - 你的开发团队技术是否足够娴熟?变基是一种破坏性操作。这意味着,如果你没有正确使用它,你可能会丢失提交,并且/或者会破坏其他开发者仓库的一致性。
- 分支本身是否代表有用的信息?一些团队使用功能分支(branch-per-feature)模式,每个分支代表一个功能(或错误修复,或子功能等)。在此模式中,分支有助于识别相关提交的集合。在每个开发人员分支(branch-per-developer)模式中,分支本身不会传达任何其他信息(提交信息已有作者)。则在这种模式下,变基不会有任何破坏。
- 是否无论如何都要还原合并?恢复(如在撤销中)变基,是相当困难的,并且/或者在变基中存在冲突时,是不可能完成的。如果你考虑到日后可能需要恢复,请使用合并操作。
🔗来源: stackoverflow.com
打赏支持我翻译更多好文章,谢谢!
打赏支持我翻译更多好文章,谢谢!
任选一种支付方式


关于作者:BEASTQ

转载自:http://blog.jobbole.com/114297/