
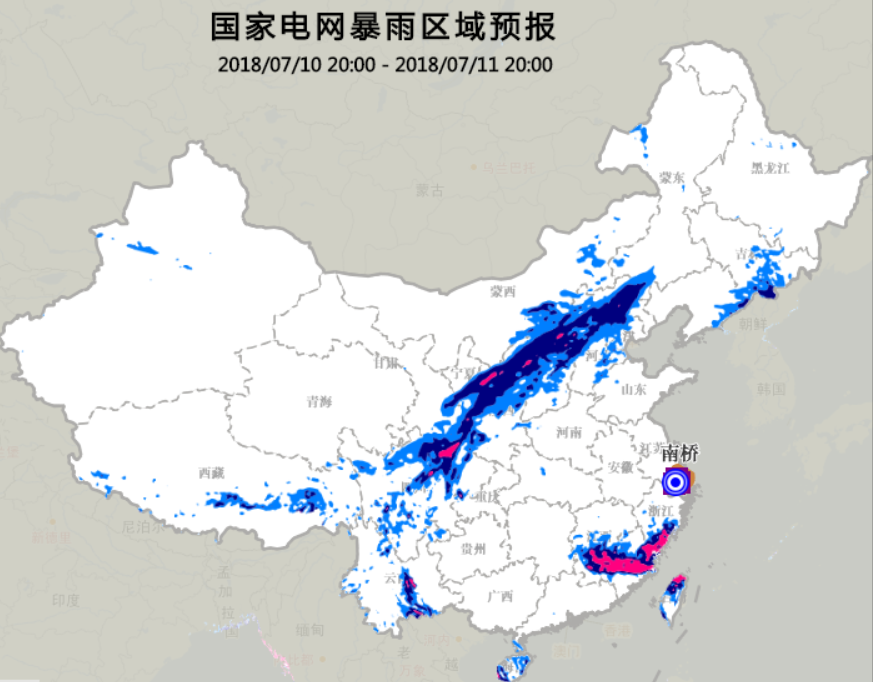
基于PostGIS叠加分析优化–气象预警分析案例实践
目录
一 案例简介
电力行业在未来和气象领域的结合会越来越普及,衍生的各种复杂GIS分析也是很多的,如暴雨(气象)覆盖范围+地形分布区域(地质领域)+地貌分布区(植被覆盖分布)做叠加分析,如果地物是小土山,且植被覆盖率非常低,这里就特别容易发生滑坡,泥石流,而国网比如在复杂地形区新建一个电站,可以使用类似的分析,规避地质灾害,气象灾害频发区域,这些灾害之间好像还有相互关联性(GIS应该是做这种高级分析的,寻常定位高亮这种,怎么能算成GIS啊?)。
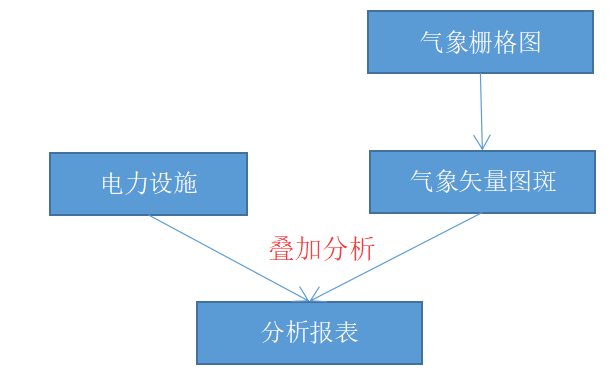
本文选择一个简单的例子,电力设施管理部门有很多地理位置的设施如杆塔(点数据),xx气象单位每天2点,8点,14点,20点定时推送气象预警分布图,业务要求快速解析图斑成矢量面,根据矢量的气象影响分布区域面叠加分析出受影响的电网设施(如杆塔)。
业务特点:
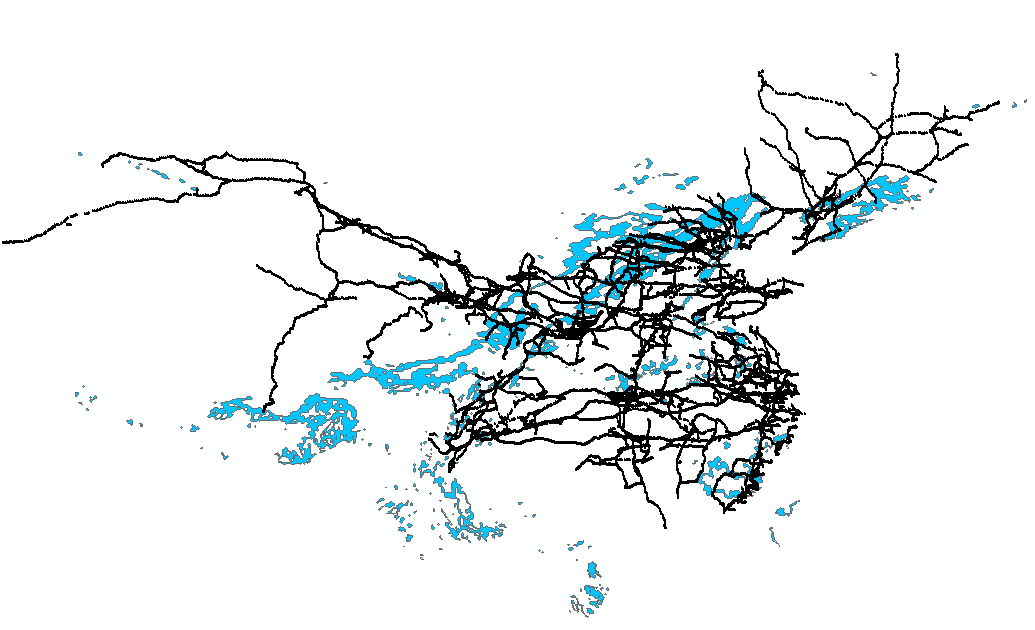
- 电力设施多,分布广。如杆塔可能上百万级别,分布在全国各地。
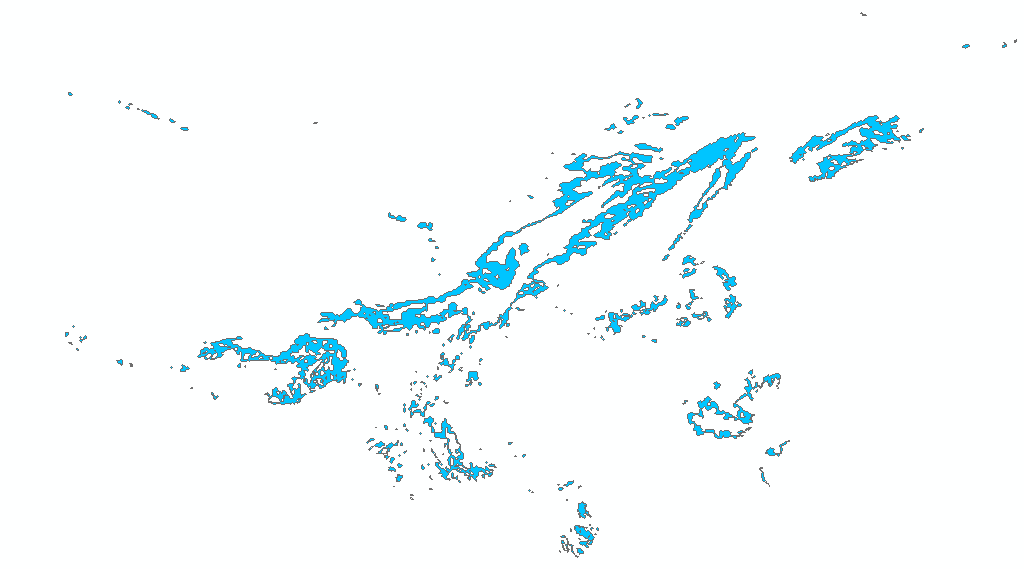
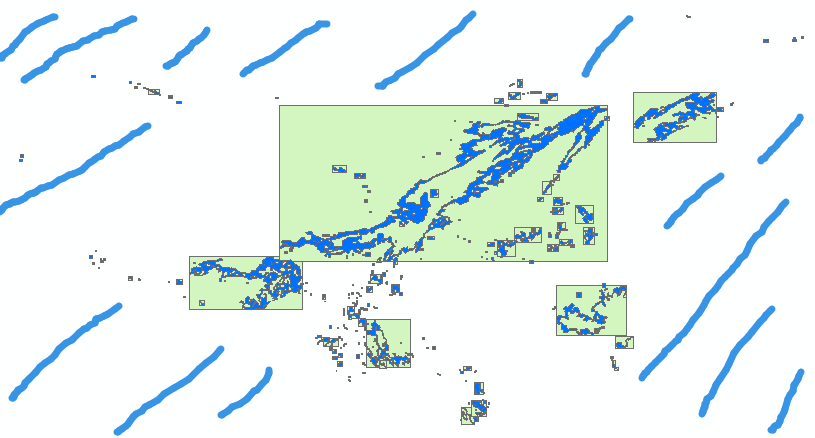
- 气象预警解析的矢量图斑,极其不规则。解析人员对每批次预警解析结果以MultiPolygon存储,如上图,暴雨图斑矢量化在表中其实是一条记录,但图形有很多散落独立的面状区域。
二 数据和分析现状描述
#电力设备测试数量
test=# select count(*) from dlsb;
count
-------
99007
(1 行记录)
# 测试的暴雨数据
test=# select count(*) from rain;
count
-------
1
(1 行记录)
# 暴雨图斑类型
test=# select St_GeometryType(geom) GeomType,ST_NumGeometries(geom) GeomCount from rain;
geomtype | geomcount
-----------------+-----------
ST_MultiPolygon | 307
(1 行记录)
电力设备和暴雨矢量图斑分布见图3,从数据库可以看到,遍布全国的暴雨图斑其实就是一条记录,其图形类型是ST_MultiPolygon,子图形数量是307个,也就是这个ST_MultiPolygon是由307个Polygon组成的。
作者使用win10单机部署的机器,稍微改了下postgresql.conf中几个内存相关参数其他没怎么动的原始机器测试:
test=# select count(a.*) from dlsb a,rain b where st_intersects(a.geom,b.geom);
count
-------
12814
(1 行记录)
Time: 41401.309 ms (00:41.401)
分析一批次数据,需要耗时41s,更别说什么其他业务多表join之类的操作了,不可接受!
三 优化之路
空间分析,主要是使用geom的gist索引去完成的,关于gist索引优化之路的原理,参考德哥的两篇博客:
- 《PostgreSQL 空间st_contains,st_within空间包含搜索优化 – 降IO和降CPU(bound box) (多边形GiST优化)》
- 《PostgreSQL 空间切割(st_split, ST_Subdivide)功能扩展 – 空间对象网格化 (多边形GiST优化)》
3.1 优化原则
作为业务开发者,我们在优化分析时,一定要遵循这样的原则:
- 1 尽可能的将复杂图形,拆分成简单图形。如MultiPoint,MultiLineString,MultiPolygon之类的对应拆分成单义图形类型Point,LineString,Polygon。
- 2 对于复杂的单个图形,尽可能使用合理的切割方法,切割成更小更简单的图形。(切割后,每个简单的图形的bbox更紧凑,大图形的bbox中无效分析区域尽可能被挤压掉,从而尽可能增加单个图形的图形面积与外接矩形面积的比重。这个比重越大代表图形有效面积越大,索引效果越好。)
3.2 优化路线
既然我们制定了空间分析的两个优化原则,优化路线严格遵循原则去实践。
3.2.1 耗时从41s减少到6s
基于原则一,将复杂图形拆分成简单图形:
--新建一个新的表,存储拆分后的图形
CREATE TABLE rain_single
(
gid serial primary key,
geom geometry(Polygon,4326)
);
--建立索引
CREATE INDEX rain_single_geom_idx
ON rain_single USING gist
(geom);
--将拆分结果存入新的表中
INSERT INTO public.rain_single(geom) SELECT
ST_GeometryN(a.geom, n) As geom FROM rain a
CROSS JOIN generate_series(1,400) n WHERE n 简单拆分后,分析步骤如下:
test=# select count(a.*) from dlsb a,rain_single b where st_intersects(a.geom,b.geom);
count
-------
12814
(1 行记录)
Time: 6088.242 ms (00:06.088)
简简单单的,光看分析结果耗时就深受鼓舞!!!
原理:该图片的边框就是初始的那个暴雨MultiPolygon图形的外接矩形。拆分成若干个单义图形之后,绿色部分是单义图形的外接矩形。拆分后的图形的外接矩形和原MultiPolygon图形的外接矩形的差异就是白色填充,蓝色斜线部分。拆分后,蓝色斜线部分都是被优化的查询空间,大大压缩了查询空间,降了io和cpu所以提升了整体效果。
3.2.2 耗时从6s到70ms
基于原则一成功的将Multi改变成单义图形之后,极大降低了io和cpu,大量无效分析空间被清除。但是通过上图可知,部分图形仍然非常零散细碎,外接矩形非常的大,空白(蓝绿色部分)区域还是很大。因此,我们考虑原则二,尽可能的去对这些复杂单个图形切割。
使用PostGIS你很幸运,不需要自己写算法了,其提供的ST_Split和ST_Subdivide都可以比较轻松的切割图形。ST_Split执行一次,会将一个图形切成两个部分,实际使用的时候,这种算法比较适合规整的图形(容易凭感觉切成几个部分那种图形,参考德哥的切割算法),而我这个暴雨区域,太过复杂,从东到西,由南至北,我也不知道切割成多少份,所以这种情况ST_Subdivide更适合。
ST_Subdivide API说明:
#输入图形,设置可选参数,切割的每一个图形最大的定点数,默认是256。
#返回被切割后形成的图形要素记录集。
setof geometry ST_Subdivide(geometry geom, integer max_vertices=256);
测试的时候,我们先设置最大定点数为20:
#生成切割测试数据
test=# SELECT row_number() OVER() As id,geom into rain_Subdivide from (select ST_SubDivide(geom,20) geom from rain_single) as f(geom);
alter table rain_Subdivide alter column geom type geometry(Polygon,4326) using geom:: geometry(Polygon,4326);
create index rain_Subdivide_geom_idx on rain_Subdivide using gist(geom);
#测试数据空间分析
test=# select count(a.*) from dlsb a,rain_Subdivide b where st_intersects(a.geom,b.geom);
count
-------
12814
(1 行记录)
Time: 1138.848 ms (00:01.139)
已经优化到1s钟完成分析了,我们可视化下切割图形:
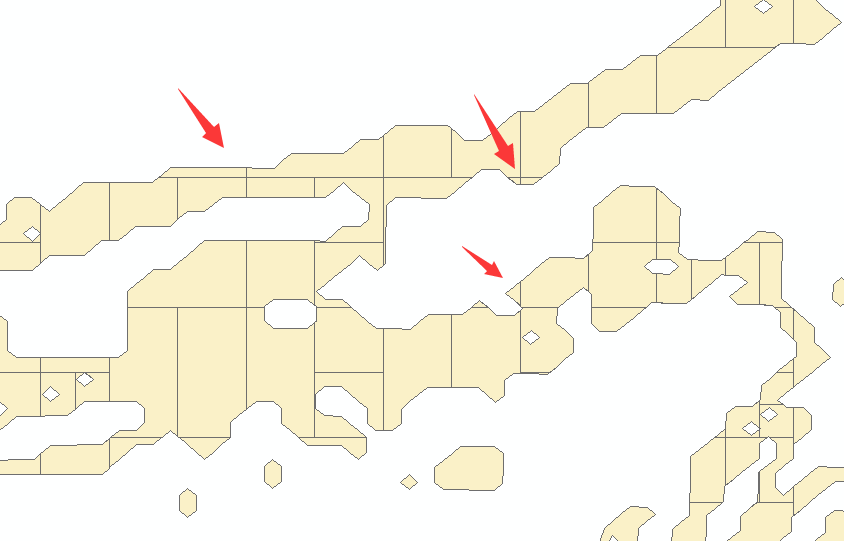
从图上观察,还有很多切割后细碎的图形,我想,是不是切割的节点数设置大一点,可以合并部分区域,减少这种细碎部分?于是我设置成节点数为40:
#生成切割测试数据
test=# drop table rain_Subdivide;
test=# SELECT row_number() OVER() As id,geom into rain_Subdivide from (select ST_SubDivide(geom,40) geom from rain_single) as f(geom);
alter table rain_Subdivide alter column geom type geometry(Polygon,4326) using geom:: geometry(Polygon,4326);
create index rain_Subdivide_geom_idx on abc using gist(geom);
#测试数据空间分析
test=# select count(a.*) from dlsb a,rain_Subdivide b where st_intersects(a.geom,b.geom);
count
-------
12814
(1 行记录)
时间:69.127 ms
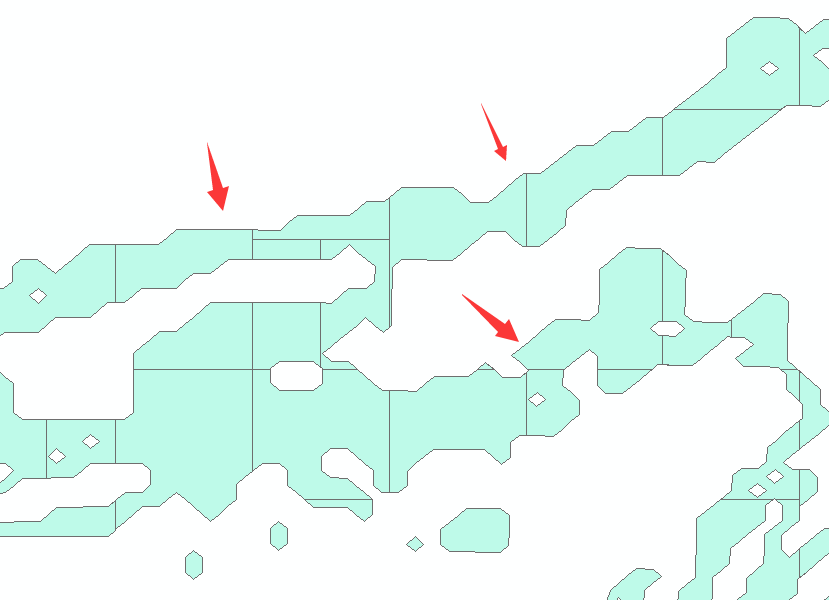
对比20节点数,发现的确实现了部分细碎图形消融了的结果,箭头处对比可知,所以速度提升了很多。
oh my god,这简单的个例,竟然把41s的分析耗时,优化到了69ms,分析速度提升了约600倍!
对于切割80,100节点作者没有尝试,切割节点既不能太大,否则图形很复杂;也不能太小,容易产生很多细窄狭长的小图形,很影响性能,建议根据实际数据情况多测试测试,找到一个较好的中间值作为切割最大节点数的阈值。
四 优化意义
优化之前,由于41s的查询,oltp出报表基本不可能,解决方案是离线预先叠加分析结果中间表,把结果中间表存储到业务表的数据库中,所以占用很多计算和存储资源,另外一个问题是,电网业务资源更新后,分析的结果和当前的资源明显结果和图形显示不一致了。
| 优化前 | 优化后 |
|---|---|
| 需要大量的io和cpu分析计算 | 很少量资源 |
| 该业务每天可能产生1G多的中间表 | 存储消耗0 |
| 业务数据变更与中间表对应不上 | 实时分析,一定一致 |
| 每天需要计算 | 不用计算,入库拆分原始面图形即可 |
| 耗时600单位 | 耗时1单位 |
综述:计算资源消耗的更少了,存储资源消耗的更少了,计算速度百倍提升,业务关系实时一致。

