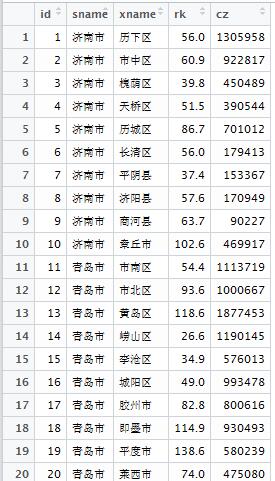
空间统计—度量地理分布工具集,Measuring Geographic Distributions
rnCenter Featurernrn工具简介rn该工具可以从输入的要素中找出距其他要素距离之和最小的要素,将其写到输出要素类中。例如想在城区建立一个新的剧院,可以从所有的街区中来找中心要素,并且可按人口权重进行计算,即可得到距其他所有街区通行代价最小的位置作为候选地址。rnrn主要参数rn Input Feature Class:输入的矢量要素类,一般是点类型;对于线类型或面类型的要素,

gis,openlayers,leaflet,gis应用,geoai,geoserver,cesium,python,arcpy,arcmap,webgis,gis可视化
rnCenter Featurernrn工具简介rn该工具可以从输入的要素中找出距其他要素距离之和最小的要素,将其写到输出要素类中。例如想在城区建立一个新的剧院,可以从所有的街区中来找中心要素,并且可按人口权重进行计算,即可得到距其他所有街区通行代价最小的位置作为候选地址。rnrn主要参数rn Input Feature Class:输入的矢量要素类,一般是点类型;对于线类型或面类型的要素,

关于空间统计的几种常用算法

空间分析的根基,来源于60年代Waldo R. Tobler教授“地理学第一定律”的“Tobler’s First Law”(简称TFL),即为“Everything is related to everything else, but near things are more related to each other。”。翻译成大白话,就是:任何事情呢,都是有关系,只不过靠得越近,关系就越紧密
(再次接近6000字,诚意满满啊)rnrn从这一章开始进入实际操作环节……首先还是用ArcGIS,毕竟这个东西比较容易。rnrn实际上要说起来,GWR有专门的软件,叫做GWR,但是这个软件暂时我还没有用过,所以等我先学习一下,把他放到最后才说了,先用比较熟悉的,比如ArcGIS、比如R语言,这些来讲讲(还有一个我非常熟悉的软件是GEODA,可惜GEODA仅支持回归分析,不支持地理加权回归)。rnr
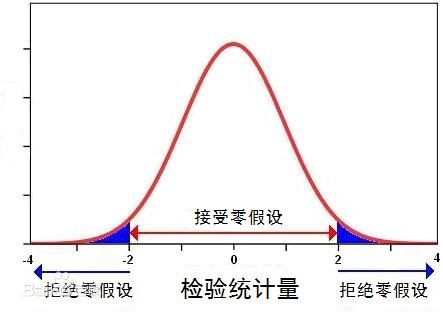
rnrnrn 首先是空间统计里面很神秘的两个值:P值和Z值。rnrnrn 要说这两个值之前,还是要复习一下统计学的概念,毕竟空间统计的理论基础还是建立在经典统计学上面的。rn首先,统计学里面,有一个叫做“零假设”的概念非常厉害,一定要说说。rnrnr

空间分析里面,最重要的一个概念就是距离,不同的距离会导致不同的结果。在研究的时候,有种叫做“空间尺度”的概念,这个有兴趣的话,请自行百度(老规矩:百度知道的东西别问我)。rn rn所以,在研究聚类的时候,最重要的就是确定不同数据之间的距离,否则就会如下:rn rnrnrn rn rn聚类分析中,要素之间的距离是个很重要的参数;也就是说两个要素相隔多远才算是聚成一类呢?在任何一种聚类算法中,探索一个

年底事情那是相当的多,各种总结和出差,所以我们的白话空间统计足足停掉一个多月了,为了有一个比较圆满的里程碑,我决定在猴年开始之前,预告一下2016年我在公众号里面将会更新的一些东西,另外大家想看啥,也可以给我发信息,如果我懂的,我可以考虑加到公众号里面去。rn rn在2016年中,预计会在公众号写如下系列的文章:rn rn1、继续写白话空间统计系列,当然除了空间统计,还有一些经典统计包括数理统计、
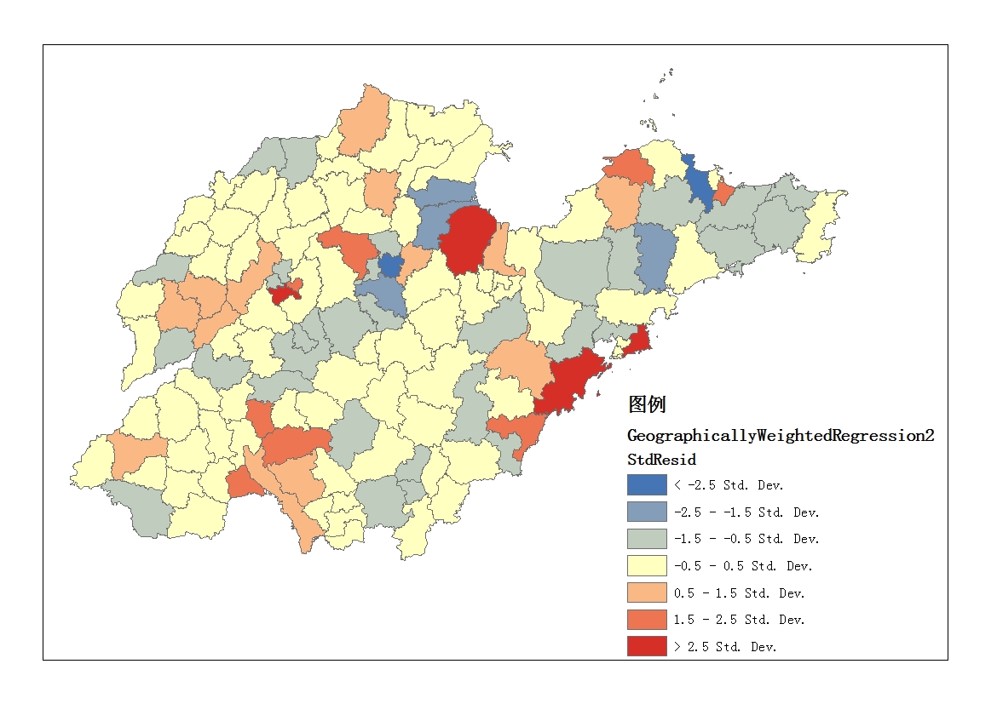
地理加权回归分析完成之后,与OLS不同的是会默认生成一张可视化图,像下面这张一样的:rnrnrn这种图里面数值和颜色,主要是系数的标准误差。主要用来衡量每个系数估计值的可靠性。标准误差与实际系数值相比较小时,这些估计值的可信度会更高。较大标准误差可能表示局部多重共线性存在问题。根据官方的说法,需要检查超过2.5倍标准差的地方……这些地方可能会有问题。rnrn虽然在软件里面,默认只显示这样一张图,但
在讲GWR的ArcGIS应用之前,首先讲讲ArcGIS里面的OLS(Ordinary least squares:普通最小二乘法)工具的应用和解读,毕竟GWR是从回归分析里面演化出来的,OLS又是回顾分析里面最简单的算法,如果不了解OLS的意义,那么GWR结果的最后意义一样没没理解。rnrn关于回归分析和OLS的基础算法,我就不在这里赘述了,大家有兴趣去看相关资料和我以前的文章,这篇就直接扣住Ar
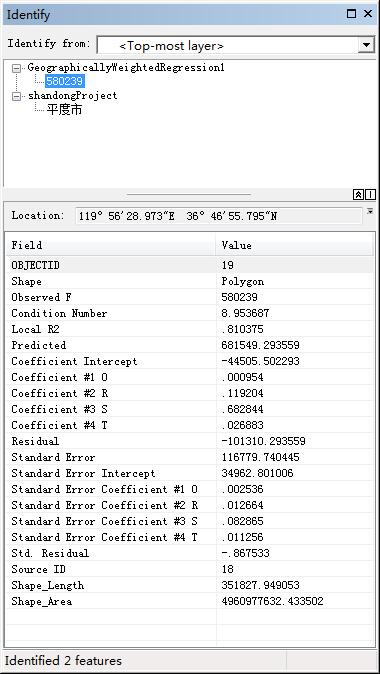
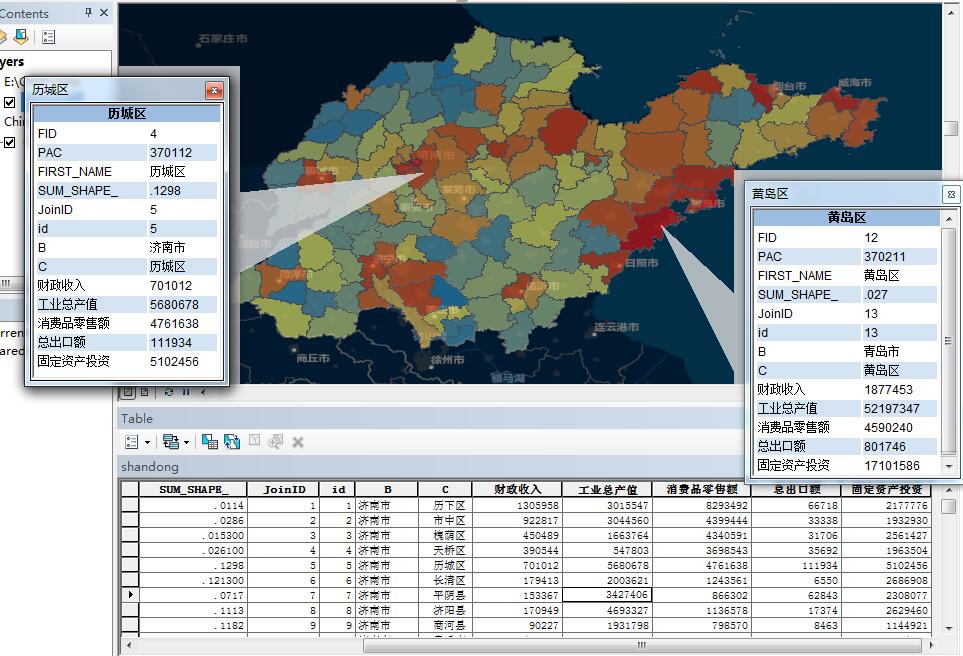
实际上,除了辅助表以外,GWR还会生成一份全要素的表。对回归的每一个样本都给出相应的信息,今天就来看看这些信息代表了什么内容。rnrn生成的新的要素类字段信息如下:rnrnrnrn实际上,Coeffcient(系数)和Standard Error Conffcient (标准差系数)会对每一个解释变量都给出一个值,所以可以看成是两类值,下面把各个值的情况和意义做个简单描述:rnrn其中ArcGIS

前段时间,有人批评我写白话空间统计的博客是在写软文给ArcGIS平台和Esri打广告,话说这个实在是太恭维我了。如果读到空间统计,而且还能读懂的人,不可能没有听说过ArcGIS软件吧,这种情况到底是先有鸡还是先有蛋,自然一目了然了。rn rn虽然虾神在Esri中国干了好多年了,给公司打打广告也是理所当然的事情。但是写博客的时候确实还真没有这个想法,不过既然有人批评了,那么虾神我先挑明一下这系列白话

书接上一回。rn rn多距离空间聚类分析这个工具与其他的工具计算出来的结果都不太一样。按照空间分析软件的一般规律,扔进去的是一个空间数据,那么返回的自然也是一个空间数据……rn rn不过在前面也很多分析工具告诉我们,可能就会返回几个数据给你,比如莫兰指数,给你几个值来表示一下。这个多距离空间聚类分析工具为为什么会让我们觉得神奇呢?因为他的返回值很神奇——它会返回一堆的数字给你。rnrnrn返回的值
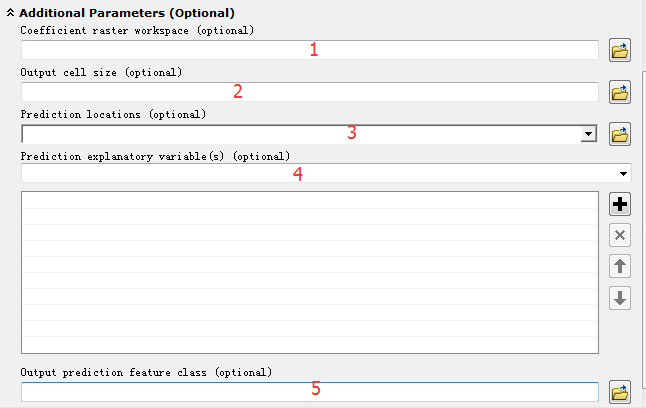
白话空间统计二十四:地理加权回归(七)ArcGIS的GWR工具扩展参数说明rnrn近期无论是开发者大会,还是个人工作,相当的忙,所以停了一段时间……不过地理加权回归写到第七章,自我感觉也差不多了,无论是基础理论还是来历,包括基础参数的意义,都应该介绍得比较清楚了,当然,后面可能是大家更关心的内容,也就是在ArcGIS(或者其他软件里面),怎么去执行地理加权回归
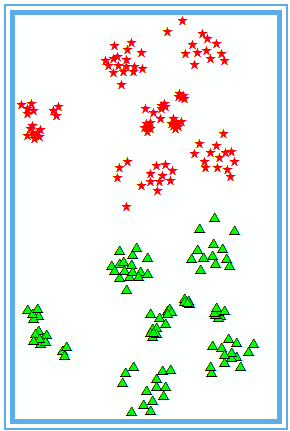
平均最近邻可以得出一份数据的具体聚集程度的指数,通过这个指数,可以对比不同数据中,哪个数据的聚集程度最大。适用于对固定研究区域中不同的要素进行比较。比如在同一城市范围内,不同类型的企业之间的分布情况的研究;或者同一类型的企业,在固定区域以内,随着不同年份的变化情况的研究。

其实,如果用一句话来说明着两个模块有啥区别,就以下这句就可以了:(ArcGIS的)空间统计模块主要用于研究和分析矢量数据。(ArcGIS的)空间分析模块主要用于研究和分析栅格数据。因为空间统计模块所有的工具,都以矢量数据为输入和输出,而空间分析模块,的输入或者输出里面,最起码有一个是栅格数据(或者以栅格为输入,或者以栅格为输出,也有输入输出都是栅格的)。

前缘再续,书接上一回……rnrn要理解回归分析的这些特点(优点)以及特性,首先得了解一下回归分析的一些概念。rnrn所谓“信息从来是一切的基础,世界上从不存在建立在空中楼阁上的智慧,搜集、处理信息本身就是一种智慧的体现”,只要有足够的信息,就能得到所需要的任何结论。君不见,在形容神的时候,把神称为“全知全能”……知还在能的前面……好吧,扯远了,回来继续我们的回归分析。rnrn在分析任何事务之前,都

衡量空间自相关的时候,用的参数是Moran’I(莫兰指数),那么在衡量搞低值聚类的时候,用的也是一个指数,这个指数叫做 General G 指数。
题目还是取了个白话空间统计,所以总是有点怪怪的。rn rn不过空间统计要是完全脱离经典统计学去谈,那就真是坠入魔道了……计量革命最主要的成果之一,就是促成了经典统计分析方法在地理学研究中的应用。直到今天,经典统计学还是计量地理学中最常用的手段。可以说,空间统计学仍然是在经典统计学理论上建立和发展起来的。
要讲回归分析,绕不开的话题就是相关系数,在白话空间统计十八:相关性分析里面,对这个问题做了一个简要的描述,但是回过头来看,还有挺多东西漏掉了的,今天再用一个篇幅来讲讲相关系数一些其他的东西,并且给出数据和R语言脚本。rnrn不知道大家还记得在空间上如何描述一组数据的方向和分布,如果不记得的话,可以去看看白话空间统计的第九章《方向分布》,得到的结果可以通过一系列的参数来决定一批点数据的方向和分布情况

空间自相关,肯定是空间统计里面第一个拦路虎了,很多人遇上了这个高大上的词汇,立刻就发现,这五个字我好像都认识,但是到底说了啥?不知道。如果翻开各种教材,从统计学到数学到物理学,各种解释都摆出了一副“老子就是高大上学霸,屌丝学渣勿扰”的样子,这个东西真得就那么难么?

其实我一直是不愿意填算法坑的……主要是自己的数学水平很一般,很容易出现填坑不成自己反被埋的情况,但是这个坑不填又不行,所以在填坑之前说明:这个仅是虾神我自己的理解,不代表原文(限于能力问题,数学论文确实不怎么能读透),如果有疑惑或者错误,请自行查阅原始论文,虾神只负责科普。
本来这一章准备直接写(照抄)ArcGIS的帮助文档,写地理加权回归工具的使用……,然后就直接结束地理加权回归的,但是近来收到不少同学的邮件,很多都是掉在了当年虾神挖出的大坑里面,比如写了方法,没有列出公式,又比如写了公式木有推导过程(……作为高数战五渣的虾神,推导这种事,他认识我,我不认识他……)rnrn所以这次写GWR的时候,尽量少挖点坑,把该写的东西都写完,一者为了以后路过的同学少掉点坑,二者

P值的计算一直是很多初学者们所纠结的问题。包括虾神我开始学习的时候也是一样……数学是一种科学的语言,追求的就是精确性——连在数轴上纯随机出现的孪生素数都被刷出下限来了,还有什么东西是不能精确识别的?rnrn但是你翻遍整个搜索引擎,发现问“P值计算公式”的帖子也算铺天盖地了,但是从来就是:rnrn某人问:rnrnrn某大神答:很简单的拉……rnrnrn某人:rnrnrn好吧……为了虾神也不被打成星星

莎老爷子著名的四大悲剧之一的哈雷王子。。。里面这句话一直是文艺小青年们zhuangbility的金牌用语……实际上说出了这样一句大实话:千古艰难惟一死。n n人为什么怕死,无非就是没有死过而已。如果想一个人没事一天就死个十回八回的,那么有何可怕?这就是一切生物最原始的一种恐惧:对于未知的恐惧。n n所以呢,我们都习惯找一个熟悉的地方,和一群熟悉的人,聊一些熟悉的话题……当然,不可能永远都在
昨天简单的写了写相似性搜索的主要方法,这些方法对于学GIS的同学来说,实在是太简单了,所以很多同学反应:虾神泥垢了!科普也要有点深度可好,你是在凑字数么!!rn rn好吧,我觉得上篇文章是有点点问题……我们要向前看,反正已经发出去了,这篇文章就扔那里吧,作为存档用。rn rn今天继续写相似性搜索,昨天说了6种方法,简单是简单,但是大道至简,所有的分析算法,都是从这些简单的内容里面发展来的。不过还缺

今天主要讲讲核密度分析的R语言实现,原理神马的,看前面的文章。nn下面贴代码和代码注释,还是老规矩,需要源代码还数据的,通过邮箱获取。
方向分布工具在空间统计中是综合能力最突出的工具之一,有着广泛的应用,在我们的分析和数据探索的时候,能够起到非常重大的作用。

Moran’s I这个东西,官方叫做:莫兰指数,是澳大利亚统计学家帕特里克·阿尔弗雷德·皮尔斯·莫兰(Patrick Alfred Pierce Moran),在1950年提出的。一般是用来度量空间相关性的一个重要指标。

白话空间统计二十一:密度分析(一)rnrnrn密度分析这个概念其实很早就想写了,也有无数同学都问过我,虾神你能不能讲讲那些漂亮的热度图是怎么做的啊?
横看成岭侧成峰,远近高低各不同。 不识庐山真面目,只缘身在此山中。 ——苏轼《题西林壁》 庐山本体就在那个地方,它本身是不会发生任何变化的,但是因为你所处的位置不同,获得的观察结果也不同。

前面我们聊的各种指数,无论是莫兰指数还是P值Z得分,都是整体数据的结论,也就是所谓“全局莫兰指数(Globe Moran’s I)”,也就说,不管我给你多少数据,最后你就吐出一个来给我!这算神马!当然,从名字上来看,全局数据嘛,有一个给你就不错了。实际上作为我们玩GIS的人,最喜欢的就是出一张花花绿绿的地图,比如这样的:nnn或者是这样的:n n所以我们更希望的是将我们输入的数据,标示出
写到这一章,空间统计系列的内容已经写了七章了,前面的所有内容包括了空间统计的几个基本理论基础,如空间自相关、空间异质性、莫兰指数、空间关系概念化以及他们之间的量化度量方式P值和Z得分等,那么空间统计学与经典统计学在理论上的不同点,就说得差不多了。

昨天我们简单的讲了R语言如何对点数据进行分析,今天继续把这个内容说法,其实R语言是非常强大的,他的强大之处,可能超出了你的想象的。rn rn不过R语言也有缺点,最大的缺点就是所有的一切分析过程,都要通过敲命令的方式来实现,对于推广了超过10年的鼠标这种喜闻乐见的标准电脑外设来说,全部采用文本模式进行交互仿佛已经是远古时期的标志一样(不过很多电视剧里面,电脑高手的表现都是在键盘上运指如飞,他们从来不
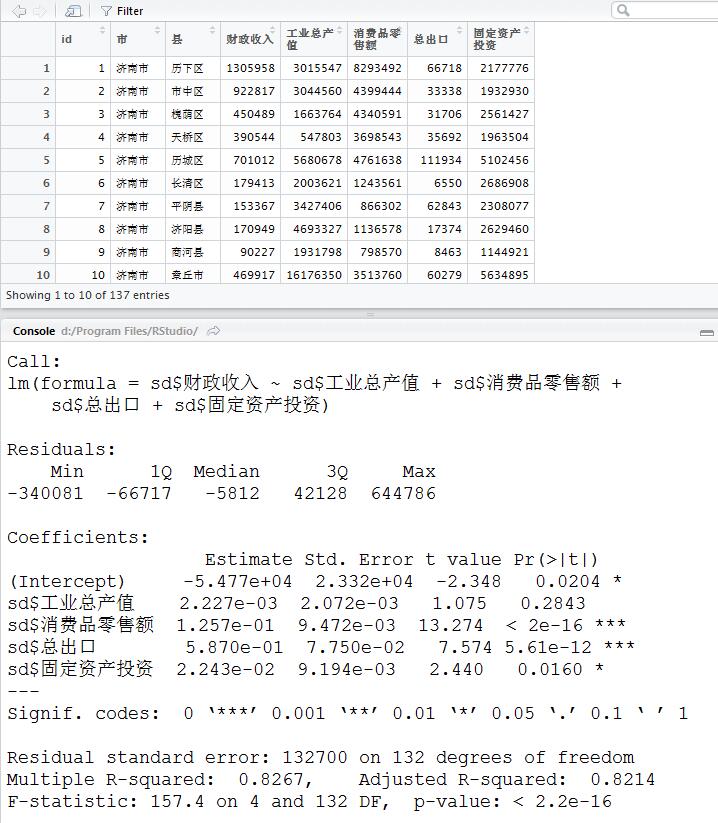
nn不过大家放心啦,作为微信平台里面专门讲空间分析和空间统计的公众号:虾神daxialu,老夫是不会让这种事情发生的……所以今天虽然还是讲回归分析,那么我也要弄成带有空间数据的回归可视化。nn首先,还是用山东的数据吧……首先挑选了五
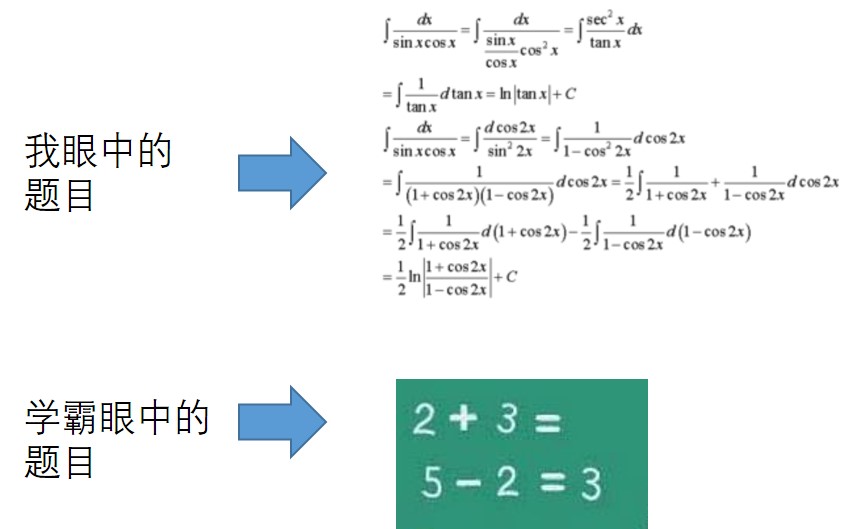
还记得a long long time ago 的青葱岁月……作为学渣的虾神最怕的就是各种(不擅长)的考试,虾神读书时候有个习惯,就拿到试卷之后,第一时间会把试卷翻到最后一页,去看最后一道大题。然后以最后一题来评判整个试卷的难度——具体的评判方法就是最后一题会不会做,如果会,说明这次考试及格应该木问题了,要是不会做,那么回去竹笋炒肉跑不掉了……但是,大部分时候,同一份试卷,不同的梦想:从虾神个人的…

地理加权回归写到这一章,一共是十章了,实际上从回归分析开始,写回归相关的博客一共写了接近20章(其中回归分析五章,番外四章,加上地理回归十章(包括这一篇))。rnrn这一章名为完结篇,实际上应该在标题上加上第一季完结篇……因为后面可能在哪天想起来的时候,在写个三五篇,不过到时候就作为番外篇了。rnrn最后一篇主要的内容就是GWR的扩展分析:莫兰指数的验证。rnrnGWR的结果解读里面,最重要的指标

白话空间统计系列断了好久了……虽然写了很多其他的文章,但是有同学问,还是系列性的文章效果比较好,当然这些文章大部分都能分开来读,没有啥前后联系,但是系列文章最大的特点就是能够形成知识体系,无论是对于写的,还是对于读的,都有很大的好处。nn好了,继续写密度分析。密度分析是我写的白话空间统计里面最长的单篇了,正剧写到这里是第四篇,番外写了两篇,但是预计起码还有好几篇才能写完,有时候想,干脆就直接叫

nn讲到带宽这个词,实际上如果一直跟的同学,应该很熟悉了,我在《白话空间统计第二十
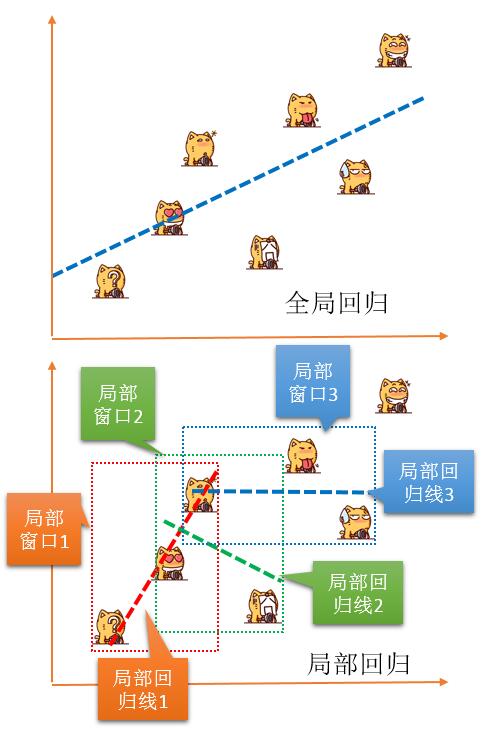
如果说,空间统计有别于经典统计学的两大特征:空间相关性和空间异质性,莫兰指数等可以用来量化空间相关性,那么地理加权回归,就可以用来量化空间异质性。nn在对全局回归问题的改进中,局部回归可以说是最简单的方法,GWR继续应用了局

白话空间统计二十三:回归分析(五)回归应用rnrnrn当然,在说这个之前,先回答大家关心的几个问题。关于回归分析写了四章了,不知道大家是不是和我一样有这样一个问题:这个东东我就看见了一堆概念,这个东西到底是干嘛的……而且:rnrnrnplease!!rnrnrnrnrnrn好吧,今天就用大白话来说说,回归在实际的工程应用中到底是来干嘛。
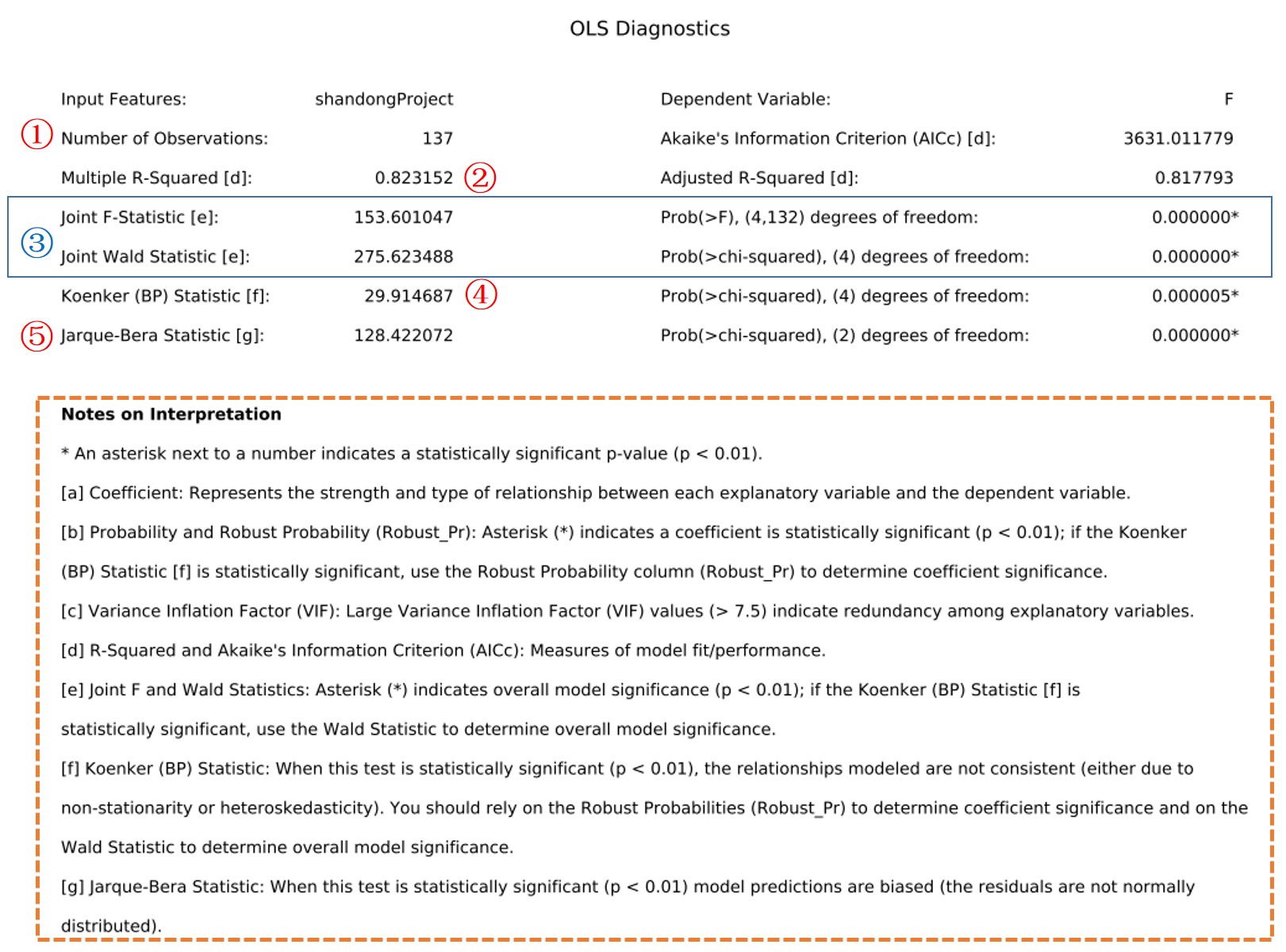
前文再续,书接上一回。rnrn上一节讲到解读OLS的结果第一页的表格,今天从第二页开始:rnrnrn第二页分成两部分,下面这嘚吧嘚吧的一堆英文,实际上就是上面那些信息的解释,英语好的同学实际上看这个文档就可以了,如果懒得看,可以看虾神我嘚吧嘚吧的中文解释,如下:rnrn1、Number of Observations 观测值的数量rn 也就是参与回归的样本数有多少个,我这里是山东全省的区县,
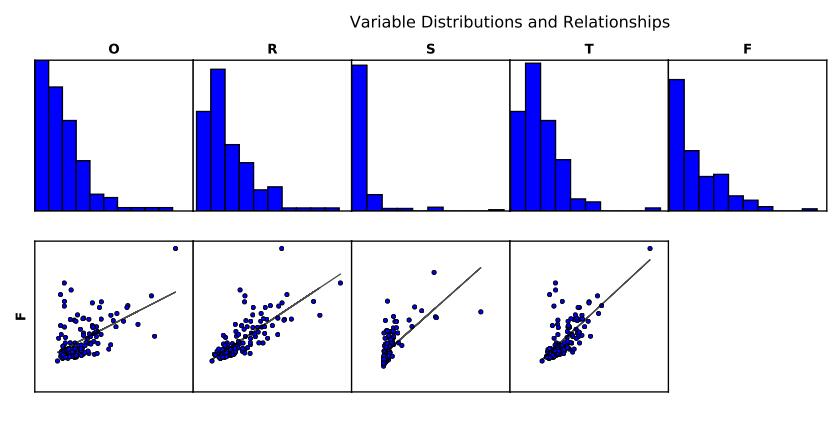
上一节把OLS最重要的一个表格解释完了,下面我们继续来解释OLS结果的其他内容。rnrn结果报告的第三页,是对因变量与自变量相关性的一个检测:rnrnrn会根据每组变量,形成一个自变量的分布柱状图(第一排)以及自变量和因变量组成的散点和回归图(第二排)。rnrn首先要注意的是,OLS对自变量的分布是不是正态的,并不关心,但是如果Jarque-Bera统计量的P值指示,结果出现了偏差(也就是说残差的

我的设想是对空间统计进行科普型的描述,结果写到后面,特别是这几章(准确说是从填中位数中心的算法坑开始),幸好有吴道长果断提醒,说我偏离方向了,我才豁然省悟。再次友情感谢吴道长(PS:吴道长是GIS圈子里面古玩玩的最好的,古玩界里面,GIS技术最好的综合性人才)。所以从今天开始,我继续把空间统计里面那些绕口的理论

这一篇具体看分析模式工具集中的具体工具,整理这一篇的目的,不是要读者了解每个工具的背后使用了多么高级的算法,运用了多么庞大的公式,而是一起了解这些工具究竟可以为我们研究什么样的空间数据分布模式,当需要探索数据的空间性质时,知道应该如何去应用这些分析工具。 Average Nearest Neighbor平均最近邻工具通过计算每个要素与其最邻近要素之间的距离来计算最近邻比率。如果最近邻比率小于 1,则

我的设想是对空间统计进行科普型的描写叙述,结果写到后面,特别是这几章(准确说是从填中位数中心的算法坑開始),幸好有吴道长果断提醒,说我偏离方向了,我才豁然省悟。再次友情感谢吴道长(PS:吴道长是GIS圈子里面古玩玩的最好的,古玩界里面。GIS技术最好的综合性人才)。所以从今天開始。我继续把空间统计里面那…

首先打个广告,在这个开心的开心,伤心的伤心的节日里面,请大家关爱一下虾神这样的单身狗,没有买卖,就没有杀害……rnrnrn当然,其他时候,能关爱的也尽量关爱一下……rnrnrn好了,文归正传。rnrnrn相似性搜索,说起来似乎很高大上,实际在狭义上,还是基于数值的查询方式,只不过从yes or on的二元方式,扩展到了范围域的包含性查询而已。如下:rnrnrn一般来说,相似性搜索,有六种模式:rn

白话空间统计二十一:密度分析(三)rnrn昨天我们看到的都是一维(单变量平滑)的问题,实际上对于做地理信息的同学来说,这种在一个数轴上展开的各种曲线完全就不符合我们的认知或者审美观嘛……别急,今天开始,我们就把这种抽象的数轴曲线,变成大家喜闻乐见的二维密度图了。

文章目录背景空间分析和空间数据分析地统计分析空间统计分析目的主要内容空间统计分析基本流程空间数据空间统计中的问题空间自相关可变区域单位汇总生态学谬误空间尺度空间非均一性和边界效应空间数据关系空间格局空间数据关系rn背景rn空间分析和空间数据分析rn【概率论】概率论是数理统计的基础,在数理统计中做推断的时候有一个概率性推断rn【数理统计】强调数理,数学原理,有大量的公式证明

支柱的概念就是一旦出问题,整个体系就会轰然崩塌……今天有幸阅读到了中科院于淼老师的文章《作为世界观的统计学》一文,觉得深有感触,作为一个致力于推广空间统计的二流科普写手的虾神,觉得突然心潮澎湃,不以此build一系列空间统计的版本,太对不起这么威武的一本书了。所以就有了如下一系列文章。
当一个数据,在A区域内有很强的解释能力,比如在威海市,人口数量对财政收入的变化,可解释性超过了96%,但是同样居于鲁东的青岛,只有1%,简直就不能用不显著来形容。这种在不同区域具有不同性质的情况,就是在空间分析里面无所不在的空间异质性了……

前面我们说的都是点数据的分析,今天来说说一个用于分析线要素的算法(工具),就是线性方向平均值(LinearDirectional Mean )。rn rn总所周知,线要素只有两个属性,一个是长度,第二个就是方向,而对于人类的认知来说,对方向的重要性丝毫不亚于位置的重要性。rn rn对线数据进行统计的时候,首先就是了解他们的方向,如果只有一条线段,那么方向当然就不用统计了。但是如果线段数据非常多的时

遇上瓶颈……所以进来更新稍微有点慢了……大家见谅rnrnrnrnrn点数据的密度计算,是一个很常用的分析方式,在计算密度的时候,最令人头痛的是如何去确定密度的距离,也就是密度收集区域的半径,那么从这句话看,也就知道我们这篇文章是干嘛的了。rnrnrn rn距离,又见距离!rn rn不同的情况下,分析空间数据对使用的距离是非常敏感的。对于不同的分析,使用的距离也是不同的。比如你要计算人的活动区域热点

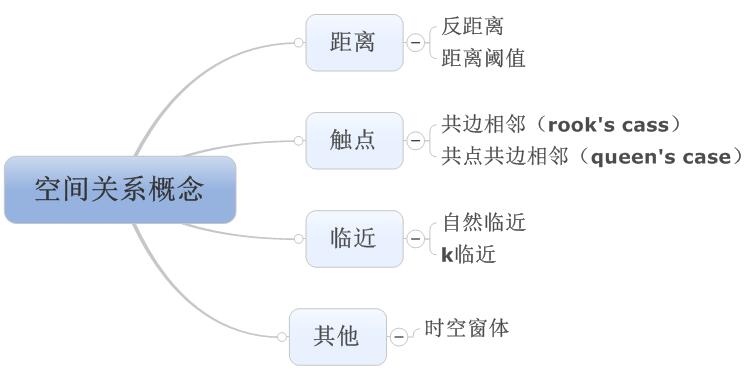
空间关系的概念化(中)rn rn上文说的两种空间关系概念化虽然是最常用,但是总给人一种简单粗暴的感觉,所以业界和学术界由搞出了各种各样的空间关系概念化的模型。rn rn首先,就是把两种最简单的概念化给组合起来了,就是下面这种所谓的“无差别区域”法。rn rn无差别的区域(Zone of indifference)rn rn这个名词和翻译,总是让人感觉到怪怪的,但是实际上确很简单,其的意思就是“在一
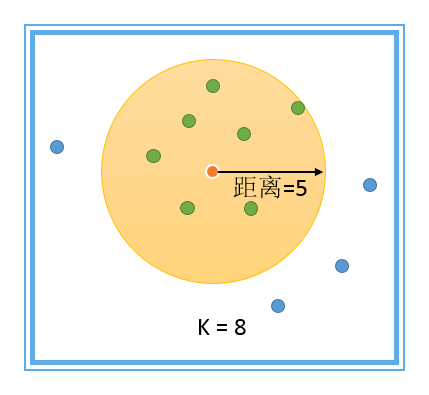
空间关系的概念化,在ArcGIS中,一共是有7种。前面我们说了反距离、距离范围、无差别区域和面邻接四种,后面还有三种今天一并说完。rn rn后面的几种,其实也都是在前面的那些“简单粗暴”的模型中发展而来的,正所谓“大道至简”一点也没错。rn rn rn五、Krn最近相邻要素rn rn所谓的K最近相邻,就是指在一定的范围内,都算相邻的要素,这个概念是“距离范围”模型改良之后生成的。距离范围是以一定距

前文再续,书接上一回。n nAnselinLocal Moran’s I作为细粒度的空间统计工具神器,在ArcGIS里面自然也是提供了相应的工具的,这个工具就直接叫做“聚类和异常值分析”(Cluster and Outlie Analysis(Anselin Local Moransn I))。n n在后面的括号里面保留了以老帅哥Anselin教授命名的算法的名称,不管中英文都有,说明了

通过得到的 z 得分和 p 值,我们可以知道高值或低值要素在空间上发生聚类的位置。但是这个工具的工作方式有些特殊:它查看邻近要素环境中的每一个要素。高值要素往往容易引起注意,但可能不是具有显著统计学意义的热点。要成为具有显著统计需意义的热点,要素应具有高值,且被其他同样具有高值的要素所包围。

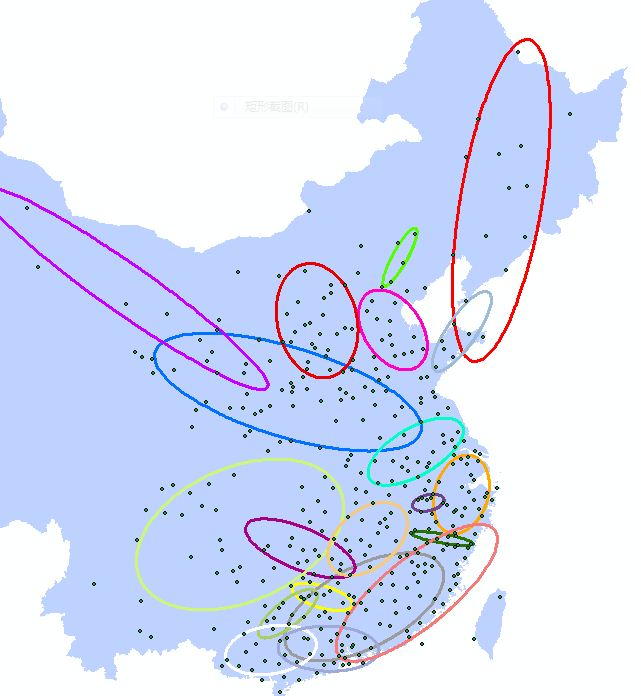
六千多字的大篇……诚意满满啊……nn橘生淮南则为橘,生于淮北则为枳,叶徒相似,其实味不同。所以然者何?水土异也。——《晏子春秋·内篇杂下》nn水土不服、南北差异,(包括地域歧视)是自古以来的一个大命题……正如在(伪)吃货的眼中,中国的地图是这样的:nnn为什么说上面是伪?吃货呢,因为在真?吃货眼中的中国地图,是这样的:nnn这就是具有全局眼(胃)光(口)和局部眼(胃)光(口),
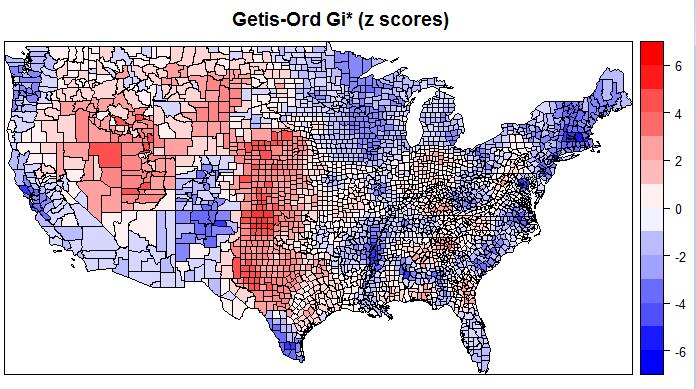
热点和获胜(选票的多少)是没有任何关系的,唯一的关系,就是热点区域表示没有杂质的获胜。用通俗的话来说,就是:在这个区域内,只要任何一个区域获胜,那么就可以推定,周边的区域一样会获胜。同理,冷区也是如此。
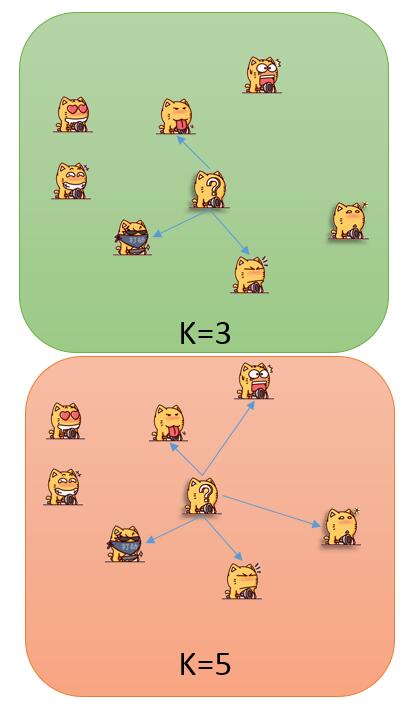
前面几节已经将spdep定义空间关系和转换为空间权重矩阵的方法及原理给大家做了个简单的介绍,本章将spdep中的其他几种空间关系做一个简单介绍,就当资讯存档了。rnrn除去触点连接和距离范围(上一节描述的,触点连接加上范围限制,能够设定在一定距离范围内的要素为临近)以外,还有几种经典的空间关系,比如k临近和自然临近。rnrn因为空间要素的特征,触点连接仅在面要素和线要素之间存储,点要素之间是没有触
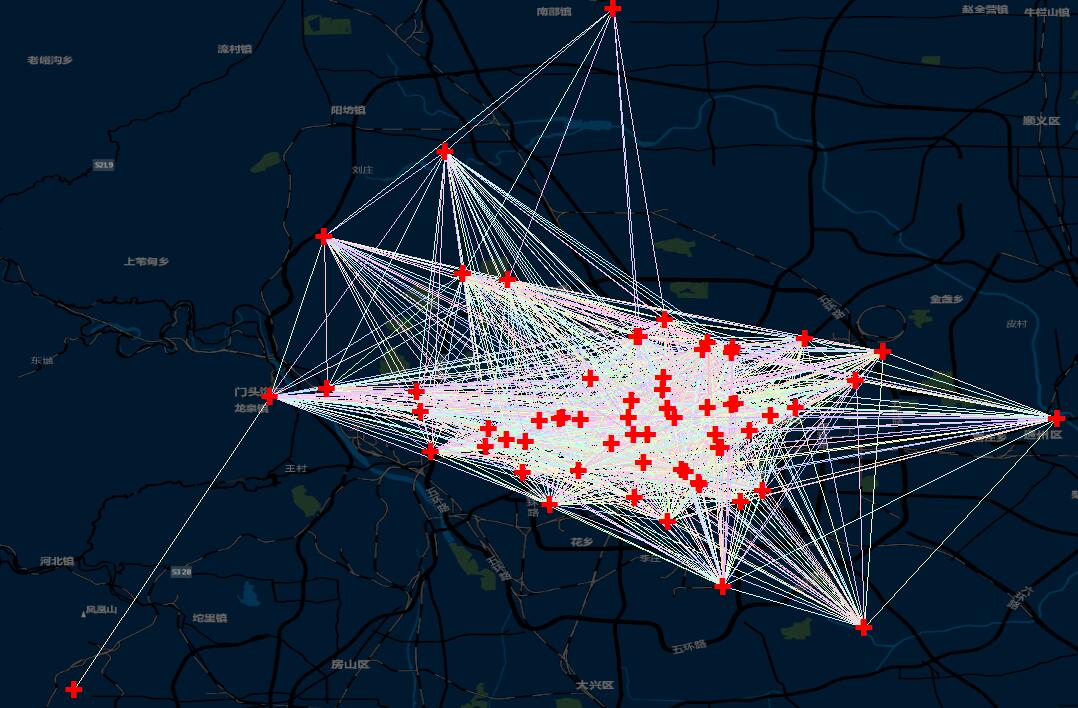
上一回说到使用距离对点数据取临近要素,如果不考虑标准化这个参数,那么每个要素对其临近的就只有相邻和不相邻两种情况。实际上在使用距离为空间关系概念的空间分析里面,经常使用的是反距离这种方法,所谓的反距离,就是取距离的倒数,我们来看看实际上反距离权重的情况是怎么样的。rnrn数据还是上一篇的北京医院的数据,利用反距离参数制作空间权重矩阵且进行连线示意图之后,是这样的:rnrnrn打开临近表之后,可以看