浅入浅出Oracle Spatial GeoRaster 10g影像数据管理(2)
浅入浅出Oracle Spatial GeoRaster 10g影像数据管理(2)——物理存储
1.物理存储方式概要
在上个部分《浅入浅出Oracle Spatial GeoRaster 10g影像数据管理(1)——数据模型》中提到:GeoRaster数据由两部分组成,一是多维像素矩阵,二是GeoRaster元数据。绝大部分的元数据都采用Oracle XMLType类型,以XML文档的形式存储。元数据的格式由GeoRaster元数据XML schema决定。这里说“绝大部分”说明还有“逍遥法外”的元数据。不错,那就是每个GeoRaster对象的空间范围(或地理范围,spatial extent or footprint)。这个重要的属性并没有和其它元数据一起本分的呆在XML文档中,而是单独出来作为了GeoRaster对象的一部分,并且与剩下的其它元数据的集合(就是那个XML文档)相并列。
还是在上个部分,我们还提到对栅格数据这种海量数据集进行处理的基本策略就是“分而治之”,所以对原始数据集进行多分辨率分层——也就是著名的“金字塔”——和在各层上进行分块还是少不了的。看到金字塔和分块我就会条件反射似的兴奋,毕竟我硕士阶段的文章就是关于它的,希望已经10g了的Oracle能带给我一些区别于ArcSDE的惊喜。下面的第2节会有关于GeoRaster中金字塔和分块的详细介绍。
GeoRaster把影像数据用两个基本的表(GeoRaster table和Raster data table,RDT)组织起来,并由GeoRaster object将这两个表连接起来。如果把GeoRaster table比作栅格数据(或影像数据,影像图幅)的目录,那么RDT就是目录所指的具体内容,也就是栅格数据的大本营。后面的第3节会对RDT的结构有所介绍。
第4节介绍了GeoRaster引入的blank GeoRaster object和empty GeoRaster object这两个从中文上可能不太好区分的对象,其实它们的用途完全不同。最后会简单小结一下GeoRaster采用的物理存储方式。
下面马上进入金字塔和分块。
2.成熟的策略?陈旧的策略?——“金字塔”+“均匀分块,边缘补零”
对栅格数据这种海量数据集进行分治的策略在传统上一般采用多尺度组织和分块组织——这是那些八股式的学术文章中的提法,通俗的说,就是为原始影像构建分辨率递减的金字塔结构和在每一级金字塔上对栅格数据进行分块。像GeoRaster这种用来构建TB级影像数据库的技术,当然也要提供与传统相对应的策略。
说实话,看过文档之后,感觉挺失望的,但是为了保证这个系列文章前后风格的一致,我还是以原文的口吻把“金字塔”和“均匀分块,边缘补零”这两个基本策略分别介绍一下。
2.1.金字塔(Pyramid)
所谓金字塔,是指这样一组栅格对象,它们具有不同的分辨率和尺寸(而且其分辨率和尺寸一般分别是一个等比数列),但是它们所表示的地理区域是完全一样的,(如果忽略采样时丢弃的像素所带来的误差的话,那么它们应该具有相同的地理范围)是同一块地理区域的不同分辨率的图像。
建立金字塔的顺序一定是“自底向上”的,将原始的,分辨率最高的图像,通过一次次的采样处理而得到一组尺寸越来越小,分辨率越来越低的图像,形成“金字塔”形的一个图像序列。如图1所示:

图1
那么为什么要构建金字塔呢?因为影像的尺寸代表了它的数据量,显然尺寸越小,分辨率越低的影像数据量也越小。而数据量的大小又和读取影像的时间息息相关。特别是在Web应用中,查询窗口大小是固定的,客户端对影像数据的查询请求在绝大多数情况下都不会对应于原始分辨率,而是低于原始分辨率的。那么在这种情况下,如果在影像数据库中没有建塔,那么在处理客户端请求的时候,就不得不每次都要访问原始分辨率的影像,也就是数据量最大的那幅影像,然后取出查询请求中地理范围对应的那部分后,再通过图像处理(比如用GDI+)将其缩小到查询窗口的大小,并传给客户端,这样的处理流程显然效率是很低的。而如果在影像数据库中建立了金字塔结构,那么就相当于在数据库中为前端应用“准备”好了各种不同分辨率的影像数据,这样一来,客户端就可以在这些不同分辨率的数据中“按需所取”了。
基于金字塔结构最典型的应用就是在Web上对地图进行放大(zoom in),开始的时候,显示全图,分辨率很低,此时可能只需读取金字塔塔顶的数据,而随着不断对地图进行放大,所读取的金字塔级别会越来越低,分辨率越来越高,图像中的细节也越来越丰富。而在整个过程中,数据传输量和效率都不会有大的起伏。
GeoRaster文档认为金字塔可以分成两种:一种是分辨率递减的,前面讨论的都是这种类型,还有一种是分辨率递增的。文档说目前GeoRaster只支持第一种,但是我个人觉得第二种,也就是所谓“分辨率递增”的金字塔好像不太可能存在啊,按照我对文档的理解,这种金字塔是“倒置”的,也就是塔尖朝下,塔中的所有级别的尺寸都比原始影像大,分辨率也高,但这可能吗?通过采样降低分辨率很容易,但采样运算是会丢失信息的,也就是说不存在其真正的逆运算,所谓“插值”算法也都是近似的补偿算法。想想也能明白,要是能把一幅低分辨率影像通过某种算法不断“生”出一组分辨率越来越高的影像,那这种算法就NB的能得图灵奖了——只要在卫星上随便绑个10万像素的手机给地球照几张照片就能得到全球任意位置的任意高分辨率的影像——做梦呢吧。
规定金字塔的塔底为0级(level 0),塔底上面任意一级的尺寸都可以通过下面这个公式算出来:
r(n) = (int)(r(0) / 2^n)
c(n) = (int)(c(0) / 2^n)
其中,r(0)和c(0)分别为塔底原始影像的行、列尺寸,或通俗的说,就是原始影像的高和宽,r(n)和c(n)分别为塔中第n级影像的行、列尺寸。
这里我也要补充一点,其实GeoRaster在这里给出的公式只是采样算法的一种情况,即以2为底数进行采样,其实还可以以3为底数、4为底数等等,但以2为底是最常用的。
在极限的情况下,金字塔可以自底向上的建到塔尖上只剩下一个像素为止(但我觉得没有谁会这么干吧,建塔又不是为了好玩……),在这种极限情况下,金字塔的高度为
(int)(log2(a))
其中a = min(原始影像的宽度, 原始影像的高度)
建塔时可以有若干种采样方法可以选择,这里用原文好一些,我就不翻译了:
·Nearest neighbor
·Bilinear interpolation using 4 neightboring cells
·Cubic convolution using 16 neightboring cells
·Average4 using 4 neighboring cells
·Average16 using 16 neightboring cells
2.2.影像数据的分块(Blocking or Tiling)
对影像数据进行分块就是把原始数据机械的切割成一个个的小矩形,在多波段的情况下也可以理解成是一个个的小立方体,这种分块在单波段(层)时可以形象的理解为“剪纸”,而在多波段时可以理解为“切豆腐”。
对影像数据进行分块也是为了提高读取的效率,但更是为了在数据库中存储方便。如果将整幅影像完整的作为一个BLOB字段来存,那么如果需要提取它其中的一小部分,也不得不先要把整个对象全部读出来,这个数据量是相当大的,大到在内存中肯定是放不下,所以还要转移到磁盘上,如果稍有一点数据库的基本知识就应该知道,磁盘I/O是最慢的,各种索引算法的产生就是为了尽量减少磁盘I/O。而现在要对磁盘上这么大的一个数据集进行处理或分析,这效率自然无法让人接受。
因此,将影像数据大卸八块就成为其入库前必须要经历的处理过程。分块后,每个块都会对应一条数据库记录,其中有一个BLOB字段专门用来存储块的二进制内容,还有一些字段用来存储块的元信息,比如有一个SDO_GEOMETRY对象来保存该块的精确的地理范围,等等。对图像这种非结构化数据,现在也只能用BLOB这种类型来存储,说实话,我个人觉得很别扭,我觉得对图像、声音、视频等等这种非结构化的多媒体数据总应该能(当然需要对现有的关系数据库进行某些扩展)找出更好的存储方式。
GeoRaster对分块的大小仍然采用了“整齐划一”的做法,在影像入库的时候就要指定好分块大小,此后的分块操作就按照这个定义好的值进行。块大小中行和列维度上的尺寸,可以是2的任意非负次幂,波段维度的尺寸可以是任意正整数。然而这个需要由用户自己定义的值要适中,不能太小,(虽然理论上可以小到1×1×1,但这样蹂躏计算机不太好吧……,建议最小不要低于4KB,因为4KB是BLOB类型的存储下限),或者大的出奇(单块的最大数据量不能超过4GB),块大小的选择其实是在单个块的数据量与块的总个数之间寻求一个平衡。行、列尺寸比较适当的量一般就是128×128,或者GeoRaster的默认值256×256。
但是这种均匀分块的方法也会有问题,那就是并非所有影像的尺寸都正好是块尺寸的整数倍,那对于切剩下的“边角料”怎么处理呢?分块是沿着各个维度(行、列、波段)的正方向进行的,当分块操作抵达图像边界的时候,GeoRaster称这些“切剩下”的块为“边缘块”(boundary blocks)。GeoRaster会对边缘块进行“补零”处理(padding),把这些边缘块补成和正常块一样的大小,“补零”顾名思义,就是用全零像素作为填充物来把边缘块填满。
分块操作会应用在所有金字塔级别上,根据2.1.节的介绍,金字塔中的每一级都是一幅影像,只是尺寸和分辨率各不相同而已,所以在塔底以上的其它层次,同样使用“均匀分块,边缘补零”,这与塔底原始影像没什么区别。但是在塔顶有点不同,如果塔顶的尺寸小于等于块尺寸的一半,那么就不需要对塔顶块“补零”了。
好了,以上就是“均匀分块,边缘补零”的方法介绍,也不知道说明白没有。
但是GeoRaster在分块方面还是与ArcSDE存在一定差别的。主要就体现在GeoRaster的分块属于“切豆腐”式的,而ArcSDE的分块基本还停留在“剪纸”这个层次上。GeoRaster把波段作为与行、列同等地位的一个维度考虑了进来,并且使分块操作也能应用在这个维度上。同样的,“补零”操作也会在波段维的“边缘块”上发生。通过引入波段维,GeoRaster使得分块从平面扩展到了立体,可以更灵活的处理多波段影像。
举个例子,一幅8波段影像,可以按照(256,256,3)这样的块大小来分块,那么分块后的结果就是:
– block1:波段0,1和2中按行(每行256个像素,每波段256行)扫描的所有像素数据;
– block2:波段3,4和5中按行(每行256个像素,每波段256行)扫描的所有像素数据;
– block3:波段6的第1行前256个像素数据,波段7的第1行256个像素数据,后面是256个0像素值,再后面是波段6的第2行256个像素,波段7的256个像素,再跟着256个0像素……依此类推。
除此以外,GeoRaster在构建金字塔与影像分块上没有什么更新的东西了,可以说是几乎完全使用了传统的策略,难道是这种传统的策略已经没有任何改进的余地了吗?难道这已经成为业界广泛认同的事实上的标准了吗?为什么GeoRaster在这方面与ArcSDE采取的方法几乎是如出一辙呢?为什么他们非要坚持采用“补零”的方法,而不顾它给数据存储带来的巨大冗余和给图幅的无缝拼接带来的种种麻烦呢?在海量影像数据库的建设过程中,怎样构建高效索引结构的研究难道已经走到了尽头?现有方法难道真的已经是那么完美了吗?
这些问题从我的思维深处不断向外喷涌,但却没有个清晰的答案。
3.栅格数据的老巢——Raster Data Table(RDT)
基于前面说的金字塔和分块结构,GeoRaster为栅格数据集和与其关联的元数据提供了SDO_GEORASTER对象;为影像数据的每个块提供了SDO_RASTER对象。
SDO_GEORASTER对象包含了一个地理范围的属性和其它的一些元数据。包含一个或多个SDO_GEORASTER对象的表就叫GeoRaster table。
SDO_RASTER对象包含了块的元信息和块中的像素数据(以BLOB形式存储),用来存储这种对象的表就叫raster data table(RDT)。
GeoRaster table和RDT之间是一对多的关系,也就是说一个RDT中包含的所有块数据一定是源于一张GeoRaster table。每个SDO_GEORASTER对象都具有一对属性:rasterDataTable和rasterID,它们可以唯一确定RDT以及RDT中用来存储GeoRaster对象像素数据的那些行。GeoRaster table和RDT之间的关系可以用下面这张图看得更清楚些: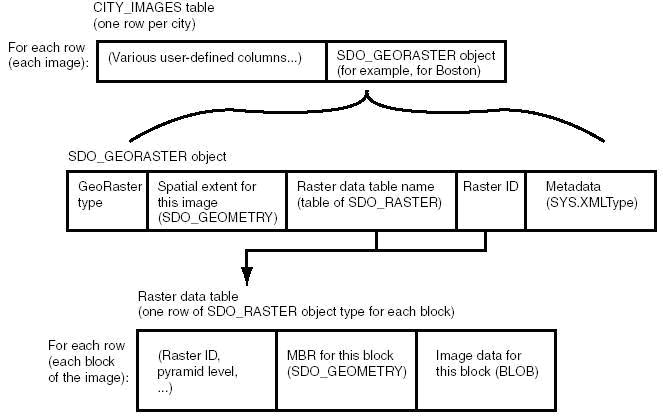
图2
在CITY_IMAGE表中是一组城市的影像,每一行对应一个城市,图中仅以波士顿这行记录为例。该条记录的SDO_GEORASTER对象包含了该幅影像覆盖的地理范围、元数据、rasterID、RDT的名字等若干个部分,在图中用大括号包含表示。RDT中的每一行都包含了块的一些元信息(rasterID,金字塔级别等),块的最小包围矩形(MBR)以及块中的像素数据(用BLOB类型存储)。
RDT作为像素数据的大本营,就是一张SDO_RASTER类型对象的表,它的主键由五个列(rasterID, pyramidLevel, bandBlockNumber, rowBlockNumber, columnBlockNumber)共同组成。RDT中块的大小是可以在后期进行调整的。对于数据量很大的影像,GeoRaster推荐将其像素数据存储在一个单独的RDT中,并按照金字塔级别或块的编号对其进行划分(注:这句话是直译过来的,没太明白,表内能怎么划分?)。RDT的表名在数据库中必须是唯一的。
4.用中文很难区分的兄弟——blank GeoRaster object和empty GeoRaster object
因为用中文不好区分,所以我还是不翻译这两个词了(硬要翻译的话,前面的叫“空白GeoRaster对象”,后面的就叫“空GeoRaster对象”吧)。其实它俩很好区分,说一下区别:
blank GeoRaster object是一种特殊的GeoRaster object,它里面所有像素具有完全相同的值。对这样的GeoRaster对象,就没有必要再分块啊、补零啊什么的了,只要把里面像素具有的那个统一的值存到元数据中的blankCellValue元素中即可。尽管没有为blank GeoRaster object分配实质性的存储空间,但是它在行为上与正常的GeoRaster对象是一样的。GeoRaster提供了SDO_GEOR.createBlank,SDO_GEOR.isBlank,SDO_GEOR.getBlankCellValue这三个函数分别来创建一个blank GeoRaster object,判断一个GeoRaster对象是否为blank GeoRaster object和获取blank GeoRaster object的像素值。
empty GeoRaster object仅仅包含了RDT的表名和一个rasterID。它是通过SDO_GEOR.init函数创建出来的。当你准备将一个GeoRaster object输出的时候,必须先创建一个empty GeoRaster object,用来作为接收输出的对象。我个人理解是当需要对一个GeoRaster object作拷贝操作的时候,需要先“new”出一个空对象来作为拷贝目标,这个对象就是empty GeoRaster object。
5.小结
在利用GeoRaster建立影像数据库的时候,数据入库的处理流程可以简单概括为:先建立金字塔,然后分块,再把这些“金字塔的砖头”组织到GeoRaster table和raster data table(RDT)这两个表中。建表–>插入empty georaster object–>sdo_geor.importFrom导入影像–>sdo_geor.generatePyramid建塔
对于金字塔和分块,GeoRaster采用了与ArcSDE几乎完全一样的成熟的传统策略。尽管我对这种方法存有很多的疑问,但毋庸置疑的是,“金字塔”和“均匀划分,边缘补零”的策略经过若干年的若干套商业软件的实践检验,已经被证明是非常简单和有效的。就算它有不足,那也很正常,任何一种方法都会在特定的条件下显示出不足(要不那么多博士怎么毕业?就是把现有的数据结构和算法改进啊,改进,有几个人能提出革命性的新理论,新思路?)。
然而传统的策略有一个非常大的优点,那就是简单。Keep It Simple and Stupid(KISS)大家应该都不陌生吧,这是UNIX的精髓,其实也可以推广到软件的其它领域,甚至是其它学科。我想,如果我要提出一种新的策略来改进甚至取代“金字塔”+“均匀分块,边缘补零”,那么它必须也要simple and stupid,否则就没有什么特别的价值。但是,谈何容易啊……
最后,用一张图来说明一下典型的基于GeoRaster的影像数据库的物理全貌: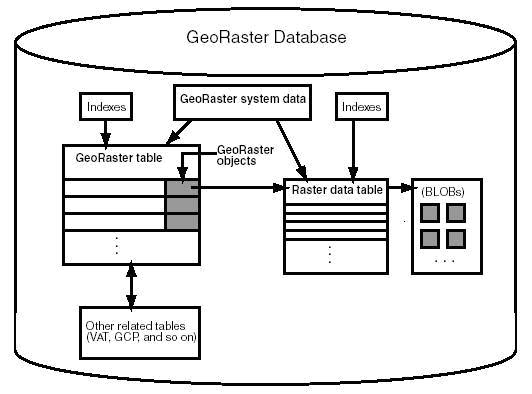
图3
关于这张图还是再多说两句:
1.用于存储影像块中像素数据的BLOBs与RDT是分开的。
2.虽然GeoRaster table和RDT之间是一对多的,但是GeoRaster object和RDT之间的关系是多对多的,也就是说,一个GeoRaster object的影像块数据可以存储在多个RDT中,反过来,一个RDT中也可以存储多个GeoRaster object的影像块数据——但是这些GeoRaster object必须都在同一张GeoRaster table中。
3.GeoRaster system data用于维护GeoRaster table和RDT之间的关系。
4.作用于GeoRaster table和RDT之上的索引包括标准索引和空间索引,这个会在以后具体介绍。
5.一些附加的表,比如值–属性表(value attribute table,VAT),地面控制点表(ground control point,GCP)等等也可以和GeoRaster对象关联。
转载自:https://blog.csdn.net/sosdsh/article/details/1782419