
GeoMesa-Cassandra部署实践
目录
前面我简单介绍了GeoMesa for HBase的部署过程。GeoMesa是一个空间数据引擎SDE,它可以与多种NoSQL数据库(Accumulo、HBase、Cassandra、BigTable等)集成来管理海量的空间数据。本文在上文基础上继续介绍GeoMesa for Cassandra的部署过程,系统环境与之前相同。
1. 安装Cassandra
下载Cassandra安装包,最新版本是3.11:https://cassandra.apache.org/download/
下载完成后将apache-cassandra-3.11.2-bin.tar复制到三台虚拟机的/opt目录下,并在每一台VM执行下面的操作:
解压:$ tar zxvf apache-cassandra-3.11.2-bin.tar
编辑:${CASSANDRA_HOME}/conf/cassandra.yaml, 作如下修改
(1) 修改种子节点seeds,这里使用master作为种子节点:
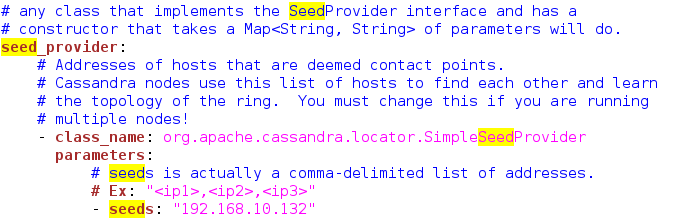
(2)修改监听端口 (改为本地ip):

启动:$ bin/cassandra
使用 $bin/nodetool status 查看集群状态:
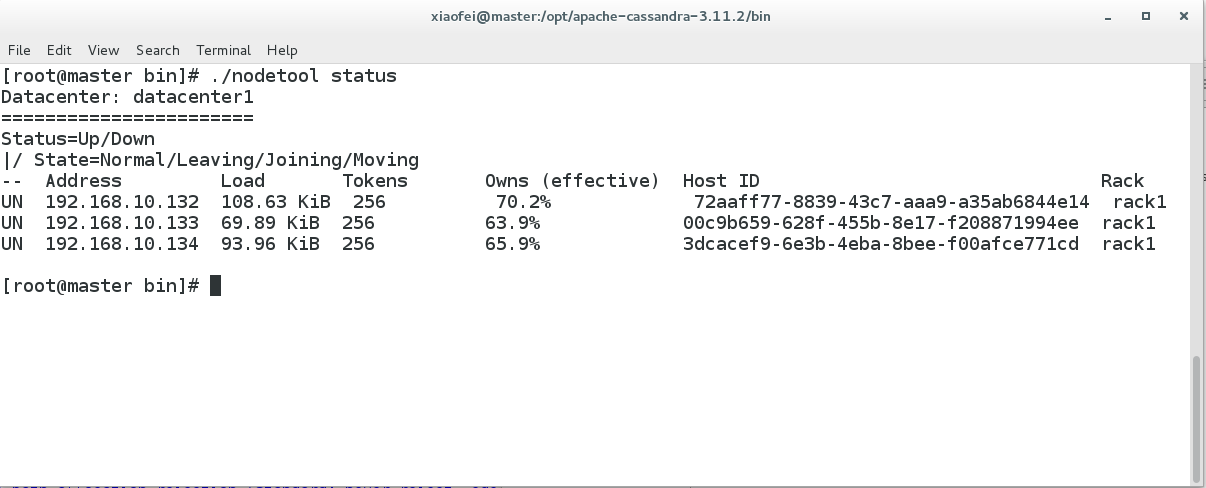
至此Cassandra集群就配置成功了,可以看到相对于HBase的安装,Cassandra集群的安装与配置还是相对简单不少,这也是笔者对Cassandra情有独钟的重要原因之一,美中不足的是Cassandra不能像HBase那样基于Hadoop进行Batch processing。
2. GoeMesa for Cassandra安装
首先在master上配置一下${CASSANDRA_HOME}:
$ gedit .bashrc
加入CASSANDRA_HOME:

运行:$ source .bashrc
………这样就安装成功了,是不是比GeoMesa for HBase简单很多很多!!!
然后打开Cassandra DevCenter,新建Keyspace,命名为geomesa:
CREATE KEYSPACE geomesa
WITH replication = {
'class' : 'SimpleStrategy',
'replication_factor' : 1
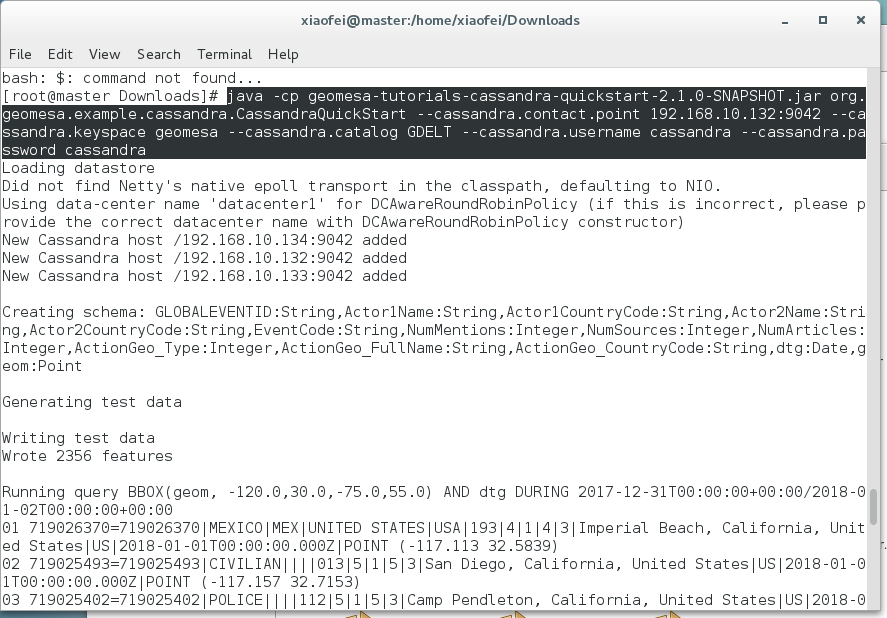
};使用 geomesa-tutorials-cassandra-quickstart-$VERSION.jar进行测试:
$ java -cp geomesa-tutorials-cassandra-quickstart-$VERSION.jar org.geomesa.example.cassandra.CassandraQuickStart
--cassandra.contact.point 192.168.10.132:9042
--cassandra.keyspace geomesa
--cassandra.catalog GDELT
--cassandra.username cassandra
--cassandra.password cassandra看到下列输出,证明安装成功:
打开DevCenter查看表格,可以看到与前面GeoMesa for HBase一样,系统同样创建了5个表格,而且同样创建了Z2/Z3两种空间索引:
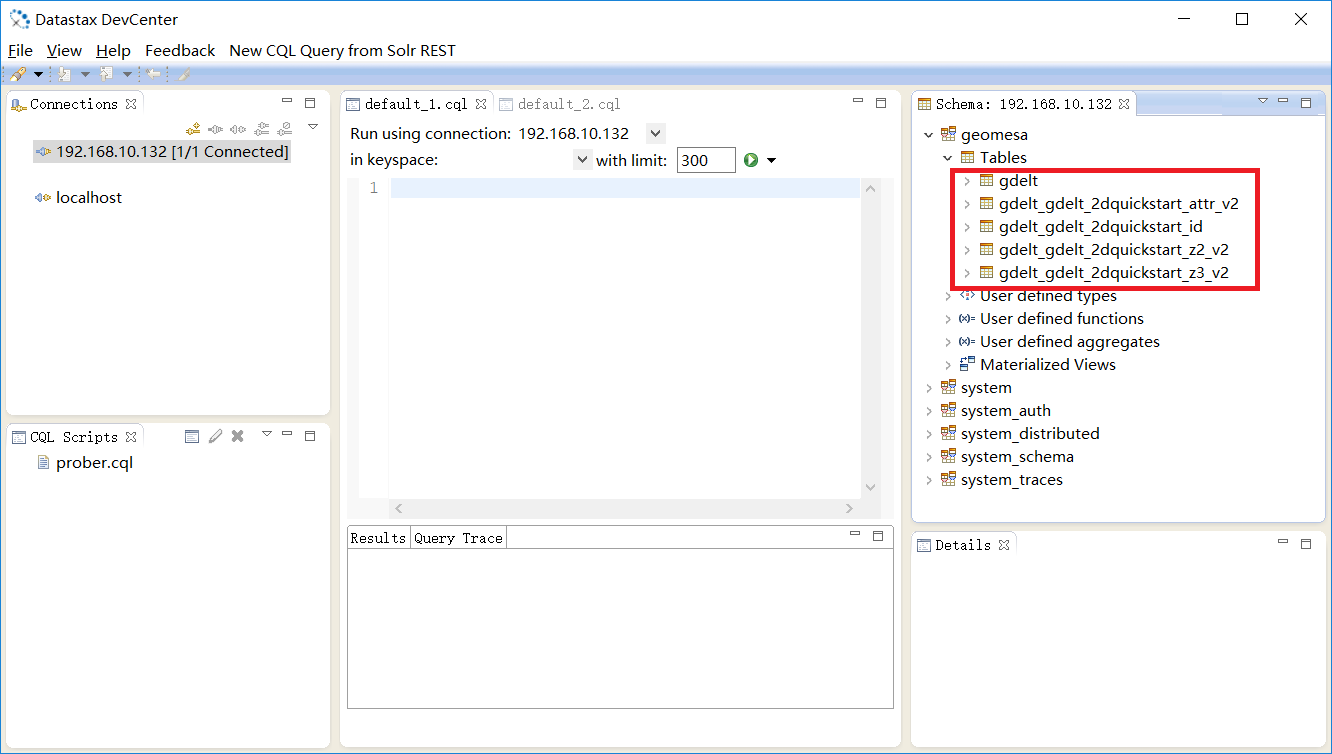
查看gdelt表格,可以看到此表格记录了整个geomesa的数据库所有表格的元数据信息。

查看gdelt_gdelt_2dquickstart_z2_v2表格,可以看到Geomesa索引分为两部分:shard与z。这里需要指出Cassandra的primarykey的结构是由partition key与clustering column key 构成的,前者决定数据分区,后者决定数据排序。这里的shard和z分别对应了分区键和排序键。
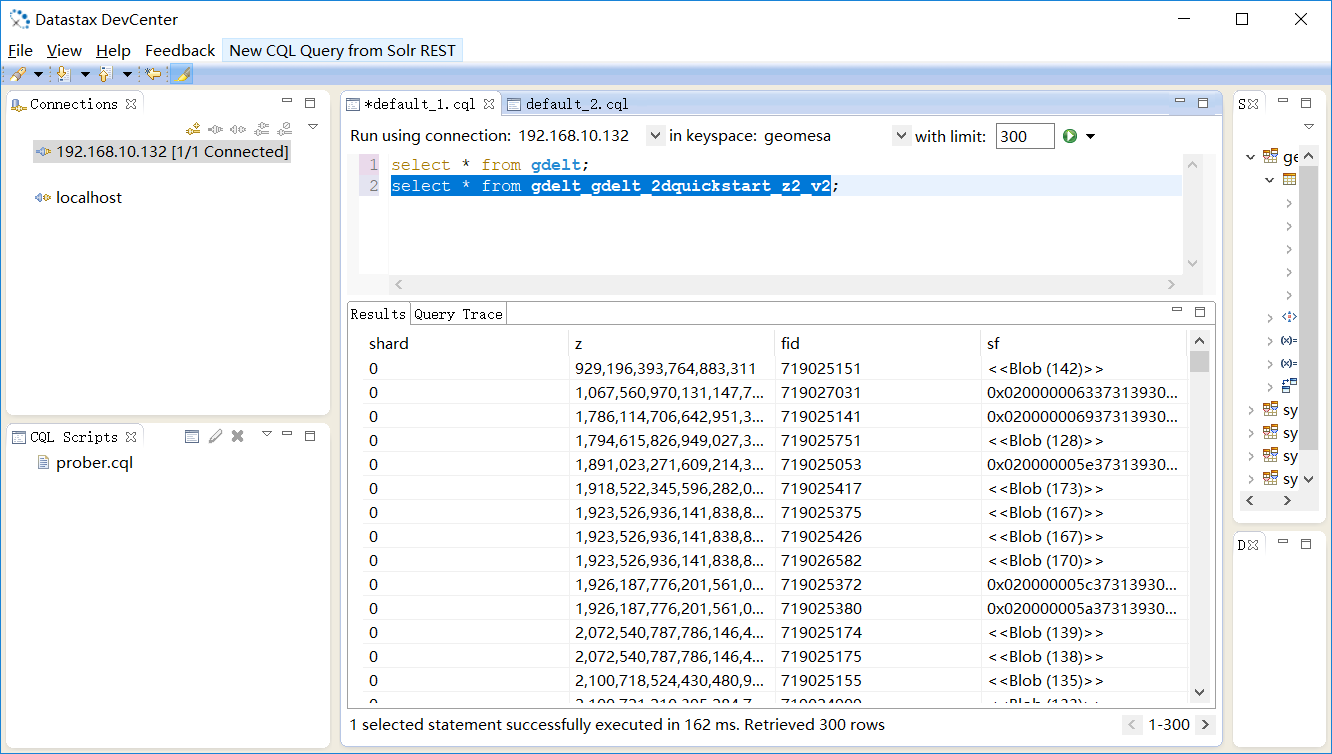
读者可能感觉到GeoMesa for Cassandra的部署与使用确实比HBase要简单,这主要是因为Cassandra去中心化的架构所造成的。当然,孰优孰劣 并不重要,作者目的只是简单尝试在两种最常用的基于列存储的NoSQL数据库上部署GeoMesa,为日后的深入研究做准备,其实GeoMesa官方推荐的是Accumulo数据库,这一点从源代码的复杂程度上也能看出来。
后面我会有专门文章介绍基于Cassandra与HBase两种平台下的GeoMesa的读写效率测试对比。
转载自:https://blog.csdn.net/xiaof22a/article/details/80215756

