空间数据挖掘与空间大数据的探索与思考(四)
讲完了空间统计学和数据中心,我来讲一讲业界很多政府官员以及我对大数据的认识和理解,因为我现在在ESRI中国主要做大数据,他们对大数据有一些什么样的认知呢?
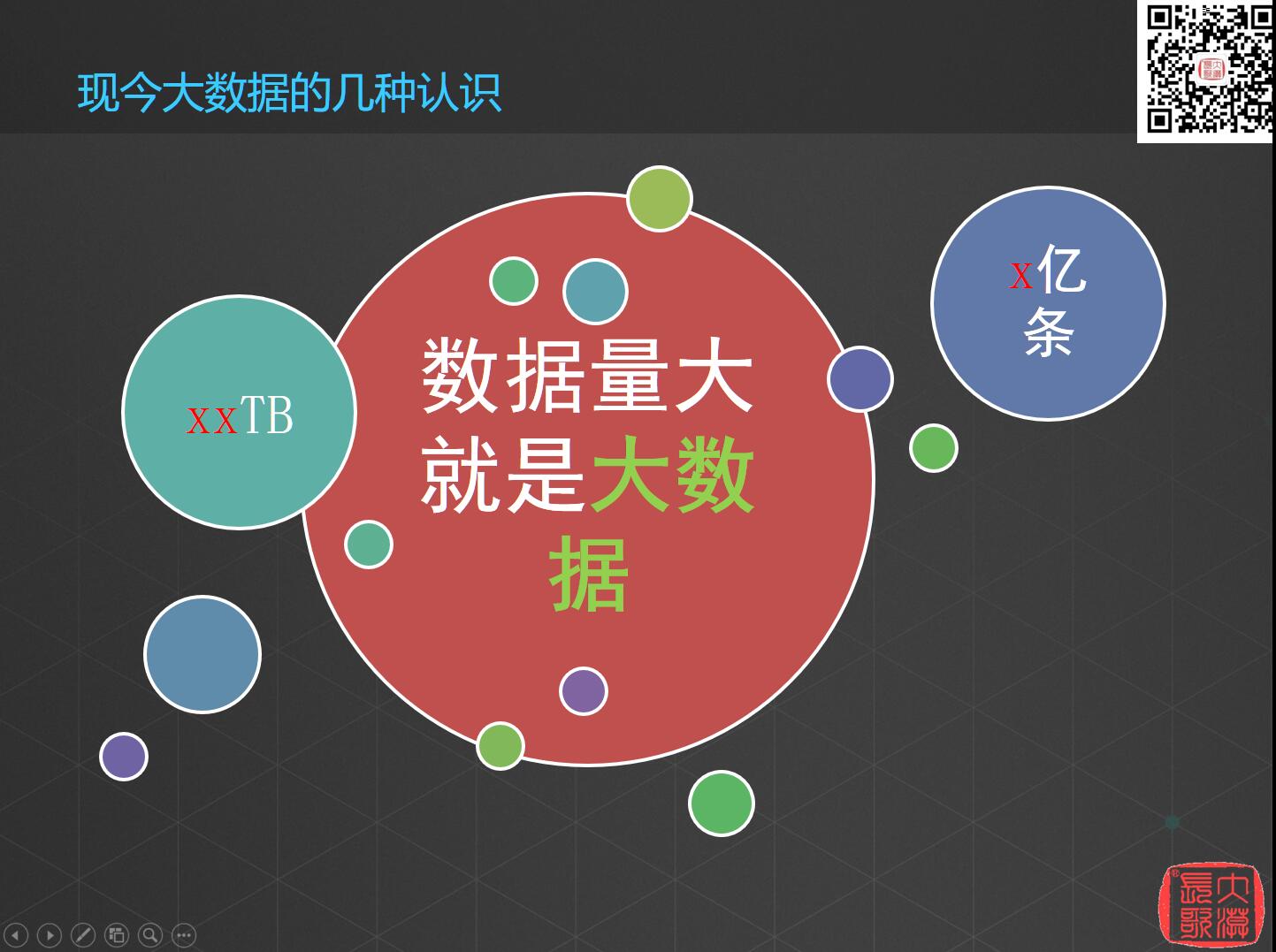
第一种认识,数据量大就是大数据,这是我去交流的时候很多用户提到的,动辄说大数据,就是我们有XX亿条,XXTB数据,所以我们就是大数据。还有说我们要做大数据项目,先要弄够多少多少量的数据,才行。

第二种认识是不用传统数据库就是大数据,很多单位认为大数据不能用传统数据库存储,用了数据库就不能叫大数据。


第三种认识是培训届的一个认识,大家只要在互联网上搜大数据培训,那么马上会跳出来两个名词——Hadoop和Spark,他们认为只要用了Hadoop和Spark就是大数据。


第四种认识是人多力量大——多台机器并行就是大数据,这也是我们一些人的传统思维。

说到人多力量大,实际上我跟一些写小说的朋友们做过一个很有趣的评估,说一个人若有两个人的综合素质,是不是只可能打得过两个人?其实不是的,在格斗界有句话,叫做“高上一点,就高到无边”,如果一个人有普通人的两倍综合素质,实际上一两百个人,他都全部杀完也就是个时间问题。为什么?如果我有你的两倍综合素质,也就说明你所有动作在我这里都是放慢二分之一的慢动作,我所有的力量都是你的两倍,你打在我身上跟挠痒痒一样,我打你一拳你就飞了。依此类推,如果一个人有普通人十倍的力量,用小说上的一句话来说就是可以一人屠军、一人灭国。


所以说,很多台机器并用就是大数据吗?在某些运算的时候,一百台机器一起也不如一台有两倍或者三倍性能的机器。大家知道,中国战斗机的发动机马力不够,有没有任何一个军方设计师会想装一个发动机马力不够,装四个发动机就可以了?我估计没有哪个设计师敢这样做。在现实生活中我经常碰到有些领导提出,我们的数据算一下要两个小时,你能不能在两分钟之内给我算完?要多少台机器你说,给你100台,够不够?我回答是我从北京坐火车到武汉要四个小时,我给你买四张火车票你一个小时把我送到武汉去可以吗?


所以说并行不是万能的。以上是我经常遇到的四个对大数据的错误认知。
实际上对大数据的认知已经超出了科技的范畴,更多地进入一个哲学层面,这里我列出了大数据的11个V(见下图)。我们知道美国人写文章和中国人写八股文很像,中国人很喜欢写一二三四、甲乙丙丁,美国人喜欢写3W4C5H,这11个V也是美国人提出来的。


实际上很早以前,密西根大学有两位学者就提出了大数据与传统数据的不同,他们给出了十个不同的论断,分别是目标、位置、数据结构、数据准备、数据生命周期、衡量、可重复性、成本、内省、分析。我解释一下最简单的位置,这个位置指的是数据存放的位置。谈大数据大家都会谈到微博,大家知道发出的一条微博存放在哪台服务器的哪个硬盘里吗?不知道。按照传统方式,做数据分析必须要知道物理路径。现在要分析新浪微博的存放位置,我们用URL、一个统一资源定位符就可以获取到数据。不需要知道数据的物理存放位置在什么地方,你只需要利用资源定位符获取到它,包括未来的数据中心的概念也是这样,我们通过各种资源定位符获取数据,而不需要知道它存在哪张盘的文件夹下。


(待续未完)
转载自:https://blog.csdn.net/allenlu2008/article/details/79603476