[GIS原理] 10 空间统计分析
目录
在知识传播途中,向涉及到的相关著作权人谨致谢意!
【本章内容】
- 四个概念:空间分析、空间数据分析、地统计分析、空间统计分析
- 为什么要做空间统计?
- 空间自相关怎么回事?有全局和局部的
- 利用空间自相关可以干嘛?空间插值、空间回归
文章目录
背景
空间分析和空间数据分析
【概率论】概率论是数理统计的基础,在数理统计中做推断的时候有一个概率性推断
【数理统计】强调数理,数学原理,有大量的公式证明
【统计学】比数理统计更简单,是直接的应用
【空间分析(Spatial analysis)】偏重于几何的
对空间对象之间关系的分析;通过分析空间坐标的关系得到空间对象的关系
- 狭义的空间分析:就是几何分析,基于空间坐标的分析(点在面内,缓冲区分析)
- 广义空间分析:什么都包,只要跟空间相关的都叫空间分析
【空间数据分析(Spatial data analysis)】偏重于属性的
对具有空间坐标的属性数据的分析
地统计分析
【地统计分析(Geostatistics)】强调是区域化变量和自相关的
以区域化变量为基础,借助变异函数,研究具有随机性和结构性、空间相关性和依赖性的自然现象的一门科学
- 【空间离散化】空间上有几个点,将空间上几个点的属性离散化到整个空间化上
- 【区域化变量】如果这个变量能够区域化(这个点在这,通过某种手段扩展到其他地方,能够把它放在一个区域内来表示),它就可以空间离散化
【应用】针对像矿产、资源、生物群落、地貌等有着特定的地域分布特征而发展的统计学。由于最先在地学领应用,故称为地统计学
【起源】主要理论是法统计学家G.Matheron 创立的,经过不断完善和改进,目前已成为具有坚实理论基础和实用价值的数学工具
空间统计分析
【空间统计分析(Spatial Statistics)】
- 统计分析的主要手段,贯穿于空间分析的各个环节。
- 空间统计分析方法不仅仅限于常规统计方法,还包括基于空间位置和属性的空间分析方法。
【空间数据的统计分析】着重于空间对象和现象的非空间特性的统计分析,中心议题是如何用数学统计模型来描述和模拟空间现象和过程
【数据的空间统计分析】直接从空间对象的空间位置、联系等方面出发,研究具有随机性、结构性,或具有空间相关性和依赖性的自然现象
目的
- 描述事物在空间上的分布特征(怎么分布的,动物、土壤的成分含量、植物是怎么分布的)
【三大分布状态、格局】随机;聚集;规则的 - 分析数据的空间自相关性,空间自相关对空间格局的影响,如何利用这种关系构建模型
【地理】关于地球的道理。跑到月球上,就叫月球学。地理讲的是格局(分布),什么在哪分布,有什么规律
高中:什么在哪,哪有什么。大学:什么东西在哪,为什么在那。利用这些信息可以用于推测预测解释现象,地理信息系统描述这个格局特征是什么,是属于哪种类型。
主要内容
【任务】空间统计分析与经典统计学的内容相交叉。空间统计分析使用统计方法解释空间数据,分析数据在统计上是否是 “典型” 的 或 “期望”
- 空间统计分析重在解释空间数据,不是预测。解释的目标:加深人们对某些问题的认识
- 研究对象是一个总体:这里叫期望。假如你的研究对象是一个采样,谈均值,均值是对期望的一种估计
【主要内容】这是一个整体的流程,先描述,看是否有自相关,如果有就可以用空间自相关的分析来做插值和回归,如果没有自相关后面就不用做了
- 空间统计描述
- 空间自相关分析
- 空间插值
- 空间回归
【关注的问题】
- 有多少
- 怎么分布的
- 是否正常
- 是否有趋势
- 是否自相关
- 怎么从点扩展到区域
【需要研究的问题】
- 格局
- 规则
- 随机
- 集中
- 分布
- 有无规律
空间统计分析基本流程
- 数据测量
- 探索性分析:数据反应了什么规律,是统计分析之上的更高的环节。通过探索的过程得到一个模糊的认识
- 空间统计
- 空间自相关
- 空间插值
- 空间回归
- 空间自相关

空间数据
【问题】空间关系怎么描述?拓扑关系。而空间数据的关系怎么描述?
空间数据=空间几何+属性
【空间统计分析】利用几何信息来研究属性
【空间数据】具有地理坐标的数据
- 地点或定位数据
- 线数据
- 面数据
- 体数据
空间统计中的问题
空间自相关
【空间自相关】空间中相近的样点具有某种相似性,相距较远的样点往往不相似-空间自相关
【解释】距离越近越相似,某个东西某个指标相似–>地理学的第一定律
【引申出新的问题】空间自相关性使得传统的统计学方法不能直接用于分析地理现象的空间特征
- 如果满足空间自相关,就不能用传统的统计学方法
【为什么不能用】传统的统计学方法的基本假设就是独立性和随机性。而自相关与之违背,所以传统的不能用了 - 如果不满足空间自相关,可以用传统的统计学方法
【为什么叫空间自相关?】
- 相关:一个变量x发生变化,另一个变量y随着发生变化–>x,y有相关关系–>y=f(x),两个指标x,y
- 自相关:时间序列t,一个东西的值是v–>以前的数值为v,过去的数据跟现在是有关系的–>历史会影响到现在的数据–>说是在时间序列的自相关,是自身的一套数据,不是外来的–>所以说是自相关v=f(t),一个指标v,随着时间t的变换
- 空间自相关:空间是二维的,在空间上是有相互关系的–>都是一套数据,一个指标v,随着空间(x,y)的变化
【例如】温度temperature随着空间(x,y)的变化,即函数T=f(x,y),就称之为温度的空间自相关
可变区域单位汇总
【解释】汇总的单位不一样,数据的关系会不一样
【举例】按照班来汇总,按照系来汇总,按照学校来汇总,按照省市来汇总–>汇总的单位不一样,收集到的数据结果,这些数据的关系也会不一样
【可变区域单位问题】统计汇总的区域层次不同,统计结果间的关系也就不同
【由汇总单位产生的影响有两个】
- 第一个影响:与分析的空间尺度和汇总效应有关。汇总之后的平均值更接近于回归线,使得散点图的结果更接近于线性,导致相关系数增加。一般通过汇总往往产生更好的拟合结果。
- 第二个影响:是不同汇总方法得到的结果实质上是不同的。
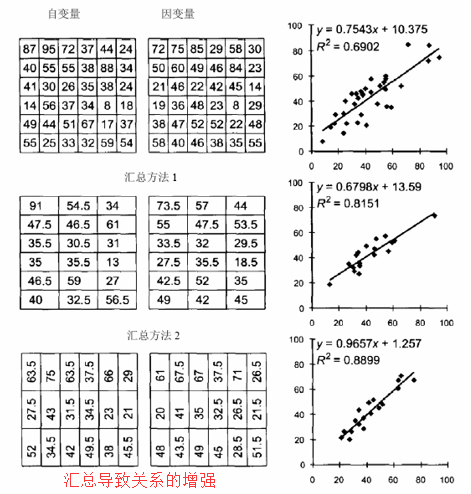
【理解】数据在进行拟合之前先进行汇总–>汇总使数据量变少–>使拟合的效果更好
【原因】因为汇总,导致数据的关系增强,是在汇总层次上的关系,而这种关系可能是虚假的
【解决】研究的基本单位,在基本单位得出来的关系是可靠的
生态学谬误
【生态学谬误】当特定汇总层次的观察值之间的统计关系假定可以接受,并且在更细的层次接受同样关系的时候,产生这个问题
【简单的说】将得到的整体内的关系推论到个体之中,整体和个体不是一个概念,要区分开
【举例】吸烟有害健康(整体)–>你的身体很差(个体)
空间尺度
【比例尺】设定了一个尺度和幅度,你是在这个尺度里面认识世界,看到的细节是不一样的
【空间尺度】
- 不同对象的表现需要的不同尺度
- 在大陆尺度,城市用点来表示。在区域尺度,城市用面来表示。在局部尺度,城市成为复杂的点、线、面和网络的集合体
- 研究对象的空间尺度影响空间分析。因此,应当选定正确的或合适的空间尺度
空间非均一性和边界效应
【空间的不均一性】区分空间分析与传统统计分析的重要标志是空间的不均一性
【边界效应】边界效应是不均一问题的一个特殊类型
【边界举例】行政区划、自然区划
【解释】任何东西都是有边界的,脱离了边界来谈是错误的–>空间的连续性是有边界的,是有条件的
空间数据关系
空间的连续性是有边界的
地理现象的空间连续性是空间属性的最基本性质
空间格局
空间格局类型:规则分布,随机分布,聚集分布
- 大量规则的:往往是人工的、生物学的建筑
- 聚集分布:生物会有聚集的行为,和随机相比,是相对的
- 随机分布
空间数据关系
距离(distance)
空间实体间的直线距离或球面距离
邻接(adjacency)
在指定的距离之下,我们才有一个邻接的概念(这是一个人为的定义)
交互(interaction)
- 距离和邻接的综合:距离越近的交互越强,距离越远的交互越弱
- 出发点:事物与近处的关系更密切
- 数学上:将两个空间实体之间的交互度表示为0(无交互)和1(高度交互)之间的数
近邻(neighborhood)
- 近邻强调的是成员,邻接强调关系
- 特定空间实体的近邻是与该实体邻接的其他空间实体的集合
- 近邻依赖于邻接的定义
本章小结
- 通过统计分析进行描述
- 通过空间探索分析确定异常和总体的趋势
- 通过单要素的空间插值获取未知点的数据
- 通过多要素的空间回归获取未知点的数据
转载自:https://blog.csdn.net/summer_dew/article/details/83050819