白话空间统计十九:热点分析(中)
在前面的话:白话空间统计系列还继续更新,因为这段时间在对《使用R语言进行空间统计》系列进行翻译翻译和编写,所以白话空间统计系列和使用R语言进行空间统计可能会交替出现,给大家的阅读带来的不便,请大家谅解(其实虾神想说的心里话是:你们需要的去翻虾神的历史文章,复习一下前面的内容吧!喔呵呵呵呵!)

前文再续,书接上一回。
继续说热点分析与热度图的问题。
最简单的热度图是没有任何属性要求的,一个点,就是一个值,既没有权重,也没有属性约束。但是实际上,每个点代表什么意义,要对那些属性进行分析,这些都是很重要的。
引用毛博士的名言:凡是不考虑属性的空间分析,都是耍流氓……
当然,热度图因为其对信息的描述简洁明了,为广大人民群众喜闻乐见,所以专业领域的“热点分析”就被很多人脑补成了热度图。
不过正如易经里面的“观”卦所言:童观,小人无咎,君子吝。也就是说幼稚的观点,对于庶民百姓,芸芸众生来说是很合理的,因为这种思想符合他们的身份地位。但是对于有志于教化天下的君子来说,还抱持这样幼稚的观点,就是一种耻辱了。
换成同样喜闻乐见的俗话,就是:外行看热闹,内行看门道。
好了情怀问题到此结束,下面还是回到理工科的路子上来。
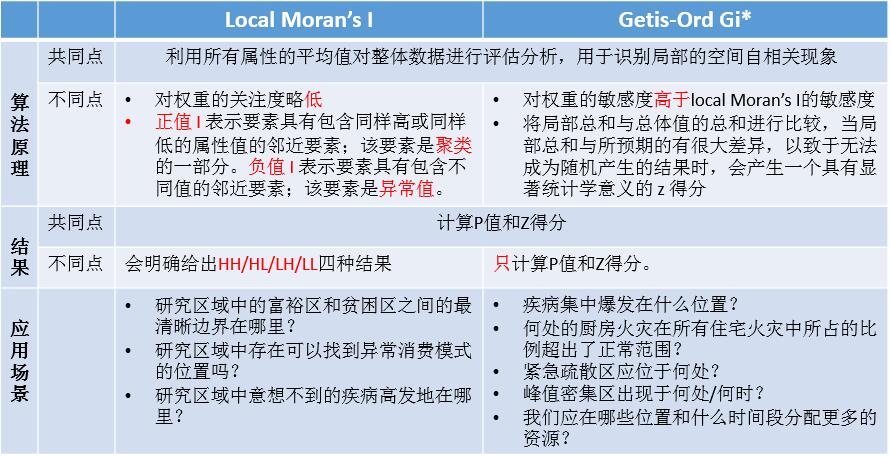
首先热点分析用的算法,依然是Getis-Ord Gi*,看到这个名词是不是觉得很眼熟啊?没错,就是在高/低值聚类的时候说过的那个Getis-Ord General G算法的局部版本。所以称为Getis-Ord Gi*,也就是美国乔治敦大学麦克多诺商学院(McDonough School of Business)的J. Keith Ord和圣地亚哥州立大学地理系的Arthur Getis,即下面这两位老帅哥提出的:

关于Getis-Ord General G算法的具体描述,大家去看白话空间统计十四章里面的内容。
类比一下全局Moran’s I和局部Moran’s I的说法,把名称一换,就可以类比出Getis-Ord General G和Getis-Ord Gi*的不同了,如下图(偷懒一下,直接用老图片了):

Getis-Ord Gi*会给你输入的每一个要素一个值,而不是所有的要素给出一个整体值。
因为其与Local Moran’s I非常相像,所以我下面将他与Local Moran’s I做一个简单的比较:
最后我们来看一个结果(以下结果用R语言编写,脚本和数据在下期放出)

这是2004年美国大选,对各县区对小布什的投票数进行的热点分析,可以看见最高热的区域就是德克萨斯州……这也是老布什和小布什两代总统的家乡,小布什在当选总统之前,于1995年-2000在德州当了5年的州长,必须的老根据地。
还有一个很有意思的地方,就是有钱人多的地方,对小布什的投票都是低值聚类,比如加州,比如纽约……小布什同学当选,难道就是传说中的“得屌丝者得天下”么?
好吧,关于美国选举格局的解读,我们这些技术宅的并不在行。不过最后要强调的一点还是,热点图和热度图完全不相干……如果用热度图的方式来解读这张图的话,小布什怎么可能当选?大家说是吧。
待续未完
转载自:https://blog.csdn.net/allenlu2008/article/details/49942393