Huff 引力模型的工作原理
如果你要开一家零售店,你首先要了解的是“有多少顾客会光顾你的店”
因为根据distance decay ,随着两个 locale 之间的距离增加,它们之间的活动量减少。
为了帮助您解决这个问题,您可以使用哈夫引力模型预测与其他竞争零售店的消费者行为概率。
听起来很复杂?但实际上并没有那么糟糕。让我们逐步了解如何计算哈夫引力模型。
你需要什么
因为 Huff 引力模型假设商店的吸引力取决于它的大小和距离,所以您将需要这 2 个基本数据集来进行此分析:
- 现有零售地点和商店规模
- 人口普查区(尽可能详细)
当然,您将需要一些GIS 软件来计算距离并在地图中显示模型。
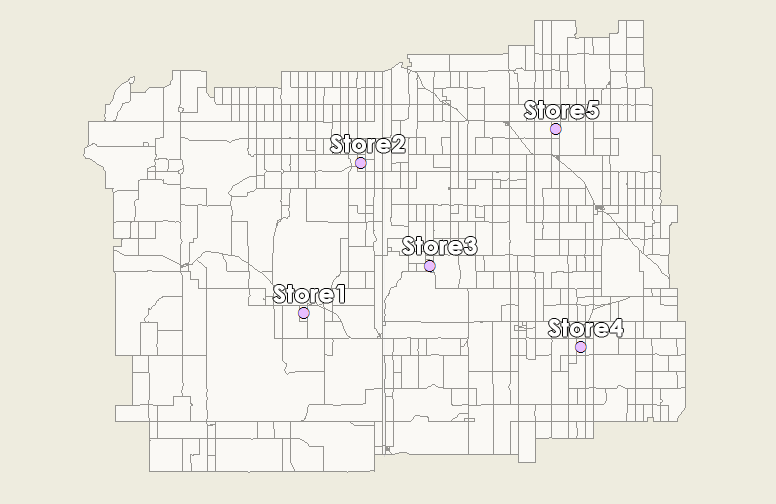
作为说明,这里是我们的五家零售店所在的位置,人口普查区作为底图。
第 1 步。计算从零售店到人口普查区的距离
首先,您将获取人口普查数据并计算从每个人口普查区到每个零售点的距离。在我们的示例中,我们有 5 家零售店和 738 个人口普查区。
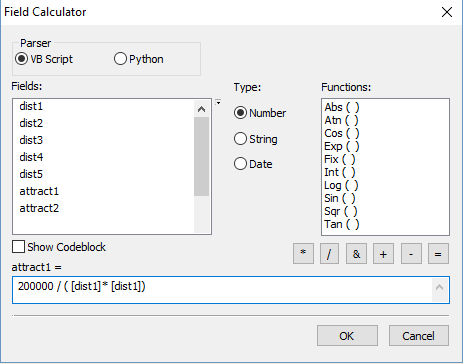
- 在人口普查数据集中添加 5 个距离字段( “dist1”、“dist2”、“dist3”、“dist4”和“dist5” )。
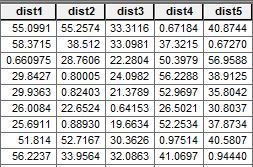
- 计算每个零售点到每个人口普查区的距离。在 ArcGIS 中,您可以使用邻近工具并单独选择每个零售店。
现在,每个人口普查区将在其各自的距离字段中与每个零售店都有距离。例如,商店 1 的距离将在字段'dist1'中)
第 2 步:将吸引力与商店规模和距离相结合
在此步骤中,我们将结合每个零售地点的吸引力。需要澄清的是,吸引力与商店大小(如平方英尺)有关,并且与距离成反比。
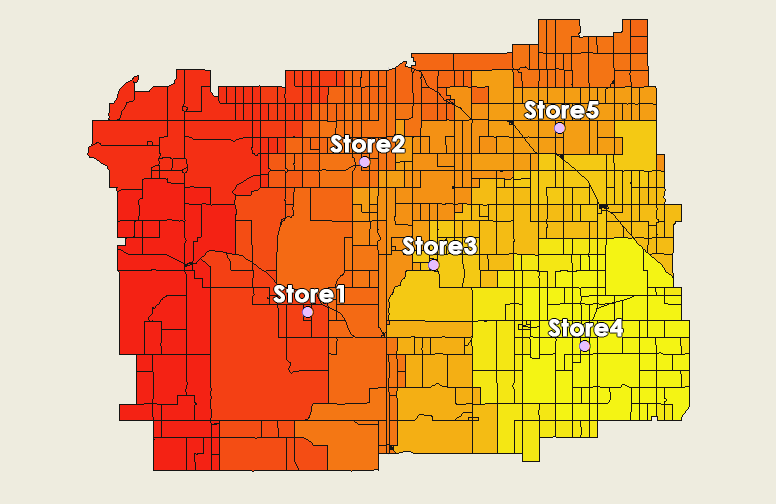
- 在人口普查数据集中,添加 6 个字段来保存每个零售店的吸引力分数和总分( 'attract1'、'attract2'、'attract3'、'attract4'、'attract5' 和 'totattract')
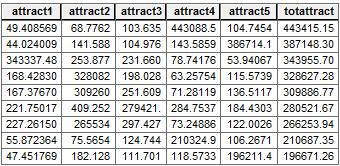
- 吸引力使用距离和零售地点的大小。将零售店的规模除以行驶时间(或距离平方)。例如, “attract1”是零售店 1 的 200,000 平方英尺除以“dist1 2 ” 。
- 最后在“totattract”字段中,汇总所有吸引力分数。 ( “吸引 1”+“吸引 2”+“吸引 3”+“吸引 4”+“吸引 5” )
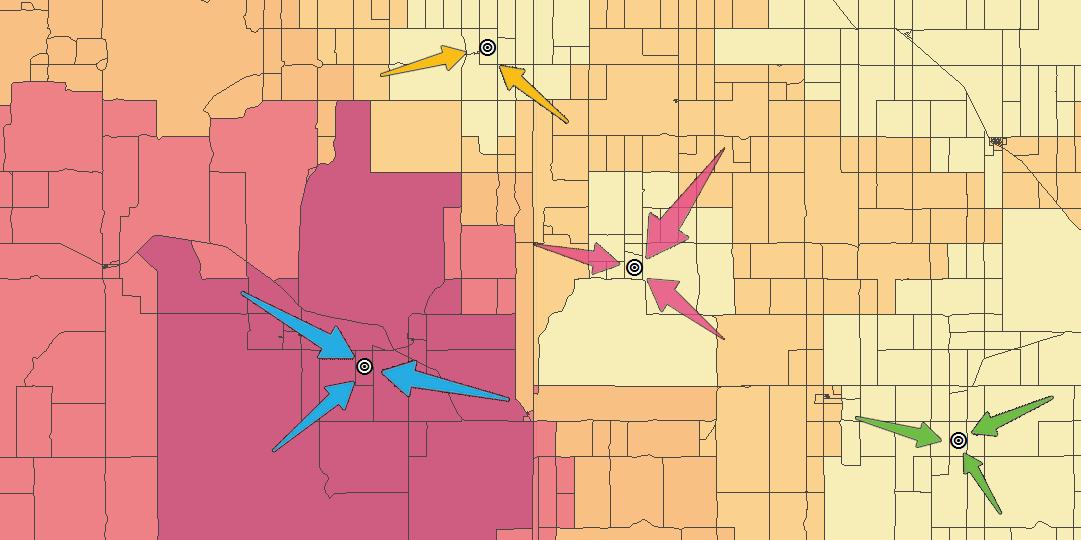
当您将其绘制在地图上时,根据其距离和商店规模,零售店 3 将最吸引该人口普查区。
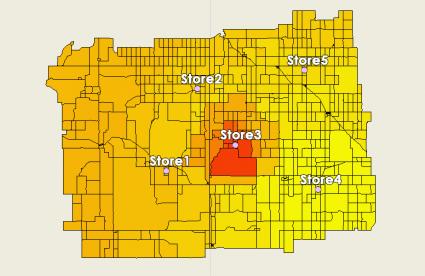
第 3 步。测量每家零售店的市场份额的概率
现在我们有了每家零售店的吸引力得分,我们可以开始计算每个人口普查区购物者最有可能去哪里的概率。
- 为每个零售位置添加百分比字段。 ( “市场份额 1”、“市场份额 2”、“市场份额 3”、“市场份额 4”和“市场份额 5” )
- 将每个零售点的吸引力得分除以总吸引力。 ('attract1' / 'totattract')
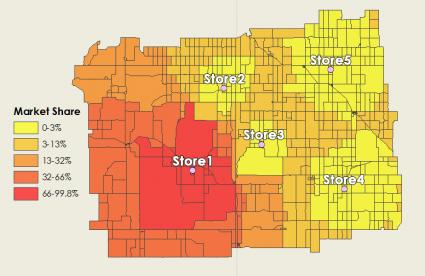
当靠近零售店时,它将占据很大的市场份额——因此红色的价值更高。其他商店所在的位置同样重要,它将占据该市场份额。特别是,黄色补丁表示还有其他零售店更有可能抢占该市场份额。
两个零售店之间距离相等的人口普查区怎么样?
对于这些零售店,市场份额更“有待争夺” ,并且有可能分给任何一家零售店。换句话说,这意味着在这些人口普查区中的概率可能约为 50%。
Huff重力模型公式
Huff 引力模型的公式如下:
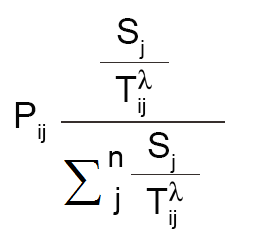
P ij :消费者在i点前往零售地点j的概率
S j : 零售点的大小
T ij :消费者从i点到j点的旅行时间(或距离)
随着零售店规模的增加,消费者光顾零售店的可能性也会增加。同样,当距离增加时,客户光顾该特定商店的可能性会降低(因为它在分母中)。
不要忘记 sigma 表示法仅表示您正在对值求和。如上所示,在第 3 步中,该公式所代表的全部内容是将吸引力得分除以所有零售店的吸引力总和——这应该等于 100%。
总结:哈夫引力模型
如果你打算投入时间和金钱开一家商店,你应该运行哈夫引力模型。
您只需要一点GIS 数据和软件即可开始工作。我们不要忘记合并人口统计数据,例如美国人口普查或Esri 的挂毯市场细分数据。
如今天所示,您需要的两个重要细节是商店的大小和距离以及人口普查区的人口。有了这些变量,您就可以更好地预测消费者行为以及他们光顾您商店的可能性。
如果您想优化商店的选址,请阅读有关选址分配分析的更多信息。