基于Postgres-XL的mpp分布式方案
1简介
Postgres-XL全称为 Postgres eXtensible Lattice,是一个横向扩展的开源数据库集群,是TransLattice公司及其收购数据库技术公司StormDB的产品。
Postgres-XC更适合oltp型应用。
Postgres-XL基于Postgres-XC,更适合olap型应用。
1.1功能特性
license:Mozilla PublicLicense许可,允许将开源代码与闭源代码混在一起使用。
完全的ACID支持。
可横向扩展的关系型数据库(RDBMS)。
支持OLAP应用,采用MPP(Massively Parallel Processing大规模并行处理系统)架构模式。
支持OLTP应用,读写性能可扩展。
集群级别的ACID特性。
多租户安全。
支持分布式Key-Value存储、支持JSON和XML格式。
事务处理与数据分析处理混合型数据库。
支持丰富的SQL语句类型,如关联子查询。
支持绝大部分PostgreSQL的SQL语句。
分布式多版本并发控制(MVCC:Multi-version Concurrency Control)。
支持所有支持PostgresSQL类型的驱动JDBC, ODBC, OLE DB,Python,Ruby,perl DBI,Tcl。
1.2功能不足
需要使用外部机制实现高可用,如pg流复制、Corosync/Pacemaker等。
增删节点/重新分片数据(re-shard)的比较复杂。
数据重分布(redistribution)期间会锁表。
某些外键、唯一性约束功能欠缺。
2Postgres-XL架构

由GTM、GTM-Proxy、Coordinator、Datanode组成。
GTM(Gloable Transaction Manager)负责提供事务的ACID属性;
Datanode负责存储表的数据和本地执行由Coordinator派发的SQL任务;
Coordinator负责处理每个来自Application的SQL任务,并且决定由哪个Datanode执行,然后将任务计划派发给相应的Datanode,根据需要收集结果返还给Application;
GTM通常由一台独立的服务器承担,GTM需要处理来自所有GTM-Proxy或者Coordinator和Datanode的事务请求。
每台机器最好同时配置一个Coordinator、一个Datanode与GTM-Proxy。
每台机器同时配置一个Coordinator和一个Datanode,可以负载均衡,同时降低网络流量。GTM-Proxy会减少GTM的负载,将Coordinator和Datanode上进程的请求和响应聚集到一台机器上,同时会帮助处理GTM失效的情况。
GTM可能会发生单点故障,可以配置一个GTM-Standby节点作为GTM的备用节点。
2.1协调器(Coordinator)
处理客户端连接。
分析查询语句,生成执行计划,并将计划传递给数据节点实际执行。
对数据节点返回的查询中间结果集执行最后处理。
管理事务两阶段提交(2PC)。
存储全局目录(GlobalCatalog)信息。
2.2数据节点(DataNode)
实际存储表和索引数据,数据自动打散分布(或者复制)到集群中各数据节点。
只有协调器连接到数据节点才能可读写。
执行协调器下传的查询,一个查询在所有相关节点上并行查询。
两个数据节点间可建立一对一通讯连接,交换分布式表关联查询的相关信息。
2.3全局事务管理器(GTM)
全局事务管理器(GTM:Global Transaction Manager)
全集群只有一个GTM节点,会有单点故障问题,可以配置StranBy热备节点保证高可用。
通过部署GTM Proxy,解决GTM性能瓶颈。
提供事务间一致性视图。
处理必须的MVCC任务:
transaction IDs 事务ID。
snapshots 数据快照,MVCC使用。
管理全局性数据值:
timestamps 时间戳。
sequences 序列对象。
2.4GTM Proxy

Ø 与协调器(Coordinator)和数据节点(DataNode)在一起运行。
Ø 协调器、数据节点直接与GTM Proxy交互替代GTM,它做为后端与GTM间的中间人。
Ø 将对GTM的请求分组归集,多个请求一次提交给GTM。
Ø 获取transaction ids(XIDs)范围。
Ø 获取数据快照。
2.5数据分布
数据分布有两种模式: 复制表(Replicated Table)与分布表(Distributed Table)
复制表(Replicated Table):每行记录复制到集群中所有的数据节点,每节点一份。
分布表(DistributedTable):记录分片存在不同节点,可用的分片策略方式Hash、Round Robin、Modulo。
2.6高可用性
全局事务管理器采用热备方式。
多个协调器间负载均衡。
数据节点使用流复制,复制数据到备节点。
3安装搭建Postgres-XL
3.1环境列表
操作系统:centos6.5
postgres-xl版本:postgres-xl-9.5r1.3.tar.g
|
主机名 |
ip |
角色 |
用户 |
|
pgxlmaster |
192.168.204.197 |
GTM |
postgres |
|
pgxlnode1 |
192.168.204.198 |
Coordinator、Datanode与GTM-Proxy |
postgres |
|
Pgxlnode2 |
192.168.204.199 |
Coordinator、Datanode与GTM-Proxy |
postgres |
下载:http://www.postgres-xl.org/download/
资料:http://postgres-xc.sourceforge.net/docs/1_1/pgxc-ctl.html
http://files.postgres-xl.org/documentation/install-short.html
3.2设置操作系统环境准备(root用户在pgxlmaster操作)
–配置主机名
hostname
vi /etc/sysconfig/network
vi /etc/hosts
192.168.204.197 pgxlmaster
192.168.204.198 pgxlnode1
192.168.204.199 pgxlnode2
–设置防火墙
chkconfig iptablesoff
service iptables off
–创建用户
useradd postgres
passwd postgres
–安装相关编译pgxl依赖包(我这里)
ncurses-devel
readline-devel
zlib-devel
flex
3.3解压至规划目录
mkdik -p /pgxl
mkdik -p /pgsolf
拷贝postgres-xl-9.5r1.3.tar.gz至/pgsolf
chown -R postgres:postgres /pgxl
chown -R postgres:postgres /pgsolf
tar -zxvf /pgsolf/postgres-xl-9.5r1.3.tar.gz -C /pgsolf/
3.4编译安装
cd /pgsolf/ postgres-xl-9.5r1.3
./configure –prefix=/pgxl
make
make install
3.5配置环境变量
vi /home/postgres/.bash_profile或者vi .bashrc
export PGUSER=postgres
export PGHOME=/pgxl
export LD_LIBRARY_PATH=$PGHOME/lib:$LD_LIBRARY_PATH
export PATH=$HOME/bin:$PGHOME/bin:$PATH
3.6在pgxlnode1、pgxlnode1同样如上操作
3.7在pgxlmaster配置ssh免密码到pgxlnode1、pgxlnode1认证
postgres用户执行:
ssh-keygen -t rsa
cd /home/postgres/.ssh/
catid_rsa.pub>> authorized_keys
root用户执行:chmod 600 /home/postgres/.ssh/authorized_keys
postgres用户执行:
scp /home/postgres/.ssh/authorized_keys postgres@pgxlnode1:/home/postgres/.ssh/
scp /home/postgres/.ssh/authorized_keys postgres@pgxlnode2:/home/postgres/.ssh/
3.8在gtm主机;即pgxlmaster执行安装工具pgxc_ctl
cd /pgsolf/postgres-xl-9.5r1.3/contrib
make
make install
3.9 在pgxlmaster主机配置集群
在/pgxl/bin命令执行pgxc_ctl
PGXC工具中执行prepare 会在/home/postgres/pgxc_ctl下生成pgxc_ctl.conf
配置修改pgxc_ctl.conf文件(重点关注黄色部分,其他默认即可)
|
#!/usr/bin/env bash pgxcInstallDir=$HOME/pgxc pgxcOwner=$USER pgxcUser=$pgxcOwner tmpDir=/tmp localTmpDir=$tmpDir configBackup=n configBackupHost=pgxc-linker configBackupDir=$HOME/pgxc configBackupFile=pgxc_ctl.bak #—- GTM #—- GTM Master ———————————————– gtmName=gtm gtmMasterServer=pgxlmaster gtmMasterPort=20001 gtmMasterDir=$HOME/pgxc/nodes/gtm #—- Configuration — gtmExtraConfig=none gtmMasterSpecificExtraConfig=none #—- GTM Slave ———————————————– gtmSlave=n #是否启用gtmSlave gtmSlaveName=gtmSlave gtmSlaveServer=pgxlnode1 gtmSlavePort=20002 gtmSlaveDir=$HOME/pgxc/nodes/gtm #—- GTM Proxy gtmProxyDir=$HOME/pgxc/nodes/gtm_pxy gtmProxy=y #是否启用gtmProxy gtmProxyNames=(gtm_pxy1 gtm_pxy2) gtmProxyServers=(pgxlnode1 pgxlnode2) gtmProxyPorts=(20001 20001) gtmProxyDirs=($gtmProxyDir $gtmProxyDir) #—- Configuration —- gtmPxyExtraConfig=none gtmPxySpecificExtraConfig=(none none) coordMasterDir=$HOME/pgxc/nodes/coord coordSlaveDir=$HOME/pgxc/nodes/coord_slave coordArchLogDir=$HOME/pgxc/nodes/coord_archlog coordNames=(coord1 coord2) # 名称 coordPorts=(20004 20005) # 端口 poolerPorts=(20010 20011) # Master pooler ports coordPgHbaEntries=(192.168.204.0/24) #coordPgHbaEntries=(::1/128) #—- Master ————- coordMasterServers=(pgxlnode1 pgxlnode2) #主机名 coordMasterDirs=($coordMasterDir $coordMasterDir) coordMaxWALsernder=0 # needed to configure slave. If zero value is specified, coordMaxWALSenders=($coordMaxWALsernder $coordMaxWALsernder) #—- Slave ————- coordSlave=n # 是否启用协调coordSlave coordSlaveSync=y coordSlaveServers=(node07 node08 node09 node06) coordSlavePorts=(20004 20005 20004 20005) coordSlavePoolerPorts=(20010 20011 20010 20011) coordSlaveDirs=($coordSlaveDir $coordSlaveDir $coordSlaveDir $coordSlaveDir) coordArchLogDirs=($coordArchLogDir $coordArchLogDir $coordArchLogDir $coordArchLogDir) cat > $coordExtraConfig <<EOF #================================================ # Added to all the coordinator postgresql.conf # Original: $coordExtraConfig log_destination = ‘stderr’ logging_collector = on log_directory = ‘pg_log’ listen_addresses = ‘*’ max_connections = 100 EOF coordSpecificExtraConfig=(none none) coordExtraPgHba=none coordSpecificExtraPgHba=(none none) #—– Additional Slaves —– coordAdditionalSlaves=n coordAdditionalSlaveSet=(cad1) # configured cad1_Sync=n cad1_Servers=(node08 node09 node06 node07) cad1_dir=$HOME/pgxc/nodes/coord_slave_cad1 cad1_Dirs=($cad1_dir $cad1_dir $cad1_dir $cad1_dir) cad1_ArchLogDir=$HOME/pgxc/nodes/coord_archlog_cad1 cad1_ArchLogDirs=($cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir) #—- Datanodes datanodeMasterDir=$HOME/pgxc/nodes/dn_master datanodeSlaveDir=$HOME/pgxc/nodes/dn_slave datanodeArchLogDir=$HOME/pgxc/nodes/datanode_archlog primaryDatanode=datanode1 # Primary Node. datanodeNames=(datanode1 datanode2) datanodePorts=(20008 20009 ) # Master ports datanodePoolerPorts=(20012 20013) # Master pooler ports datanodePgHbaEntries=(192.168.204.0/24) #—- Master —————- datanodeMasterServers=(pgxlnode1 pgxlnode2) datanodeMasterDirs=($datanodeMasterDir $datanodeMasterDir) datanodeMaxWalSender=0 datanodeMaxWALSenders=($datanodeMaxWalSender $datanodeMaxWalSender) #—- Slave —————– datanodeSlave=n #是否启用datanodeSlave datanodeSlaveServers=(node07 node08 node09 node06) datanodeSlavePorts=(20008 20009 20008 20009) datanodeSlavePoolerPorts=(20012 20013 20012 20013) datanodeSlaveSync=y datanodeSlaveDirs=($datanodeSlaveDir $datanodeSlaveDir $datanodeSlaveDir $datanodeSlaveDir) datanodeArchLogDirs=($datanodeArchLogDir $datanodeArchLogDir $datanodeArchLogDir $datanodeArchLogDir ) # —- Configuration files — datanodeExtraConfig=none datanodeSpecificExtraConfig=(none none ) datanodeExtraPgHba=none datanodeSpecificExtraPgHba=(none none ) #—– Additional Slaves —– datanodeAdditionalSlaves=n # datanodeAdditionalSlaveSet=(dad1 dad2) # configured # dad1_Sync=n # dad1_Servers=(node08 node09 node06 node07) # dad1_dir=$HOME/pgxc/nodes/coord_slave_cad1 # dad1_Dirs=($cad1_dir $cad1_dir $cad1_dir $cad1_dir) # dad1_ArchLogDir=$HOME/pgxc/nodes/coord_archlog_cad1 #dad1_ArchLogDirs=($cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir) #—- WAL archives walArchive=n walArchiveSet=(war1 war2) war1_source=(master) wal1_source=(slave) wal1_source=(additiona_coordinator_slave_set additional_datanode_slave_set) war1_host=node10 war1_backupdir=$HOME/pgxc/backup_war1 wal2_source=(master) war2_host=node11 war2_backupdir=$HOME/pgxc/backup_war2 #=============<< End of future extension demonistration >> |
修改好之后
在/pgxl/bin命令执行pgxc_ctl后PGXC工具中执行
init all
等待初始化成功。
3.10初步使用
stop|start all
psql -h (pgxlnode1或者pgxlnode2) -p(20004或者20005)–通过协调节点可读写
psql -h (pgxlnode1或者pgxlnode2) -p(20008或者20009)–通过数据节点只可读
postgres=# select *from pgxc_node;
创建表语法
CREATE TABLE test(…)
DISTRIBUTE BY
HASH(col)|MODULO(col)|ROUNDROBIN|REPLICATION
TONODE(nodename1,nodename2…)
如果DISTRIBUTEBY 后面是REPLICATION,则是复制模式,其余则是分片模式,HASH指的是按照指定列的哈希值分布数据,MODULO指的是按照指定列的取摩运算分布数据,ROUNDROBIN指的是按照轮询的方式分布数据。TO NODE指定了数据分布的节点范围,如果没有指定则默认所有数据节点参与数据分布。如果没有指定分布模式,即使用普通的CREATE TABLE语句,PGXL会默认采用复制模式将数据复制到所有数据节点。
通过协调节点操作:
psql -h pgxlnode1 -p 20004
CREATE TABLE test(id int primary key, name varchar(10)) DISTRIBUTE BY HASH(id) TO NODE(datanode1,datanode2);
insert into test select generate_series(1,1000),’test’||generate_series(1,1000);
postgres=#select count(*) from test;
count
——-
1000
(1 row)
通过数据节点操作:

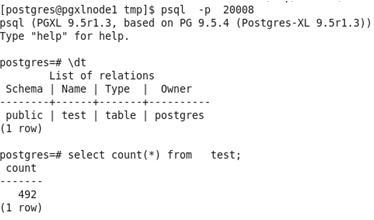
完成。
转载自:https://blog.csdn.net/sunziyue/article/details/53189304