
PostGIS快速导入大量点空间数据及最近邻要素跨表查询
目录
PostGIS快速导入空间数据及最近邻要素查询
其实实现的就是两个功能,一个是导入坐标点数据,一个是为坐标点空间数据跨表找到它最近邻的要素,功能上说多难其实也不是很难,关键是摊上了一个数据量大的特点,为了尽可能地节省时间,光是数据导入方式我就研究了三种。
- 环境:centos7.1,Python3.5.2,Postgres10.3
- 处理器双E5,内存128G
PostGIS快速导入空间数据的方法
之前写过一篇“利用geopandas包对PostGIS数据库插入地理空间数据及性能对比”的博客,后来发现了更快的导入方法,没有使用geopandas包而是用的Postgres从文件直接导入数据库的copy功能,其实之前也看到过这个功能,但是没有深入了解,因为我当时担心copy功能无法将空间属性这一特点给完整地导入进去,现在出乎意料地发现Postgres真是功能强大,良心数据库。
1.准备数据
假设你的数据是以下格式的txt文件:
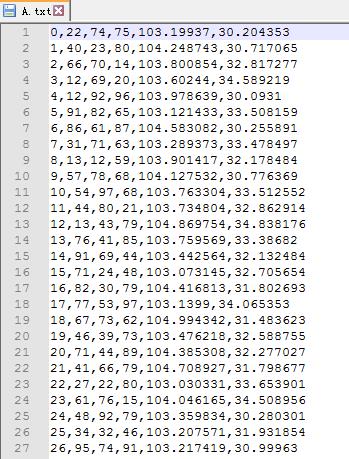
包括一个index列作为点的编号列,三个value属性列,以及lon和lat的经纬度列,使用逗号分隔。
首先需要将txt文件中的经纬度转换成如下文本(这里假设你的坐标系是4326的):
lon,lat ——>SRID=4326;POINT(lon lat)
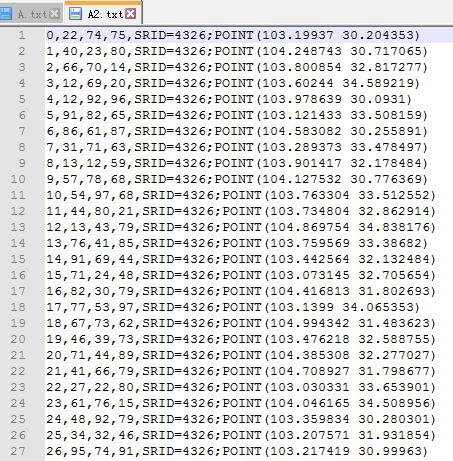
2.导入数据库
这里可以使用的SQL语言,首先需要创建一个数据表:
CREATE TABLE {tablename}(
index bigint,
value1 bigint,
value2 bigint,
value3 bigint,
geom geometry(Point, 4326)
);{tablename}是该表在数据库中的名称,作为参数传递。
然后使用copy功能导入数据库:
COPY {tablename} FROM '{path}' delimiter ',';{path}是txt数据文件的路径,在此创建两个表,一个有10000条点数据,一个有1000条点数据,之后我们可以看到PostGIS数据库内有两个分别名为a、b的数据表:
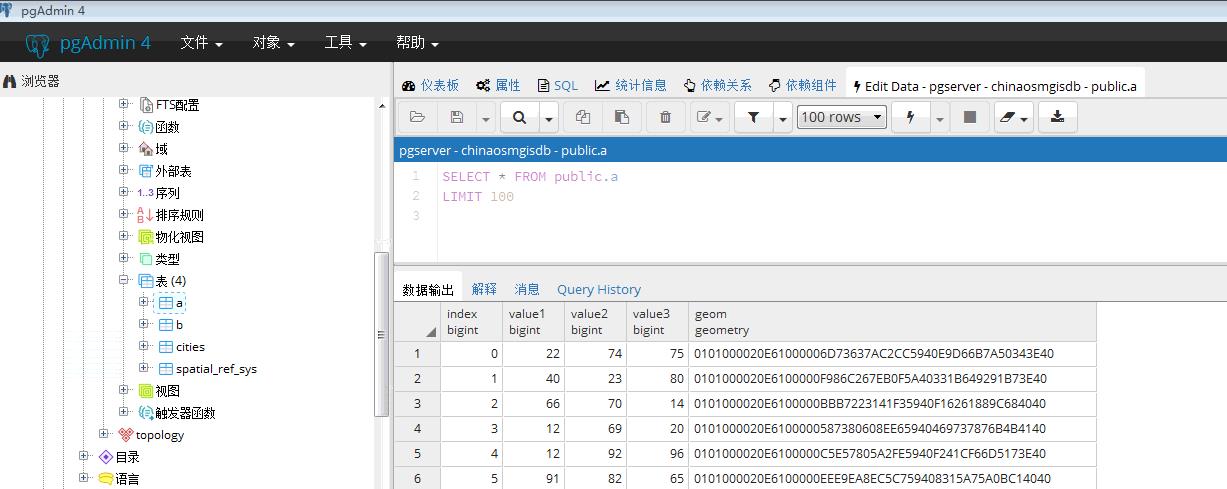
copy方式导入五千多万条点数据需要十多分钟,至于具体使用什么工具去实现SQL语言,可以用psql命令行,也可以使用pgAdmin可视化窗口、Python语言等等。
最近邻要素查询
这里说的最近邻要素查询并不是在A表里面为每一个点查询属于A表的最近邻要素,而是为A表里的每一个点查询属于另一个空间数据表B的最近邻要素,是跨表查询最近邻。
需要实现的功能是将A表中点数据的index与B表中最近邻要素index对应起来生成新的表。
代码如下:
SELECT * into c
FROM
(
SELECT p.index, b.id AS b_index
FROM a p
CROSS JOIN LATERAL (
SELECT r.index AS id, r.geom AS geom
FROM b r
ORDER BY r.geom <-> p.geom
LIMIT 1
)b
)AS table1CROSS JOIN LATERAL功能可以过滤限制结果,比如LIMIT 1就是最近的一个,改为LIMIT 2就能获取到最近的两个,<->操作符能够提升近邻排序的性能。
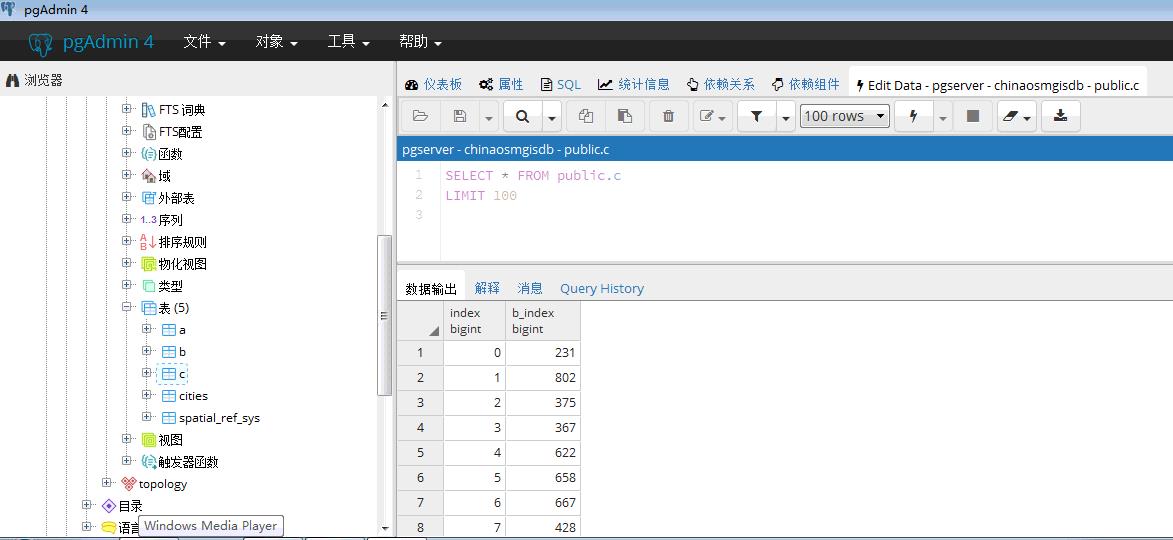
可以看到数据库中多出来的c表就是我们想要的结果:
完整代码
password是数据库用户postgres的密码,dbname是数据库的名字,由于各人环境安装不同,代码仅供参考
# encoding=utf-8
import pandas as pd
import datetime
import numpy as np
from sqlalchemy import *
def create_data(dataname,size=10000):
df1 = pd.DataFrame()
df1['value1'] = np.random.randint(10, 99, size=size)
df1['value2'] = np.random.randint(10, 99, size=size)
df1['value3'] = np.random.randint(10, 99, size=size)
df1['lon'] = np.random.randint(103000000, 105000000, size=size) / 1000000
df1['lat'] = np.random.randint(30000000, 35000000, size=size) / 1000000
df1['lat'] = df1['lat'].round(6)
df1['lon'] = df1['lon'].round(6)
df1.to_csv(dataname+'.txt', header=None)
df1['lat'] = df1['lat'].astype(str)
df1['lon'] = df1['lon'].astype(str)
df1['add1'] = 'SRID=4326;POINT('
df1['add2'] = ' '
df1['add3'] = ')'
df1['geom'] = df1['add1'] + df1['lon'] + df1['add2'] + df1['lat'] + df1['add3']
del df1['lon']
del df1['lat']
del df1['add1']
del df1['add2']
del df1['add3']
df1.to_csv(dataname+'2.txt', header=None)
def data_todb(path,tablename):
engine = create_engine('postgresql://postgres:paaaword@localhost:5432/dbname', use_batch_mode=True)
with engine.connect() as conn, conn.begin():
sql = """CREATE TABLE {tablename}(
index bigint,
value1 bigint,
value2 bigint,
value3 bigint,
geom geometry(Point, 4326)
);
COPY {tablename} FROM '{path}' delimiter ',';
""".format(tablename=tablename,path=path)
conn.execute(sql)
def near():
engine = create_engine('postgresql://postgres:password@localhost:5432/dbname', use_batch_mode=True)
with engine.connect() as conn, conn.begin():
sql = """SELECT * into c
FROM
(
SELECT p.index, b.id AS b_index
FROM a p
CROSS JOIN LATERAL (
SELECT r.index AS id, r.geom AS geom
FROM b r
ORDER BY r.geom <-> p.geom
LIMIT 1
)b
)AS table1"""
conn.execute(sql)
print("完成:" + str(datetime.datetime.now()))
if __name__ == '__main__':
A = create_data('A')
B = create_data('B',1000)
data_todb('/data1/yugang/code/example/A2.txt','a')
data_todb('/data1/yugang/code/example/B2.txt','b')
near()结束语
以上数据规模代码在我的环境下跑完只需要几秒钟,不过真正应用到大量级数据下用时较长,copy方式导入五千多万条点数据需要十多分钟,之后为其跨表查找最近邻要素花了一个多小时。
另外采用copy方式导入的空间数据是没用空间索引的,但是使用没有空间索引的最近邻查询花费的时间比有空间索引花费的时间要短,这也是件奇怪的问题。
转载自:https://blog.csdn.net/u010430471/article/details/79499448



