
(2)Python快速入门
目录
Python是面向对象,高级语言,解释,动态和多用途编程语言。Python易于学习,而且功能强大,功能多样的脚本语言使其对应用程序开发具有吸引力。
Python的语法和动态类型具有其解释性质,使其成为许多领域的脚本编写和快速应用程序开发的理想语言。
Python支持多种编程模式,包括面向对象编程,命令式和函数式编程或过程式编程。
Python几乎无所不能,一些常用的开发领域,如Web编程。这就是为什么它被称为多用途,因为它可以用于网络,企业,3D CAD等软件和系统开发。
在Python中,不需要使用数据类型来声明变量,因为它是动态类型的,所以可以写一个如 a=10 来声明一个变量a中的值是一个整数类型。
Python使开发和调试快速,因为在python开发中没有包含编译步骤,并且编辑 <-> 测试 <-> 调试循环使用代码开发效率非常高。
Python是一种高级,解释,交互和面向对象的脚本语言。 Python被设计为高度可读性。 它使用英语关键字,而其他语言使用标点符号。它的语法结构比其他语言少。
-
Python是解释型语言 – Python代码在解释器中运行时处理,执行前不需要编译程序。 这与PERL和PHP类似。
-
Python是交动的 – 在Python提示符下面直接和解释器进行交互来编写程序。
-
Python是面向对象的 – Python支持面向对象的风格或编程技术,将代码封装在对象内。
-
Python是一门初学者的语言 – Python是初学者程序员的伟大语言,并支持从简单的文本处理到WWW浏览器到游戏的各种应用程序的开发。
第一节 Python 可以用来开发什么?
Python作为一个整体可以用于任何软件开发领域。下面来看看Python可以应用在哪些领域的开发。如下所列 –
1.基于控制台的应用程序
Python可用于开发基于控制台的应用程序。 例如:IPython。
2.基于音频或视频的应用程序
Python在多媒体部分开发,证明是非常方便的。 一些成功的应用是:TimPlayer,cplay等。
3.3D CAD应用程序
Fandango是一个真正使用Python编写的应用程序,提供CAD的全部功能。
4.Web应用程序
Python也可以用于开发基于Web的应用程序。 一些重要的开发案例是:PythonWikiEngines,Pocoo,PythonBlogSoftware等,如国内的成功应用案例有:豆瓣,知乎等。
5.企业级应用
Python可用于创建可在企业或组织中使用的应用程序。一些实时应用程序是:OpenErp,Tryton,Picalo等。
6.图像应用
使用Python可以开发图像应用程序。 开发的应用有:VPython,Gogh,imgSeek等
第二节 Python安装和环境配置
Python 3适用于Windows,Mac OS和大多数Linux操作系统。即使Python 2目前可用于许多其他操作系统,有部分系统Python 3还没有提供支持或者支持了但被它们在系统上删除了,只保留旧的Python 2版本。
参考:http://www.yiibai.com/python/python_environment.html
第三节 Python命令行参数
Python提供了一个getopt模块,用于解析命令行选项和参数。
$ python test.py arg1 arg2 arg3
Python sys模块通过sys.argv提供对任何命令行参数的访问。主要有两个参数变量 –
sys.argv是命令行参数的列表。len(sys.argv)是命令行参数的数量。
这里sys.argv [0]是程序名称,即脚本的名称。比如在上面示例代码中,sys.argv [0]的值就是 test.py。
示例
看看以下脚本command_line_arguments.py的代码 –
#!/usr/bin/python3
import sys
print ('Number of arguments:', len(sys.argv), 'arguments.')
print ('Argument List:', str(sys.argv))
现在运行上面的脚本,这将产生以下结果 –
F:\>python F:\worksp\python\command_line_arguments.py
Number of arguments: 1 arguments.
Argument List: ['F:\\worksp\\python\\command_line_arguments.py']
F:\>python F:\worksp\python\command_line_arguments.py arg1 arg2 arg3 arg4
Number of arguments: 5 arguments.
Argument List: ['F:\\worksp\\python\\command_line_arguments.py', 'arg1', 'arg2', 'arg3', 'arg4']
F:\>
注意 – 如上所述,第一个参数始终是脚本名称,它也被计入参数的数量。
解析命令行参数
Python提供了一个getopt模块,可用于解析命令行选项和参数。该模块提供了两个功能和异常,以启用命令行参数解析。
getopt.getopt方法
此方法解析命令行选项和参数列表。以下是此方法的简单语法 –
getopt.getopt(args, options, [long_options])
getopt.GetoptError异常
当在参数列表中有一个无法识别的选项,或者当需要一个参数的选项不为任何参数时,会引发这个异常。
异常的参数是一个字符串,指示错误的原因。 属性msg和opt给出错误消息和相关选项。
示例
假设想通过命令行传递两个文件名,也想给出一个选项用来显示脚本的用法。脚本的用法如下 –
usage: file.py -i <inputfile> -o <outputfile>
以下是command_line_usage.py的以下脚本 –
#!/usr/bin/python3
import sys, getopt
def main(argv):
inputfile = ''
outputfile = ''
try:
opts, args = getopt.getopt(argv,"hi:o:",["ifile=","ofile="])
except getopt.GetoptError:
print ('GetoptError, usage: command_line_usage.py -i <inputfile> -o <outputfile>')
sys.exit(2)
for opt, arg in opts:
if opt == '-h':
print ('usage: command_line_usage.py -i <inputfile> -o <outputfile>')
sys.exit()
elif opt in ("-i", "--ifile"):
inputfile = arg
elif opt in ("-o", "--ofile"):
outputfile = arg
print ('Input file is "', inputfile)
print ('Output file is "', outputfile)
if __name__ == "__main__":
main(sys.argv[1:])
现在,使用以下几种方式运行来脚本,输出如下所示:
F:\worksp\python>python command_line_usage.py -h
usage: command_line_usage.py -i <inputfile> -o <outputfile>
F:\worksp\python>python command_line_usage.py -i inputfile.txt -o
GetoptError, usage: command_line_usage.py -i <inputfile> -o <outputfile>
F:\worksp\python>python command_line_usage.py -i inputfile.txt -o outputfile.txt
Input file is " inputfile.txt
Output file is " outputfile.txt
F:\worksp\python>
第四节 Python变量类型
变量是保存存储值的内存位置。也就是说,当创建一个变量时,可以在内存中保留一些空间。
基于变量的数据类型,解释器分配内存并决定可以存储在保留的存储器中的内容。 因此,通过为变量分配不同的数据类型,可以在这些变量中存储的数据类型为整数,小数或字符等等。
将值分配给变量
在Python中,变量不需要明确的声明类型来保留内存空间。当向变量分配值时,Python会自动发出声明。 等号(=)用于为变量赋值。
=运算符左侧的操作数是变量的名称,而=运算符右侧的操作数是将在存储在变量中的值。 例如 –
#!/usr/bin/python3
counter = 100 # 一个整型数
miles = 999.99 # 一个浮点数
name = "Maxsu" # 一个字符串
site_url = "http://www.yiibai.com" # 一个字符串
print (counter)
print (miles)
print (name)
print (site_url)
这里,100,999.99和“Maxsu”分别是分配给counter,miles和name变量的值。执行上面代码将产生以下结果 –
100
999.99
Maxsu
http://www.yiibai.com
多重赋值
Python允许同时为多个变量分配单个值。
例如 –
a = b = c = 1
这里,创建一个整数对象,其值为1,并且所有三个变量都分配给相同的内存位置。还可以将多个对象分配给多个变量。 例如 –
a, b, c = 10, 20, "maxsu"
这里,将两个值为10和20的整数对象分别分配给变量a和b,并将一个值为“maxsu”的字符串对象分配给变量c。
标准数据类型
存储在内存中的数据可以是多种类型。 例如,一个人的年龄可存储为一个数字值,他的地址被存储为字母数字字符串。 Python具有各种标准数据类型,用于定义可能的操作以及每个标准数据类型的存储方法。
Python有五种标准数据类型 –
- 1.数字
- 2.字符串
- 3.列表
- 4.元组
- 5.字典
1.Python数字
数字数据类型存储数字值。当为其分配值时,将创建数字对象。 例如 –
var1 = 10
var2 = 20
可以使用del语句删除对数字对象的引用。 del语句的语法是 –
del var1[,var2[,var3[....,varN]]]]
可以使用del语句删除单个对象或多个对象。
例如 –
del var
del var_a, var_b
Python支持三种不同的数值类型 –
- int(有符号整数)
- float(浮点实值)
- complex(复数)
Python3中的所有整数都表示为长整数。 因此,长整数没有单独的数字类型。
例子
以下是一些数字示例 –
| int | float | complex |
|---|---|---|
| 10 | 0.0 | 3.14j |
| 100 | 15.20 | 45.j |
| -786 | -21.9 | 9.322e-36j |
| 080 | 32.3+e18 | .876j |
| -0490 | -90. | -.6545+0J |
| -0x260 | -32.54e100 | 3e+26J |
| 0x69 | 70.2-E12 | 4.53e-7j |
复数是由x + yj表示的有序对的实数浮点数组成,其中x和y是实数,j是虚数单位。
2.Python字符串
Python中的字符串被标识为在引号中表示的连续字符集。Python允许双引号或双引号。 可以使用片段运算符([]和[:])来获取字符串的子集(子字符串),其索引从字符串开始处的索引0开始,并且以-1表示字符串中的最后一个字符。
加号(+)是字符串连接运算符,星号(*)是重复运算符。例如 –
#!/usr/bin/python3
#coding=utf-8
# save file: variable_types_str1.py
str = 'yiibai.com'
print ('str = ', str) # Prints complete string
print ('str[0] = ',str[0]) # Prints first character of the string
print ('str[2:5] = ',str[2:5]) # Prints characters starting from 3rd to 5th
print ('str[2:] = ',str[2:]) # Prints string starting from 3rd character
print ('str[-1] = ',str[-1]) # 最后一个字符,结果为:'!'
print ('str * 2 = ',str * 2) # Prints string two times
print ('str + "TEST" = ',str + "TEST") # Prints concatenated string
将上面代码保存到 variable_types_str1.py 文件中,执行将产生以下结果 –
F:\worksp\python>python variable_types_str1.py
str = yiibai.com
str[0] = y
str[2:5] = iba
str[2:] = ibai.com
str[-1] = m
str * 2 = yiibai.comyiibai.com
str + "TEST" = yiibai.comTEST
F:\worksp\python>
2.Python列表
列表是Python复合数据类型中最多功能的。 一个列表包含用逗号分隔并括在方括号([])中的项目。在某种程度上,列表类似于C语言中的数组。它们之间的区别之一是Python列表的所有项可以是不同的数据类型,而C语言中的数组只能是同种类型。
存储在列表中的值可以使用切片运算符([]和[])来访问,索引从列表开头的0开始,并且以-1表示列表中的最后一个项目。 加号(+)是列表连接运算符,星号(*)是重复运算符。例如 –
#!/usr/bin/python3
#coding=utf-8
# save file: variable_types_str1.py
list = [ 'yes', 'no', 786 , 2.23, 'minsu', 70.2 ]
tinylist = [100, 'maxsu']
print ('list = ', list) # Prints complete list
print ('list[0] = ',list[0]) # Prints first element of the list
print ('list[1:3] = ',list[1:3]) # Prints elements starting from 2nd till 3rd
print ('list[2:] = ',list[2:]) # Prints elements starting from 3rd element
print ('list[-3:-1] = ',list[-3:-1])
print ('tinylist * 2 = ',tinylist * 2) # Prints list two times
print ('list + tinylist = ', list + tinylist) # Prints concatenated lists
将上面代码保存到 variable_types_str1.py 文件中,执行将产生以下结果 –
F:\worksp\python>python variable_types_list.py
list = ['yes', 'no', 786, 2.23, 'minsu', 70.2]
list[0] = yes
list[1:3] = ['no', 786]
list[2:] = [786, 2.23, 'minsu', 70.2]
list[-3:-1] = [2.23, 'minsu']
tinylist * 2 = [100, 'maxsu', 100, 'maxsu']
list + tinylist = ['yes', 'no', 786, 2.23, 'minsu', 70.2, 100, 'maxsu']
F:\worksp\python>
3.Python元组
元组是与列表非常类似的另一个序列数据类型。元组是由多个值以逗号分隔。然而,与列表不同,元组被括在小括号内(())。
列表和元组之间的主要区别是 – 列表括在括号([])中,列表中的元素和大小可以更改,而元组括在括号(())中,无法更新。元组可以被认为是只读列表。 例如 –
#!/usr/bin/python3
#coding=utf-8
# save file : variable_types_tuple.py
tuple = ( 'maxsu', 786 , 2.23, 'yiibai', 70.2 )
tinytuple = (999.0, 'maxsu')
# tuple[1] = 'new item value' 不能这样赋值
print ('tuple = ', tuple) # Prints complete tuple
print ('tuple[0] = ', tuple[0]) # Prints first element of the tuple
print ('tuple[1:3] = ', tuple[1:3]) # Prints elements starting from 2nd till 3rd
print ('tuple[-3:-1] = ', tuple[-3:-1]) # 输出结果是什么?
print ('tuple[2:] = ', tuple[2:]) # Prints elements starting from 3rd element
print ('tinytuple * 2 = ',tinytuple * 2) # Prints tuple two times
print ('tuple + tinytuple = ', tuple + tinytuple) # Prints concatenated tuple
将上面代码保存到 variable_types_tuple.py 文件中,执行将产生以下结果 –
F:\worksp\python>python variable_types_tuple.py
tuple = ('maxsu', 786, 2.23, 'yiibai', 70.2)
tuple[0] = maxsu
tuple[1:3] = (786, 2.23)
tuple[-3:-1] = (2.23, 'yiibai')
tuple[2:] = (2.23, 'yiibai', 70.2)
tinytuple * 2 = (999.0, 'maxsu', 999.0, 'maxsu')
tuple + tinytuple = ('maxsu', 786, 2.23, 'yiibai', 70.2, 999.0, 'maxsu')
F:\worksp\python>
以下代码对于元组无效,因为尝试更新元组,但是元组是不允许更新的。类似的情况可能与列表 –
#!/usr/bin/python3
tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 )
list = [ 'abcd', 786 , 2.23, 'john', 70.2 ]
tuple[2] = 1000 # 无法更新值,程序出错
list[2] = 1000 # 有效的更新,合法
Python字典
Python的字典是一种哈希表类型。它们像Perl中发现的关联数组或散列一样工作,由键值对组成。字典键几乎可以是任何Python数据类型,但通常为了方便使用数字或字符串。另一方面,值可以是任意任意的Python对象。
字典由大括号({})括起来,可以使用方括号([])分配和访问值。例如 –
#!/usr/bin/python3
#coding=utf-8
# save file : variable_types_dict.py
dict = {}
dict['one'] = "This is one"
dict[2] = "This is my"
tinydict = {'name': 'maxsu', 'code' : 1024, 'dept':'IT Dev'}
print ("dict['one'] = ", dict['one']) # Prints value for 'one' key
print ('dict[2] = ', dict[2]) # Prints value for 2 key
print ('tinydict = ', tinydict) # Prints complete dictionary
print ('tinydict.keys() = ', tinydict.keys()) # Prints all the keys
print ('tinydict.values() = ', tinydict.values()) # Prints all the values
将上面代码保存到 variable_types_dict.py 文件中,执行将产生以下结果 –
F:\worksp\python>python variable_types_dict.py
dict['one'] = This is one
dict[2] = This is my
tinydict = {'name': 'maxsu', 'code': 1024, 'dept': 'IT Dev'}
tinydict.keys() = dict_keys(['name', 'code', 'dept'])
tinydict.values() = dict_values(['maxsu', 1024, 'IT Dev'])
字典中的元素没有顺序的概念。但是说这些元素是“乱序”是不正确的; 它们是无序的。
数据类型转换
有时,可能需要在内置类型之间执行转换。要在类型之间进行转换,只需使用类型名称作为函数即可。
有以下几种内置函数用于执行从一种数据类型到另一种数据类型的转换。这些函数返回一个表示转换值的新对象。它们分别如下所示 –
| 编号 | 函数 | 描述 |
|---|---|---|
| 1 | int(x [,base]) |
将x转换为整数。如果x是字符串,则要base指定基数。 |
| 2 | float(x) |
将x转换为浮点数。 |
| 3 | complex(real [,imag]) |
创建一个复数。 |
| 4 | str(x) |
将对象x转换为字符串表示形式。 |
| 5 | repr(x) |
将对象x转换为表达式字符串。 |
| 6 | eval(str) |
评估求值一个字符串并返回一个对象。 |
| 7 | tuple(s) |
将s转换为元组。 |
| 8 | list(s) |
将s转换为列表。 |
| 9 | set(s) |
将s转换为集合。 |
| 10 | dict(d) |
创建一个字典,d必须是(key,value)元组的序列 |
| 11 | frozenset(s) |
将s转换为冻结集 |
| 12 | chr(x) |
将整数x转换为字符 |
| 13 | unichr(x) |
将整数x转换为Unicode字符。 |
| 14 | ord(x) |
将单个字符x转换为其整数值。 |
| 15 | hex(x) |
将整数x转换为十六进制字符串。 |
| 16 | oct(x) |
将整数x转换为八进制字符串。 |
第五节 Python基本运算符
运算符是可以操纵操作数值的结构。如下一个表达式:10 + 20 = 30。这里,10和20称为操作数,+则被称为运算符。
运算符类型
Python语言支持以下类型的运算符 –
- 1.算术运算符
- 2.比较(关系)运算符
- 3.赋值运算符
- 4.逻辑运算符
- 5.按位运算符
- 6.成员运算符
- 7.身份运算符
下面让我们依次来看看所有的运算符。
1.算术运算符
假设变量a的值是10,变量b的值是21,则 –
| 运算符 | 描述 | 示例 |
|---|---|---|
+ |
加法运算,将运算符两边的操作数增加。 | a + b = 31 |
- |
减法运算,将运算符左边的操作数减去右边的操作数。 | a – b = -11 |
* |
乘法运算,将运算符两边的操作数相乘 | a * b = 210 |
/ |
除法运算,用右操作数除左操作数 | b / a = 2.1 |
% |
模运算,用右操作数除数左操作数并返回余数 | b % a = 1 |
** |
对运算符进行指数(幂)计算 | a ** b,表示10的21次幂 |
// |
地板除 – 操作数的除法,其结果是删除小数点后的商数。 但如果其中一个操作数为负数,则结果将被保留,即从零(向负无穷大)舍去 | 9//2 = 4 , 9.0//2.0 = 4.0, -11//3 = -4, -11.0//3 = -4.0 |
有关算术运算符的示例代码,请参考::http://www.yiibai.com/python/arithmetic_operators_example.html
2.比较(关系)运算符
比较(关系)运算符比较它们两边的值,并确定它们之间的关系。它们也称为关系运算符。假设变量a的值10,变量b的值是20,则 –
| 运算符 | 描述 | 示例 |
|---|---|---|
== |
如果两个操作数的值相等,则条件为真。 | (a == b)求值结果为 false |
!= |
如果两个操作数的值不相等,则条件为真。 | (a != b)求值结果为 true |
> |
如果左操作数的值大于右操作数的值,则条件成为真。 | (a > b)求值结果为 false |
< |
如果左操作数的值小于右操作数的值,则条件成为真。 | (a < b)求值结果为 true |
>= |
如果左操作数的值大于或等于右操作数的值,则条件成为真。 | (a >= b)求值结果为 false |
<= |
如果左操作数的值小于或等于右操作数的值,则条件成为真。 | (a <= b)求值结果为 true |
有关比较(关系)运算符的示例代码,请参考:http://www.yiibai.com/python/comparison_operators_example.html
3.赋值运算符
假设变量a的值10,变量b的值是20,则 –
| 运算符 | 描述 | 示例 |
|---|---|---|
= |
将右侧操作数的值分配给左侧操作数 | c = a + b表示将a + b的值分配给c |
+= |
将右操作数相加到左操作数,并将结果分配给左操作数 | c + = a等价于c = c + a |
-= |
从左操作数中减去右操作数,并将结果分配给左操作数 | c -= a 等价于 c = c - a |
*= |
将右操作数与左操作数相乘,并将结果分配给左操作数 | c *= a 等价于 c = c * a |
/= |
将左操作数除以右操作数,并将结果分配给左操作数 | c /= a 等价于 c = c / a |
%= |
将左操作数除以右操作数的模数,并将结果分配给左操作数 | c %= a 等价于 c = c % a |
**= |
执行指数(幂)计算,并将值分配给左操作数 | c **= a 等价于 c = c ** a |
//= |
运算符执行地板除运算,并将值分配给左操作数 | c //= a 等价于 c = c // a |
有关赋值运算符的示例代码,请参考:http://www.yiibai.com/python/assignment_operators_example.html
4.逻辑运算符
Python语言支持以下逻辑运算符。假设变量a的值为True,变量b的值为False,那么 –
| 运算符 | 描述 | 示例 |
|---|---|---|
and |
如果两个操作数都为真,则条件成立。 | (a and b)的结果为False |
or |
如果两个操作数中的任何一个非零,则条件成为真。 | (a or b)的结果为True |
not |
用于反转操作数的逻辑状态。 | not(a and b) 的结果为True。 |
有关逻辑运算符的示例代码,请参考:http://www.yiibai.com/python/logical_operators_example.html
5.按位运算符
按位运算符执行逐位运算。 假设变量a = 60; 和变量b = 13; 现在以二进制格式,它们将如下 –
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011
Python的内置函数bin()可用于获取整数的二进制表示形式。
以下是Python语言支持位运算操作符 –
| 运算符 | 描述 | 示例 |
|---|---|---|
& |
如果它存在于两个操作数中,则操作符复制位到结果中 | (a & b) 结果表示为 0000 1100 |
 |
如果它存在于任一操作数,则复制位。 | (a b) = 61 结果表示为 0011 1101 |
^ |
二进制异或。如果它是一个操作数集合,但不是同时是两个操作数则将复制位。 | (a ^ b) = 49 (结果表示为 0011 0001) |
~ |
二进制补码,它是一元的,具有“翻转”的效果。 | (~a ) = -61有符号的二进制数,表示为1100 0011的补码形式。 |
<< |
二进制左移,左操作数的值由右操作数指定的位数左移。 | a << 2 = 240 (结果表示为 1111 0000) |
>> |
二进制右移,左操作数的值由右操作数指定的位数右移。 | a >> 2 = 15(结果表示为0000 1111) |
有关按位运算符的示例代码,请参考:http://www.yiibai.com/python/bitwise_operators_example.html
6.成员运算符
Python成员运算符测试给定值是否为序列中的成员,例如字符串,列表或元组。 有两个成员运算符,如下所述 –
| 运算符 | 描述 | 示例 |
|---|---|---|
in |
如果在指定的序列中找到一个变量的值,则返回true,否则返回false。 |
– |
not in |
如果在指定序列中找不到变量的值,则返回true,否则返回false。 |
– |
有关成员运算符的示例代码,请参考:http://www.yiibai.com/python/membership_operators_example.html
7.身份运算符
身份运算符比较两个对象的内存位置。常用的有两个身份运算符,如下所述 –
| 运算符 | 描述 | 示例 |
|---|---|---|
is |
如果运算符任一侧的变量指向相同的对象,则返回True,否则返回False。 |
|
is not |
如果运算符任一侧的变量指向相同的对象,则返回True,否则返回False。 |
– |
有关身份运算符的示例代码,请参考:http://www.yiibai.com/python/identity_operators_example.html
8. 运算符优先级
下表列出了从最高优先级到最低优先级的所有运算符,如下所示 –
| 序号 | 运算符 | 描述 |
|---|---|---|
| 1 | ** |
指数(次幂)运算 |
| 2 | ~ + - |
补码,一元加减(最后两个的方法名称是+@和-@) |
| 3 | * / % // |
乘法,除法,模数和地板除 |
| 4 | + - |
|
| 5 | >> << |
向右和向左位移 |
| 6 | & |
按位与 |
| 7 | ^ |
按位异或和常规的“OR” |
| 8 | <= < > >= |
比较运算符 |
| 9 | <> == != |
等于运算符 |
| 10 | = %= /= //= -= += *= **= |
赋值运算符 |
| 11 | is is not |
身份运算符 |
| 12 | in not in |
成员运算符 |
| 13 | not or and |
逻辑运算符 |
有关运算符优先级的示例代码,请参考:http://www.yiibai.com/python/operators_precedence_example.html
第六节 Python决策
决策是指在执行程序期间根据发生的情况并根据条件采取的具体操作(行动)。决策结构评估求值多个表达式,产生TRUE或FALSE作为结果。如果结果为TRUE或否则为FALSE,则需要确定要执行的操作和要执行的语句。
以下是大多数编程语言中的典型决策结构的一般形式 –
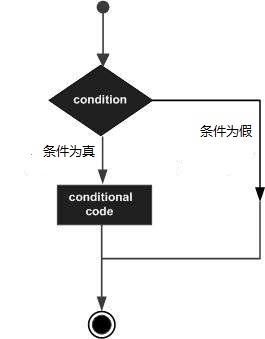
Python编程语言假定任何非零值和非空值都为TRUE值,而任何零值或空值都为FALSE值。
Python编程语言提供以下类型的决策语句。
| 编号 | 语句 | 描述 |
|---|---|---|
| 1 | if语句 | 一个if语句由一个布尔表达式,后跟一个或多个语句组成。 |
| 2 | if…else语句 | 一个if语句可以跟随一个可选的else语句,当if语句的布尔表达式为FALSE时,则else语句块将被执行。 |
| 3 | 嵌套if语句 | 可以在一个if或else语句中使用一个if或else if语句。 |
下面我们快速地来了解每个决策声明。
单个语句套件
一个if子句套件可能只包含一行,它可能与头语句在同一行上。
示例
以下是一行if子句的示例 –
#!/usr/bin/python3
var = 10
if ( var == 10 ) : print ("Value of expression is 10")
print ("Good bye!")
当执行上述代码时,会产生以下结果 –
Value of expression is 100
Good bye!
第七节 Python循环
一般来说,语句依次执行 – 例如,函数中的第一个语句首先执行,然后是第二个语句,依次类推。但是有很多时候需要多次执行同一段代码,这就引入了循环的概念。
编程语言提供了允许更复杂的执行路径的各种控制结构。
循环语句允许多次执行语句或语句组。下图说明了一个循环语句流程结构 –
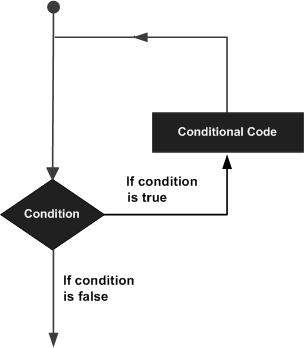
Python编程语言提供以下类型的循环来处理循环需求。
| 编号 | 循环 | 描述 |
|---|---|---|
| 1 | while循环 | 在给定条件为TRUE时,重复一个语句或一组语句。 它在执行循环体之前测试状态。 |
| 2 | for循环 | 多次执行一系列语句,并缩写管理循环变量的代码。 |
| 3 | 嵌套循环 | 可以使用一个或多个循环在while或for循环中。 |
循环控制语句
循环控制语句从正常顺序更改执行。 当执行离开范围时,在该范围内创建的所有自动对象都将被销毁。
Python支持以下控制语句。
| 编号 | 控制语句 | 描述 |
|---|---|---|
| 1 | break语句 | 终止循环语句并将执行转移到循环之后的语句。 |
| 2 | continue语句 | 使循环跳过其主体的剩余部分,并立即重新测试其状态以进入下一次迭代。 |
| 3 | pass语句 | 当语法需要但不需要执行任何命令或代码时,Python中就可以使用pass语句,此语句什么也不做,用于表示“占位”的代码,有关实现细节后面再写 |
下面简单地看一下循环控制语句。
迭代器和生成器
迭代器(Iterator)是允许程序员遍历集合的所有元素的对象,而不管其具体实现。在Python中,迭代器对象实现了iter()和next()两种方法。
String,List或Tuple对象可用于创建Iterator。
list = [1,2,3,4]
it = iter(list) # this builds an iterator object
print (next(it)) #prints next available element in iterator
# Iterator object can be traversed using regular for statement
for x in it:
print (x, end=" ")
or using next() function
while True:
try:
print (next(it))
except StopIteration:
sys.exit() #you have to import sys module for this
发生器(generator)是使用yield方法产生或产生一系列值的函数。
当一个生成器函数被调用时,它返回一个生成器对象,而不用执行该函数。 当第一次调用next()方法时,函数开始执行,直到它达到yield语句,返回yielded值。 yield保持跟踪,即记住最后一次执行,而第二个next()调用从前一个值继续。
示例
以下示例定义了一个生成器,它为所有斐波纳契数字生成一个迭代器。
#!usr/bin/python3
import sys
def fibonacci(n): #generator function
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(5) #f is iterator object
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()
第八节 Python数字
数字数据类型用于存储数值。它们是不可变数据类型。这意味着,更改数字数据类型的值会导致新分配对象。
当为数字数据类型分配值时,Python将创建数字对象。 例如 –
var1 = 1
var2 = 10
可以使用del语句删除对数字对象的引用。del语句的语法是 –
del var1[,var2[,var3[....,varN]]]]
可以使用del语句一次删除单个对象或多个对象。 例如 –
del var
del var_a, var_b
Python支持不同的数值类型 –
-
int(有符号整数) – 它们通常被称为整数或整数。它们是没有小数点的正或负整数。 Python 3中的整数是无限大小的。 Python 2 有两个整数类型 –
int和long。 Python 3中没有“长整数”。 -
float(浮点实数值) – 也称为浮点数,它们表示实数,并用小数点写整数和小数部分。 浮点数也可以是科学符号,
E或e表示10的幂 –
-
complex(复数) – 复数是以
a + bJ的形式,其中a和b是浮点,J(或j)表示-1的平方根(虚数)。数字的实部是a,虚部是b。复数在Python编程中并没有太多用处。
可以以十六进制或八进制形式表示整数 –
>>> number = 0xA0F #Hexa-decimal
>>> number
2575
>>> number = 0o37 #Octal
>>> number
31
例子
以下是一些数字值的示例 –
| int | float | complex |
|---|---|---|
| 10 | 0.0 | 3.14j |
| 100 | 15.20 | 45.j |
| -786 | -21.9 | 9.322e-36j |
| 080 | 32.3+e18 | .876j |
| -0490 | -90. | -.6545+0J |
| -0×260 | -32.54e100 | 3e+26J |
| 0×69 | 70.2-E12 | 4.53e-7j |
复数由一个a + bj来表示,它是由实际浮点数的有序对组成,其中a是实部,b是复数的虚部。
数字类型转换
Python可将包含混合类型的表达式内部的数字转换成用于评估求值的常用类型。 有时需要从一个类型到另一个类型执行明确数字转换,以满足运算符或函数参数的要求。
int(x)将x转换为纯整数。long(x)将x转换为长整数。float(x)将x转换为浮点数。complex(x)将x转换为具有实部x和虚部0的复数。complex(x, y)将x和y转换为具有实部为x和虚部为y的复数。x和y是数字表达式。
数学函数
Python中包括执行数学计算的函数,如下列表所示 –
| 编号 | 函数 | 描述 |
|---|---|---|
| 1 | abs(x) | x的绝对值,x与零之间的(正)距离。 |
| 2 | ceil(x) | x的上限,不小于x的最小整数。 |
| 3 | cmp(x, y) |
如果 x < y 返回 -1, 如果 x == y 返回 0, 或者 如果 x > y 返回 1。在Python 3中已经弃用,可使用return (x>y)-(x<y)代替。 |
| 4 | exp(x) | x的指数,返回e的x次幂 |
| 5 | fabs(x) | x的绝对值。 |
| 6 | floor(x) | 不大于x的最大整数。 |
| 7 | log(x) | x的自然对数(x > 0)。 |
| 8 | log10(x) | 以基数为10的x的对数(x > 0)。 |
| 9 | max(x1, x2,…) | 给定参数中的最大值,最接近正无穷大值 |
| 10 | min(x1, x2,…) | 给定参数中的最小值,最接近负无穷小值 |
| 11 | modf(x) | 将x的分数和整数部分切成两项放入元组中,两个部分与x具有相同的符号。整数部分作为浮点数返回。 |
| 12 | pow(x, y) | x的y次幂 |
| 13 | round(x [,n]) | x从小数点舍入到n位数。round(0.5)结果为 1.0, round(-0.5) 结果为 -1.0 |
| 14 | sqrt(x) | x的平方根(x > 0)。 |
随机数函数
随机数字用于游戏,模拟,测试,安全和隐私应用。 Python包括以下通常使用的函数。
| 编号 | 函数 | 描述 |
|---|---|---|
| 1 | choice(seq) | 来自列表,元组或字符串的随机项目。 |
| 2 | randrange ([start,] stop [,step]) | 从范围(start, stop, step)中随机选择的元素。 |
| 3 | random() | 返回随机浮点数r(0 <= r < 1) |
| 4 | seed([x]) | 设置用于生成随机数的整数起始值。在调用任何其他随机模块功能之前调用此函数,返回None。 |
| 5 | shuffle(lst) | 将列表的项目随机化到位置。 返回None。 |
| 6 | uniform(x, y) | 返回随机浮点数 r (x <= r < y)。 |
三角函数
随机数字用于游戏,模拟,测试,安全和隐私应用。 Python包括以下通常使用的函数。
| 编号 | 函数 | 描述 |
|---|---|---|
| 1 | acos(x) | 返回x的弧余弦值,以弧度表示。 |
| 2 | asin(x) | 返回x的弧线正弦,以弧度表示。 |
| 3 | atan(x) | 返回x的反正切,以弧度表示。 |
| 4 | atan2(y, x) | 返回atan(y / x),以弧度表示。 |
| 5 | cos(x) | 返回x弧度的余弦。 |
| 6 | hypot(x, y) | 返回欧几里得规范,sqrt(x*x + y*y) |
| 7 | sin(x) | 返回x弧度的正弦。 |
| 8 | tan(x) | 返回x弧度的正切值。 |
| 9 | degrees(x) | 将角度x从弧度转换为度。 |
| 10 | radians(x) | 将角度x从角度转换为弧度。 |
数学常数
该模块还定义了两个数学常数 –
| 编号 | 常量 | 描述 |
|---|---|---|
| 1 | pi | 数学常数pi |
| 2 | e | 数学常数e |
第九节 Python字符串
字符串是Python中最受欢迎、最常使用的数据类型。可以通过用引号括起字符来创建它们。 Python将单引号与双引号相同。创建字符串和向一个变量赋值一样简单。 例如 –
var1 = 'Hello World!'
var2 = "Python Programming"
1.访问字符串中的值
Python不支持字符类型; 字符会被视为长度为1的字符串,因此也被认为是一个子字符串。要访问子串,请使用方括号的切片加上索引或直接使用索引来获取子字符串。 例如 –
#!/usr/bin/python3
var1 = 'Hello World!'
var2 = "Python Programming"
print ("var1[0]: ", var1[0])
print ("var2[1:5]: ", var2[1:5]) # 切片加索引
当执行上述代码时,会产生以下结果 –
var1[0]: H
var2[1:5]: ytho
2.更新字符串
可以通过将变量分配给另一个字符串来“更新”现有的字符串。 新值可以与其原值相关或完全不同的字符串。 例如 –
#!/usr/bin/python3
var1 = 'Hello World!'
print ("Updated String :- ", var1[:6] + 'Python')
当执行上述代码时,会产生以下结果 –
Updated String :- Hello Python
3.转义字符
下表是可以用反斜杠表示法表示转义或不可打印字符的列表。单引号以及双引号字符串的转义字符被解析。
| 反斜线符号 | 十六进制字符 | 描述/说明 |
|---|---|---|
\a |
0x07 |
铃声或警报 |
\b |
0x08 |
退格 |
\cx |
Control-x | |
\C-x |
Control-x | |
\e |
0x1b |
Escape |
\f |
0x0c |
换页 |
\M-\C-x |
Meta-Control-x | |
\n |
0x0a |
新一行 |
\nnn |
八进制符号,其中n在0.7范围内 |
|
\r |
0x0d |
回车返回 |
\s |
0x20 |
空格 |
\t |
0x09 |
制表符 |
\v |
0x0b |
垂直制表符 |
\x |
字符x |
|
\xnn |
十六进制符号,其中n在0~9,a~f或A~F范围内 |
4.字符串特殊运算符
假设字符串变量a保存字符串值’Hello‘,变量b保存字符串值’Python‘,那么 –
| 运算符 | 说明 | 示例 |
|---|---|---|
+ |
连接 – 将运算符的两边的值添加 | a + b 结果为 HelloPython |
* |
重复 – 创建新字符串,连接相同字符串的多个副本 | a*2 结果为 HelloHello |
[] |
切片 – 给出指定索引中的字符串值,它是原字符串的子串。 | a[1] 结果为 e |
[:] |
范围切片 – 给出给定范围内的子字符串 | a[1:4] 结果为 ell |
in |
成员关系 – 如果给定字符串中存在指定的字符,则返回true |
'H' in a 结果为 1 |
not in |
成员关系 – 如果给定字符串中不存在指定的字符,则返回true |
'Y' not in a 结果为 1 |
r/R |
原始字符串 – 抑制转义字符的实际含义。原始字符串的语法与正常字符串的格式完全相同,除了原始字符串运算符在引号之前加上字母“r”。 “r”可以是小写(r)或大写(R),并且必须紧靠在第一个引号之前。 |
print(r'\n') 将打印 \n ,或者 print(R'\n') 将打印 \n,要注意的是如果不加r或R作为前缀,打印的结果就是一个换行。 |
% |
格式 – 执行字符串格式化 | 请参见本文第5节 |
5.字符串格式化运算符
Python最酷的功能之一是字符串格式运算符%。 这个操作符对于字符串是独一无二的,弥补了C语言中 printf()系列函数。 以下是一个简单的例子 –
#!/usr/bin/python3
print ("My name is %s and weight is %d kg!" % ('Maxsu', 71))
当执行上述代码时,会产生以下结果 –
My name is Maxsu and weight is 71 kg!
以下是可以与%符号一起使用的完整符号集列表 –
| 编号 | 格式化符号 | 转换 |
|---|---|---|
| 1 | %c |
字符 |
| 2 | %s |
在格式化之前通过str()函数转换字符串 |
| 3 | %i |
带符号的十进制整数 |
| 4 | %d |
带符号的十进制整数 |
| 5 | %u |
无符号十进制整数 |
| 6 | %o |
八进制整数 |
| 7 | %x |
十六进制整数(小写字母) |
| 8 | %X |
十六进制整数(大写字母) |
| 9 | %e |
指数符号(小写字母’e‘) |
| 10 | %E |
指数符号(大写字母’E‘ |
| 11 | %f |
浮点实数 |
| 12 | %g |
%f和%e |
| 13 | %G |
%f和%E |
其他支持的符号和功能如下表所列 –
| 编号 | 符号 | 功能 |
|---|---|---|
| 1 | * |
参数指定宽度或精度 |
| 2 | - |
左对齐 |
| 3 | + |
显示标志或符号 |
| 4 | <sp> |
在正数之前留空格 |
| 5 | # |
根据是否使用“x”或“X”,添加八进制前导零(‘0‘)或十六进制前导’0x‘或’0X‘。 |
| 6 | 0 |
使用零作为左边垫符(而不是空格) |
| 7 | % |
‘%%‘留下一个文字“%” |
| 8 | (var) |
映射变量(字典参数) |
| 9 | m.n. |
m是最小总宽度,n是小数点后显示的位数(如果应用) |
6.三重引号
Python中的三重引号允许字符串跨越多行,包括逐字记录的新一行,TAB和任何其他特殊字符。
三重引号的语法由三个连续的单引号或双引号组成。
#!/usr/bin/python3
para_str = """this is a long string that is made up of
several lines and non-printable characters such as
TAB ( \t ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
this within the brackets [ \n ], or just a NEWLINE within
the variable assignment will also show up.
"""
print (para_str)
当执行上述代码时,会产生以下结果。注意每个单独的特殊字符如何被转换成其打印形式,它是直到最后一个NEWLINEs在“up”之间的字符串的末尾,并关闭三重引号。 另请注意,NEWLINEs可能会在一行或其转义码(\n)的末尾显式显示回车符 –
this is a long string that is made up of
several lines and non-printable characters such as
TAB ( ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
this within the brackets [
], or just a NEWLINE within
the variable assignment will also show up.
原始字符串根本不将反斜杠视为特殊字符。放入原始字符串的每个字符都保持所写的方式 –
#!/usr/bin/python3
print ('C:\\nowhere')
当执行上述代码时,会产生以下结果 –
C:\nowhere
现在演示如何使用原始的字符串。将表达式修改为如下 –
#!/usr/bin/python3
print (r'C:\\nowhere')
当执行上述代码时,会产生以下结果 –
C:\\nowhere
7.Unicode字符串
在Python 3中,所有的字符串都用Unicode表示。在Python 2内部存储为8位ASCII,因此需要附加’u‘使其成为Unicode,而现在不再需要了。
内置字符串方法
Python包括以下内置方法来操作字符串 –
| 编号 | 方法 | 说明 |
|---|---|---|
| 1 | capitalize() | 把字符串的第一个字母转为大写 |
| 2 | center(width, fillchar) | 返回使用fillchar填充的字符串,原始字符串以总共width列为中心。 |
| 3 | count(str, beg = 0,end = len(string)) | 计算字符串中出现有多少次str或字符串的子字符串(如果开始索引beg和结束索引end,则在beg~end范围匹配)。 |
| 4 | decode(encoding = ‘UTF-8’,errors = ‘strict’) | 使用编码encoding解码该字符串。 编码默认为默认字符串encoding。 |
| 5 | encode(encoding = ‘UTF-8’,errors = ‘strict’) | 返回字符串的编码字符串版本; 在错误的情况下,默认是抛出ValueError,除非使用’ignore‘或’replace‘给出错误。 |
| 6 | endswith(suffix, beg = 0, end = len(string)) | 确定字符串或字符串的子字符串(如果启动索引结束和结束索引结束)都以后缀结尾; 如果是则返回true,否则返回false。 |
| 7 | expandtabs(tabsize = 8) | 将字符串中的制表符扩展到多个空格; 如果没有提供tabize,则默认为每个制表符为8个空格。 |
| 8 | find(str, beg = 0 end = len(string)) | 如果索引beg和结束索引end给定,则确定str是否在字符串或字符串的子字符串中,如果找到则返回索引,否则为-1。 |
| 9 | index(str, beg = 0, end = len(string)) | 与find()相同,但如果没有找到str,则引发异常。 |
| 10 | isalnum() | 如果字符串至少包含1个字符,并且所有字符均为数字,则返回true,否则返回false。 |
| 11 | isalpha() | 如果字符串至少包含1个字符,并且所有字符均为字母,则返回true,否则返回false。 |
| 12 | isdigit() | 如果字符串只包含数字则返回true,否则返回false。 |
| 13 | islower() | 如果字符串至少包含1个字母,并且所有字符均为小写,则返回true,否则返回false。 |
| 14 | isnumeric() | 如果unicode字符串只包含数字字符,则返回true,否则返回false。 |
| 15 | isspace() | 如果字符串只包含空格字符,则返回true,否则返回false。 |
| 16 | istitle() | 如果字符串正确“标题大小写”,则返回true,否则返回false。 |
| 17 | isupper() | 如果字符串至少包含一个可变大小写字符,并且所有可变大小写字符均为大写,则返回true,否则返回false。 |
| 18 | join(seq) | 将序列seq中的元素以字符串表示合并(并入)到具有分隔符字符串的字符串中。 |
| 19 | len(string) | 返回字符串的长度 |
| 20 | ljust(width[, fillchar]) | 返回一个空格填充的字符串,原始字符串左对齐到总共width列。 |
| 21 | lower() | 将字符串中的所有大写字母转换为小写。 |
| 22 | lstrip() | 删除字符串中的所有前导空格 |
| 23 | maketrans() | 返回在translate函数中使用的转换表。 |
| 24 | max(str) | 从字符串str返回最大字母字符。 |
| 27 | replace(old, new [, max]) | 如果给定max值,则用new或最多最大出现替换字符串中所有出现的旧字符(old)。 |
| 28 | rindex( str, beg = 0, end = len(string)) | 与index()相同,但在字符串中向后搜索。 |
| 29 | rjust(width,[, fillchar]) | 返回一个空格填充字符串,原始字符串右对齐到总共宽度(width)列。 |
| 30 | rstrip() | 删除字符串的所有尾随空格。 |
| 31 | split(str= | 根据分隔符str(空格,如果没有提供)拆分字符串并返回子字符串列表; 如果给定,最多分割为num子串。 |
| 32 | splitlines( num=string.count(‘\n’)))”) | 全部拆分字符串(或num)新行符,并返回每行的列表,并删除新行符。 |
| 33 | startswith(str, beg=0,end=len(string)) | 确定字符串或字符串的子字符串(如果给定起始索引beg和结束索引end)以str开头; 如果是则返回true,否则返回false。 |
| 34 | strip([chars]) | 对字符串执行lstrip()和rstrip() |
| 35 | swapcase() | 反转在字符串中的所有字母大小写,即小写转大写,大写转小写。 |
| 36 | title() | 返回字符串的标题版本,即所有单词第一个字母都以大写开头,其余的都是小写的。 |
| 37 | translate(table, deletechars= | 根据转换表STR(256个字符),除去那些在del字符串转换字符串。 |
| 38 | upper() | 将字符串中的小写字母转换为大写。 |
| 39 | zfill(width) | 返回原始字符串,左边填充为零,总共有宽度(width)字符; 对于数字zfill()保留给定的任何符号(少于一个零)。 |
| 40 | isdecimal() | 如果unicode字符串只包含十进制字符,则返回true,否则返回false。 |
第十节 Python列表
Python中最基本的数据结构是列表。一个列表的每个元素被分配一个数字来表示它的位置或索引。 第一个索引为0,第二个索引为1,依此类推。
Python有六种内置的序列类型,但最常见的是列表和元组,将在本教程中看到。
可以在列表上执行各种类型操作。这些操作包括索引,切片,添加,乘法和检查成员身份。此外,Python还具有内置函数,用于查找序列的长度和查找其最大和最小的元素。
1.Python列表
列表是Python中最通用的数据类型,可以写成方括号之间的逗号分隔值(项)列表。列表中的项目不必是相同的类型,这一点和C语言中数组有差别。
创建列表就在方括号之间放置不同的逗号分隔值。 例如 –
list1 = ['physics', 'chemistry', 1997, 2000];
list2 = [1, 2, 3, 4, 5 ];
list3 = ["a", "b", "c", "d"];
类似于字符串索引,列表索引从0开始,列表可以被切片,连接等等。
2.访问列表中的值
要访问列表中的值,使用方括号进行切片以及索引或索引,以获取该索引处可用的值。例如 –
#!/usr/bin/python3
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5, 6, 7 ]
print ("list1[0]: ", list1[0])
print ("list2[1:5]: ", list2[1:5])
当执行上述代码时,会产生以下结果 –
list1[0]: physics
list2[1:5]: [2, 3, 4, 5]
3.更新列表
可以通过在分配运算符左侧给出切片来更新列表的单个或多个元素,可以使用append()方法添加到列表中的元素。例如 –
#!/usr/bin/python3
list = ['physics', 'chemistry', 1997, 2000]
print ("Value available at index 2 : ", list[2])
list[2] = 2001
print ("New value available at index 2 : ", list[2])
注 – 在后续章节中讨论了
append()方法。
当执行上述代码时,会产生以下结果 –
Value available at index 2 : 1997
New value available at index 2 : 2001
4.删除列表元素
要删除列表元素,并且如果确切知道要删除哪些元素可以使用del语句。如果不知道要删除哪些项目,可以使用remove()方法。 例如 –
#!/usr/bin/python3
list = ['physics', 'chemistry', 1997, 2000]
print (list)
del list[2]
print ("After deleting value at index 2 : ", list)
当执行上述代码时,会产生以下结果 –
['physics', 'chemistry', 1997, 2000]
After deleting value at index 2 : ['physics', 'chemistry', 2000]
注 –
remove()方法将在后续章节中讨论。
基本列表操作
列表响应+和*运算符,这与字符串十分类似; 它们也意味着这里的连接和重复,除了结果是新的列表,而不是字符串。
事实上,列表响应上一章中,在字符串上使用的所有常规序列操作。
| Python表达式 | 结果 | 描述 |
|---|---|---|
len([1, 2, 3]) |
3 | 列表的长度 |
[1, 2, 3] + [4, 5, 6] |
[1, 2, 3, 4, 5, 6] |
联接 |
['Hi!'] * 4 |
['Hi!', 'Hi!', 'Hi!', 'Hi!'] |
重复 |
3 in [1, 2, 3] |
True |
|
for x in [1,2,3] : print (x,end = ' ') |
1 2 3 |
迭代 |
索引,切片和矩阵
由于列表是序列,索引和切片的工作方式与列表一样,对于字符串。
假设以下输入 –
L = ['C++'', 'Java', 'Python']
| Python表达式 | 结果 | 描述 |
|---|---|---|
L[2] |
'Python' |
偏移量,从零开始 |
L[-2] |
'Java' |
负数:从右到右 |
L[1:] |
['Java', 'Python'] |
切片提取部分 |
内置列表函数和方法
Python包括以下列表函数功能 –
| 编号 | 方法 | 描述 |
|---|---|---|
| 1 | cmp(list1, list2) | 在Python 3中不再可用。 |
| 2 | len(list) | 给出列表的总长度。 |
| 3 | max(list) | 从列表中返回最大值的项目。 |
| 4 | min(list) | 从列表中返回最小值的项目。 |
| 5 | list(seq) | 将元组转换为列表。 |
Python包括以下列表方法 –
| 编号 | 方法 | 描述 |
|---|---|---|
| 1 | list.append(obj) | 将对象obj追加到列表中 |
| 2 | list.count(obj) | 返回列表中出现多少次obj的计数 |
| 3 | list.extend(seq) | 返回列表中出现多少次obj的计数 |
| 4 | list.extend(seq) | 将seq的内容附加到列表中 |
| 5 | list.insert(index, obj) | 将对象obj插入到偏移索引的列表中 |
| 6 | list.pop(obj = list[-1]) | 从列表中删除并返回最后一个对象或obj |
| 7 | list.remove(obj) | 从列表中删除对象obj |
| 8 | list.reverse() | 反转列表中的对象 |
| 9 | list.sort([func]) | 排序列表的对象,如果给出,则使用比较函数func来排序 |
第十一节 Python元组
元组是一系列不可变的Python对象。元组是一种序列,就像列表一样。元组和列表之间的主要区别是元组不能像列表那样改变元素的值,可以简单地理解为“只读列表”。 元组使用小括号 – (),而列表使用方括号 – [] 。
创建一个元组只需使用逗号分隔值放入小括号的一个序列。 或者,也可以将这些逗号分隔值放在括号之间。 例如 –
tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = (1, 2, 3, 4, 5 )
tup3 = "a", "b", "c", "d"
空的元组写成两个不含任何东西的小括号 –
tup1 = ();
要编写一个包含单个值的元组,必须包含一个逗号,即使只有一个值(这是规范写法) –
tup1 = (50,)
## 也可以这样写
tup2 = (50)
1.访问元组中的值
要访问元组中的值,请使用方括号进行指定索引切片或索引,以获取该索引处的值。 例如 –
#!/usr/bin/python3
tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7 )
print ("tup1[0]: ", tup1[0])
print ("tup2[1:5]: ", tup2[1:5])
当执行上述代码时,会产生以下结果 –
tup1[0]: physics
tup2[1:5]: (2, 3, 4, 5)
2.更新元组
元组是不可变的,这意味着我们无法更新或更改元组元素的值。 但是可以使用现有元组的一部分来创建新的元组,如下例所示:
#!/usr/bin/python3
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# Following action is not valid for tuples
# tup1[0] = 100;
# So let's create a new tuple as follows
tup3 = tup1 + tup2
print (tup3)
当执行上述代码时,会产生以下结果 –
(12, 34.56, 'abc', 'xyz')
3.删除元组元素
删除单个元组元素是不可能的。 当然,将不必要的元素放在另一个元组中也没有什么错。
要显式删除整个元组,只需使用del语句。 例如 –
#!/usr/bin/python3
tup = ('physics', 'chemistry', 1997, 2000);
print (tup)
del tup;
print "After deleting tup : "
print (tup)
执行上面代码,将产生以下结果 –
注 – 引发异常。这是因为在
del tup之后,元组不再存在。
('physics', 'chemistry', 1997, 2000)
After deleting tup :
Traceback (most recent call last):
File "test.py", line 9, in <module>
print tup;
NameError: name 'tup' is not defined
4.基本元组操作
元组响应+和*运算符很像字符串; 它们执行连接和重复操作,但结果是一个新的元组,而不是一个字符串。
事实上,元组中类似字符串操作和使用的所有常规序列操作都有作了讲解。
| Python表达式 | 结果 | 描述 |
|---|---|---|
len((1, 2, 3)) |
3 |
长度 |
(1, 2, 3) + (4, 5, 6) |
(1, 2, 3, 4, 5, 6) |
连接操作 |
('Hi!',) * 4 |
('Hi!', 'Hi!', 'Hi!', 'Hi!') |
重复 |
3 in (1, 2, 3) |
True |
成员关系 |
for x in (1,2,3) : print (x, end = ' ') |
1 2 3 |
迭代 |
5.索引,切片和矩阵
由于元组是序列,索引和切片的工作方式与列表的工作方式相同,假设输入以下值:
T=('C++', 'Java', 'Python')
那么 –
| Python表达式 | 结果 | |
|---|---|---|
T[2] |
'Python' |
偏移量,从零开始 |
T[-2] |
'Java' |
负数:从右到左 |
T[1:] |
('Java', 'Python') |
切片提取部分 |
6.内置元组函数功能
Python包括以下元组函数 –
| 编号 | 函数 | 描述 |
|---|---|---|
| 1 | cmp(tuple1, tuple2) | 比较两个元组的元素。 |
| 2 | len(tuple) | 给出元组的总长度。 |
| 3 | max(tuple) | 从元组返回最大值项。 |
| 4 | min(tuple) | 从元组返回最大值项 |
| 5 | tuple(seq) | 将列表转换为元组。 |
第十二节 Python字典
每个键与其值使用一个冒号(:)分开,这些键-值对是使用逗号分隔的,整个字典项目用大括号括起来。 没有任何项目的空字典只用两个花括号写成:{}
键在字典中是唯一的,而值可以不必是唯一的。字典的值可以是任何类型的,但是键必须是不可变的数据类型,例如字符串,数字或元组。
1.访问字典中的值
要访问字典元素,可以使用熟悉的中括号以及键来获取其值。 以下是一个简单的例子 –
#!/usr/bin/python3
dict = {'Name': 'Maxsu', 'Age': 7, 'Class': 'First'}
print ("dict['Name']: ", dict['Name'])
print ("dict['Age']: ", dict['Age'])
当执行上述代码时,会产生以下结果 –
dict['Name']: Maxsu
dict['Age']: 7
如果尝试使用键(不是字典的一部分)访问数据项,会收到以下错误,如下示例 –
#!/usr/bin/python3
dict = {'Name': 'Maxsu', 'Age': 7, 'Class': 'First'}
print ("dict['Minsu']: ", dict['Minsu'])
当执行上述代码时,会产生以下结果 –
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Minsu'
2.更新字典
可以通过添加新数据项或键值对,修改现有数据项或删除现有数据项来更新字典,如下面给出的简单示例所示。
#!/usr/bin/python3
dict = {'Name': 'Maxsu', 'Age': 7, 'Class': 'First'}
dict['Age'] = 8; # update existing entry
dict['School'] = "DPS School" # Add new entry
print ("dict['Age']: ", dict['Age'])
print ("dict['School']: ", dict['School'])
当执行上述代码时,会产生以下结果 –
dict['Age']: 8
dict['School']: DPS School
3.删除词典元素
可以删除单个字典元素或清除字典的全部内容。也可以在单个操作中删除整个字典。
要显式删除整个字典,只需使用del语句。 以下是一个简单的例子 –
#!/usr/bin/python3
dict = {'Name': 'Maxsu', 'Age': 7, 'Class': 'First'}
del dict['Name'] # remove entry with key 'Name'
dict.clear() # remove all entries in dict
del dict # delete entire dictionary
print ("dict['Age']: ", dict['Age'])
print ("dict['School']: ", dict['School'])
这产生以下结果:程序抛出了一个例外,因为在执行del dict之后,字典不再存在。
print ("dict['Age']: ", dict['Age'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'type' object is not subscriptable
>>> print ("dict['School']: ", dict['School'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'type' object is not subscriptable
注 –
del()方法将在后续章节中讨论。
4. 字典键的属性
字典值没有限制。它们可以是任意任意的Python对象,标准对象或用户定义的对象。 但是,对于键来说也是如此。
关于字典的键有两个要点:
(a). 不允许每键多于数据值。这意味着不允许重复的键。 在分配过程中遇到重复键时,则以最后一个赋值为准。 例如 –
#!/usr/bin/python3
dict = {'Name': 'Maxsu', 'Age': 7, 'Name': 'Minlee'}
print ("dict['Name']: ", dict['Name'])
当执行上述代码时,会产生以下结果 –
dict['Name']: Minlee
(b). 键必须是不可变的。 这意味着可以使用字符串,数字或元组作为字典键,但不允许使用['key']。 以下是一个简单的例子 –
#!/usr/bin/python3
dict = {['Name']: 'Maxsu', 'Age': 7}
print ("dict['Name']: ", dict['Name'])
当执行上述代码时,会产生以下结果 –
Traceback (most recent call last):
File "test.py", line 3, in <module>
dict = {['Name']: 'Maxsu', 'Age': 7}
TypeError: list objects are unhashable
5.内置词典函数和方法
Python包括以下字典函数 –
| 编号 | 函数 | 描述 |
|---|---|---|
| 1 | cmp(dict1, dict2) | 在Python 3中不再可用。 |
| 2 | len(dict) | 计算出字典的总长度。它将等于字典中的数据项数目。 |
| 3 | str(dict) | 生成字典的可打印字符串表示形式 |
| 4 | type(variable) | 返回传递变量的类型。如果传递变量是字典,那么它将返回一个字典类型。 |
Python包括以下字典方法 –
| 编号 | 函数 | 描述 |
|---|---|---|
| 1 | dict.clear() | 删除字典dict的所有元素 |
| 2 | dict.copy() | 返回字典dict的浅拷贝 |
| 3 | dict.fromkeys() | 创建一个新的字典,其中包含seq的值和设置为value的值。 |
| 4 | dict.get(key, default=None) | 对于键(key)存在则返回其对应值,如果键不在字典中,则返回默认值 |
| 5 | dict.has_key(key) | 此方法已删除,使用in操作符代替 |
| 6 | dict.items() | 返回字典dict的(key,value)元组对的列表 |
| 7 | dict.keys() | 返回字典dict的键列表 |
| 8 | dict.setdefault(key, default = None) | 类似于get(),如果key不在字典dict中,则将执行赋值操作:dict [key] = default |
| 9 | dict.update(dict2) | 将字典dict2的键值对添加到字典dict |
| 10 | dict.values() | 返回字典dict的值列表 |
第十三节 Python日期和时间
Python程序可以通过多种方式处理日期和时间。日期格式之间的转换是计算机常见问题。Python的时间(time)和日历(calendar)模块可用于跟踪日期和时间。
一些常用代码示例
- 获取当前时间和日期,如:2018-08-18 12:12:00
- 计算两个日期相差天数
- 计算程序运行的时间
#!/usr/bin/python3
#coding=utf-8
import time
import datetime
starttime = datetime.datetime.now()
time.sleep(5)
endtime = datetime.datetime.now()
print ((endtime - starttime).seconds )
- 计算十天之后的日期时间
#!/usr/bin/python3
#coding=utf-8
import time
import datetime
d1 = datetime.datetime.now()
d3 = d1 + datetime.timedelta(days =10)
print (str(d3))
print (d3.ctime())
- 获取两个日期时间的时间差
t = (datetime.datetime(2019,1,13,12,0,0) - datetime.datetime.now()).total_seconds()
print ("t = ", t)
## 输出结果
t = 49367780.076406
Python中有提供与日期和时间相关的4个模块。它们分别是 –
| 模块 | 说明 |
|---|---|
time |
time是一个仅包含与日期和时间相关的函数和常量的模块,在本模块中定义了C/C++编写的几个类。 例如,struct_time类。 |
datetime |
datetime是一个使用面向对象编程设计的模块,可以在Python中使用日期和时间。它定义了几个表示日期和时间的类。 |
calendar |
日历是一个提供函数的模块,以及与Calendar相关的几个类,它们支持将日历映像生成为text,html,…. |
locale |
该模块包含用于格式化或基于区域设置分析日期和时间的函数。 |
1. 时间间隔
时间间隔是以秒为单位的浮点数。 从1970年1月1日上午12:00(epoch),这是一种时间的特殊时刻表示。
在Python中,当前时刻与上述特殊的某个时间点之间以秒为单位的时间。这个时间段叫做Ticks。

time模块中的time()函数返回从1970年1月1日上午12点开始的秒数。
# Import time module.
import time;
# Seconds
ticks = time.time()
print ("Number of ticks since 12:00am, January 1, 1970: ", ticks)
执行上面代码,得到以下结果 –
Number of ticks since 12:00am, January 1, 1970: 1497970093.6243818
但是,这个形式不能表示在时代(1970年1月1日上午12:00)之前的日期。在未来的日子也不能以这种方式表示 – 截止点是在2038年的UNIX和Windows的某个时刻。
2. 什么是TimeTuple?
许多Python时间函数将时间处理为9个数字的元组,如下所示:
| 索引 | 字段 | 值 |
|---|---|---|
| 0 | 4位数,表示年份 |
2018,2019… |
| 1 | 月份 | 1 ~ 12 |
| 2 | 日期 | 1 ~ 31 |
| 3 | 小时 | 0 ~ 23 |
| 4 | 分钟 | 0 ~ 59 |
| 5 | 秒 | 0 ~ 61(60或61是闰秒) |
| 6 | 星期几 | 0 ~ 6(0是星期一) |
| 7 | 一年的第几天 | 1 ~ 366(朱利安日) |
| 8 | 夏令时 | -1,0,1,-1表示库确定DST |
一个示例
import time
print (time.localtime());
这将产生如下结果:
time.struct_time(tm_year = 2016, tm_mon = 2, tm_mday = 15, tm_hour = 9,
tm_min = 29, tm_sec = 2, tm_wday = 0, tm_yday = 46, tm_isdst = 0)
上面的元组相当于struct_time结构。此结构具有以下属性 –
| 索引 | 字段 | 值 |
|---|---|---|
| 0 | tm_year | 2018,2019… |
| 1 | tm_mon | 1 ~ 12 |
| 2 | tm_mday | 1 ~ 31 |
| 3 | tm_hour | 0 ~ 23 |
| 4 | tm_min | 0 ~ 59 |
| 5 | tm_sec | 0 ~ 61(60或61是闰秒) |
| 6 | tm_wday | 0 ~ 6(0是星期一) |
| 7 | tm_yday | 1 ~ 366(朱利安日) |
| 8 | tm_isdst | -1,0,1,-1表示库确定DST |
能用图片说明白的尽量用图片说明 –
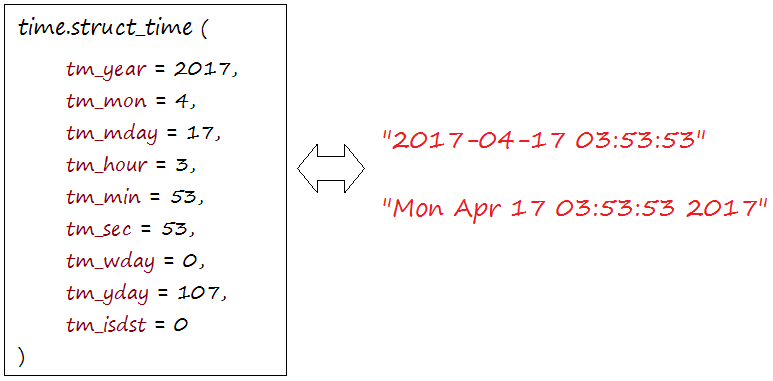
2.1.获取当前时间
要将从时间浮点值开始的秒数瞬间转换为时间序列,将浮点值传递给返回具有所有有效九个项目的时间元组的函数(例如本地时间)。
#!/usr/bin/python3
import time
localtime = time.localtime(time.time())
print ("Local current time :", localtime)
# 当前时间
curtime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print (curtime)
执行上面代码,这将产生如下结果 –
Local current time : time.struct_time(tm_year=2017, tm_mon=6, tm_mday=20, tm_hour=23,
tm_min=9, tm_sec=36, tm_wday=1, tm_yday=171, tm_isdst=0)
Curtime is => 2017-06-20 23:09:36
2.2.获取格式化时间
可以根据需要格式化任何时间,但也可使用可读格式获取时间的简单方法是 – asctime() –
#!/usr/bin/python3
import time
localtime = time.asctime( time.localtime(time.time()) )
print ("Local current time :", localtime)
执行上面代码,这将产生如下结果 –
Local current time : Mon Feb 15 10:32:13 2018
2.3.获取一个月的日历
calendar模块提供了广泛的方法来显示年历和月度日历。 在这里,将打印一个给定月份的日历(2021年11月) –
#!/usr/bin/python3
import calendar
cal = calendar.month(2021, 11)
print ("Here is the calendar:")
print (cal)
执行上面代码后,将输出以下结果 –
November 2021
Mo Tu We Th Fr Sa Su
1 2 3 4 5 6 7
8 9 10 11 12 13 14
15 16 17 18 19 20 21
22 23 24 25 26 27 28
29 30
3.时间模块
Python中有一个受欢迎的时间(time)模块,它提供了处理时间和表示之间转换的功能。以下是所有时间(time)可用方法的列表。
| 编号 | 方法 | 描述 |
|---|---|---|
| 1 | time.altzone | 本地DST时区的偏移量(以秒为单位的UTC),如果定义了有一个定义的话。 如果本地的DST时区是UTC的东部(如在西欧,包括英国),那么它是负数值。 |
| 2 | time.asctime([tupletime]) | 接受时间元组,并返回一个可读的24个字符的字符串,例如’Tue Dec 11 22:07:14 2019’。 |
| 3 | time.clock( ) | 将当前CPU时间返回为浮点数秒。 为了测量不同方法的计算成本,time.clock的值比time.time()的值更有用。 |
| 4 | time.ctime([secs]) | 类似于asctime(localtime(secs)),而没有参数就像asctime() |
| 5 | time.gmtime([secs]) | 接受从时代(epoch)以秒为单位的瞬间,并返回与UTC时间相关的时间元组t。 注 – t.tm_isdst始终为0 |
| 6 | time.localtime([secs]) | 接受从时代(epoch)以秒为单位的瞬间,并返回与本地时间相关的时间t(t.tm_isdst为0或1,具体取决于DST是否适用于本地规则的瞬时秒)。 |
| 7 | time.mktime(tupletime) | 接受在本地时间表示为时间元组的瞬间,并返回浮点值,该时间点以秒为单位表示。 |
| 8 | time.sleep(secs) | 暂停调用线程secs秒。 |
| 9 | time.strftime(fmt[,tupletime]) | 接受在本地时间表示为时间元组的瞬间,并返回一个表示由字符串fmt指定的时间的字符串。 |
| 10 | time.strptime(str,fmt = ‘%a %b %d %H:%M:%S %Y’)“) | 根据格式字符串fmt解析str,并返回时间元组格式的时间。 |
| 11 | time.time( ) | 返回当前时间时刻,即从时代(epoch)开始的浮点数秒数。 |
| 12 | time.tzset() | 重置库例程使用的时间转换规则。环境变量TZ指定如何完成。 |
时间(time)模块有两个重要的属性可用。它们是 –
| 编号 | 属性 | 描述 |
|---|---|---|
| 1 | time.timezone |
属性time.timezone是UTC和本地时区(不含DST)之间的偏移量(美洲为 > 0,欧洲,亚洲,非洲大部分地区为 0)。 |
| 2 | time.tzname |
属性time.tzname是一对与区域相关的字符串,它们分别是没有和具有DST的本地时区的名称。 |
4.日历模块
calendar模块提供与日历相关的功能,包括为给定的月份或年份打印文本日历的功能。
默认情况下,日历将星期一作为一周的第一天,将星期日作为最后一天。 如果想要更改这个,可调用calendar.setfirstweekday()函数设置修改。
以下是calendar模块可用的功能函数列表 –
| 编号 | 函数 | 描述 |
|---|---|---|
| 1 | calendar.calendar(year,w = 2,l = 1,c = 6) |
返回一个具有年份日历的多行字符串格式化为三列,以c个空格分隔。 w是每个日期的字符宽度; 每行的长度为21 * w + 18 + 2 * c,l是每周的行数。 |
| 2 | calendar.firstweekday( ) |
返回当前设置每周开始的星期。默认情况下,当日历首次导入时设置为:0,表示为星期一。 |
| 3 | calendar.isleap(year) |
如果给定年份(year)是闰年则返回True; 否则返回:False。 |
| 4 | calendar.leapdays(y1,y2) |
返回在范围(y1,y2)内的年份中的闰年总数。 |
| 5 | calendar.month(year,month,w = 2,l = 1) |
返回一个多行字符串,其中包含年份月份的日历,每周一行和两个标题行。 w是每个日期的字符宽度; 每行的长度为7 * w + 6。 l是每周的行数。 |
| 6 | calendar.monthcalendar(year,month) |
返回int类型的列表。每个子列表表示一个星期。年份月份以外的天数设置为0; 该月内的日期设定为月份的第几日:1 ~ 31。 |
| 7 | calendar.monthrange(year,month) |
返回两个整数。第一个是年度月(month)的星期几的代码; 第二个是当月的天数。表示星期几为0(星期一)至6(星期日); 月份是1到12。 |
| 8 | calendar.prcal(year,w = 2,l = 1,c = 6) |
类似于:calendar.calendar(year,w,l,c)的打印。 |
| 9 | calendar.prmonth(year,month,w = 2,l = 1) |
类似于:calendar.month(year,month,w,l)的打印。 |
| 10 | calendar.setfirstweekday(weekday) |
将每周的第一天设置为星期几的代码。 星期几的代码为0(星期一)至6(星期日)。 |
| 11 | calendar.timegm(tupletime) |
time.gmtime的倒数:以时间元组的形式接受时刻,并返回与从时代(epoch)开始的浮点数相同的时刻。 |
| 12 | calendar.weekday(year,month,day) |
返回给定日期的星期几的代码。星期几的代码为0(星期一)至6(星期日); 月数是1(1月)到12(12月)。 |
5.其他模块和功能
如果您有兴趣,那么可以在Python中找到其他重要的模块和功能列表,其中包含日期和时间。以下列出其它有用的模块 –
datetime模块pytz模块dateutil模块
第十四节 Python函数
函数是一个有组织,可重复使用的代码块,用于执行单个相关操作。 函数为应用程序提供更好的模块化和高度的代码重用。
我们知道,Python中也有给很多内置的函数,如print()等,但用户也可以创建自己的函数。这样的函数称为用户定义函数。
1.定义函数
可以定义提供所需函数的功能。 以下是在Python中定义函数的简单规则。
- 函数块以关键字
def开头,后跟函数名和小括号(())。 - 任何输入参数或参数应放置在这些小括号中。也可以在这些小括号内定义参数。
- 每个函数中的代码块以冒号(
:)开始,并缩进。 - 函数内的第一个语句可以是可选语句 – 函数的文档或
docstring字符串。 - 语句
return [expression]用于退出一个函数,可选地将一个表达式传回给调用者。如果没有使用参数的return语句,则它与return None相同。
语法
def functionname( parameters ):
"function_docstring"
function_suite
return [expression]
默认情况下,参数具有位置行为,您需要按照定义的顺序通知它们或调用它们。
示例
以下函数将字符串作为输入参数,并在标准屏幕上打印参数的值。
def printme( str ):
"This prints a passed string into this function"
print (str)
return
2.调用函数
定义一个函数需要为它起一个名字,指定要包括在函数中的参数并构造代码块。
当函数的基本结构完成,可以通过从另一个函数调用它或直接从Python提示符执行它。 以下是一个调用print_str()函数的例子 –
#!/usr/bin/python3
# Function definition is here
def print_str( str ):
"This prints a passed string into this function"
print (str)
return
# Now you can call print_str function
print_str("This is first call to the user defined function!")
print_str("Again second call to the same function")
当执行上述代码时,会产生以下结果 –
This is first call to the user defined function!
Again second call to the same function
3.通过引用与通过值传递
Python语言中的所有参数(参数)都将通过引用传递。如果在函数中更改参数所指的内容,则更改也会反映在调用函数的外部。 例如 –
#!/usr/bin/python3
# Function definition is here
def changeme( mylist ):
"This changes a passed list into this function"
print ("Values inside the function before change: ", mylist)
mylist[2]=50
print ("Values inside the function after change: ", mylist)
return
# Now you can call changeme function
mylist = [10,20,30]
changeme( mylist )
print ("Values outside the function: ", mylist)
在这里,将保持对传递对象的引用并在相同的对象中赋值。 因此,这将产生以下结果 –
Values inside the function before change: [10, 20, 30]
Values inside the function after change: [10, 20, 50]
Values outside the function: [10, 20, 50]
在上面的输出结果中,可以清楚地看到,mylist[2]的值原来只在函数内赋了一个值:50,但在函数外部的最后一个语句打出来的值是:50,这说明更改也会反映在调用函数的外部。
还有一个例子:参数通过引用传递,引用在被调用函数内被覆盖。
#!/usr/bin/python3
#coding=utf-8
# Function definition is here
def changeme( mylist ):
"This changes a passed list into this function"
mylist = [1,2,3,4] # This would assi new reference in mylist
print ("Values inside the function: ", mylist)
return
# Now you can call changeme function
mylist = [10,20,30]
changeme( mylist )
print ("Values outside the function: ", mylist)
参数mylist是changeme()函数的局部变量。在函数中更改mylist不影响mylist的值。函数执行完成后,最终将产生以下结果 –
Values inside the function: [1, 2, 3, 4]
Values outside the function: [10, 20, 30]
4.函数参数
可以使用以下类型的形式参数来调用函数 –
- 必需参数
- 关键字参数
- 默认参数
- 可变长度参数
4.1.必需参数
必需参数是以正确的位置顺序传递给函数的参数。这里,函数调用中的参数数量应与函数定义完全一致。
如下示例中,要调用printme()函数,则必需要传递一个参数,否则会出现如下语法错误 –
#!/usr/bin/python3
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print (str)
return
# 现在要调用函数,但不提供参数
printme()
当执行上述代码时,会产生以下结果 –
Traceback (most recent call last):
File "test.py", line 11, in <module>
printme();
TypeError: printme() takes exactly 1 argument (0 given)
提示:在调用
printme()函数时,提供一个参数就可以了。如:printme('Maxsu')。
4.2.关键字参数
关键字参数与函数调用有关。 在函数调用中使用关键字参数时,调用者通过参数名称来标识参数。
这允许跳过参数或将其置于无序状态,因为Python解释器能够使用提供的关键字将值与参数进行匹配。还可以通过以下方式对printme()函数进行关键字调用 –
#!/usr/bin/python3
#coding=utf-8
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print (str)
return
# Now you can call printme function
printme( str = "My string")
当执行上述代码时,会产生以下结果 –
My string
以下示例给出了更清晰的映射。请注意,参数的顺序并不重要。
#!/usr/bin/python3
#coding=utf-8
# Function definition is here
def printinfo( name, age ):
"This prints a passed info into this function"
print ("Name: ", name, "Age: ", age)
return
# Now you can call printinfo function
printinfo( age = 25, name = "Maxsu" )
printinfo(name = "Minsu", age = 26 )
当执行上述代码时,会产生以下结果 –
Name: Maxsu Age: 25
Name: Minsu Age: 26
4.3.默认参数
如果在该参数的函数调用中没有提供值,则默认参数是一个假设为默认值的参数。 以下示例给出了默认参数的想法,如果未通过,则打印默认年龄(age) –
#!/usr/bin/python3
#coding=utf-8
# Function definition is here
def printinfo( name, age = 25 ):
"This prints a passed info into this function"
print ("Name: ", name, "Age ", age)
return
# Now you can call printinfo function
printinfo( age = 22, name = "Maxsu" )
printinfo( name = "Minsu" )
当执行上述代码时,会产生以下结果 –
Name: Maxsu Age 22
Name: Minsu Age 25
4.4.可变长度参数
在定义函数时,可能需要处理更多参数的函数。这些参数被称为可变长度参数,并且不像要求的和默认的参数那样在函数定义中命名。
具有非关键字变量参数的函数的语法如下:
def functionname([formal_args,] *var_args_tuple ):
"function_docstring"
function_suite
return [expression]
星号(*)放在保存所有非关键字变量参数值的变量名之前。 如果在函数调用期间没有指定额外的参数,则此元组保持为空。以下是一个简单的例子 –
#!/usr/bin/python3
#coding=utf-8
# Function definition is here
def printinfo( arg1, *vartuple ):
"This prints a variable passed arguments"
print ("Output is: ", arg1)
for var in vartuple:
print (var, )
return
# Now you can call printinfo function
printinfo( 10 )
printinfo( 70, 60, 50 )
当执行上述代码时,会产生以下结果 –
Output is: 10
Output is: 70
60
50
5.匿名函数
这些函数被称为匿名的,因为它们没有使用def关键字以标准方式声明。可以使用lambda关键字创建小型匿名函数。
Lambda表单可以接受任意数量的参数,但只能以表达式的形式返回一个值。它们不能包含命令或多个表达式。- 匿名函数不能直接调用打印,因为
lambda需要一个表达式。 Lambda函数有自己的本地命名空间,不能访问其参数列表和全局命名空间中的变量。- 虽然
lambdas是一个单行版本的函数,但它们并不等同于C或C++中的内联语句,其目的是通过传递函数来进行堆栈分配。
语法
lambda函数的语法只包含一个语句,如下所示:
lambda [arg1 [,arg2,.....argn]]:expression
以下是一个示例,以显示lambda形式的函数如何工作 –
#!/usr/bin/python3
# Function definition is here
sum = lambda arg1, arg2: arg1 + arg2
# Now you can call sum as a function
print ("Value of total : ", sum( 10, 20 ))
print ("Value of total : ", sum( 20, 20 ))
当执行上述代码时,会产生以下结果 –
Value of total : 30
Value of total : 40
6.return语句
return [expression]语句退出一个函数,可选地将一个表达式传回给调用者。没有参数的return语句与return None相同。
下面给出的所有例子都没有返回任何值。可以从函数返回值,如下所示:
#!/usr/bin/python3
#coding=utf-8
# Function definition is here
def sum( arg1, arg2 ):
# Add both the parameters and return them."
total = arg1 + arg2
print ("Inside the function : ", total)
return total
# Now you can call sum function
total = sum( 10, 20 )
print ("Outside the function : ", total )
全部执行上述代码时,会产生以下结果 –
Inside the function : 30
Outside the function : 30
7.变量范围
程序中的所有变量在该程序的所有位置可能无法访问。这取决于在哪里声明一个变量。变量的范围决定了可以访问特定标识符的程序部分。Python中有两个变量的基本范围 –
- 全局变量
- 局部变量
8.全局与局部变量
在函数体内定义的变量具有局部作用域,外部定义的变量具有全局作用域。
局部变量只能在它们声明的函数内部访问,而全局变量可以通过所有函数在整个程序体中访问。 当调用一个函数时,它内部声明的变量被带入范围。 以下是一个简单的例子 –
total = 0 # This is global variable.
# Function definition is here
def sum( arg1, arg2 ):
# Add both the parameters and return them."
total = arg1 + arg2; # Here total is local variable.
print ("Inside the function local total : ", total)
return total
# Now you can call sum function
sum( 10, 20 )
print ("Outside the function global total : ", total )
当执行上述代码时,会产生以下结果 –
Inside the function local total : 30
Outside the function global total : 0
第十五节 Python模块
模块允许逻辑地组织Python代码。 将相关代码分组到一个模块中,使代码更容易理解和使用。 模块是一个具有任意命名属性的Python对象,可以绑定和引用。
简单来说,模块是一个由Python代码组成的文件。模块可以定义函数,类和变量。 模块还可以包括可运行的代码。
示例
下面是一个名称为aname的模块的Python代码通常位于一个名称为aname.py的文件中。以下是一个简单模块的例子:support.py –
def print_func( par ):
print "Hello : ", par
return
1.import语句
可以通过在其他Python源文件中执行import语句来将任何Python源文件用作模块。导入具有以下语法 –
import module1[, module2[,... moduleN]
当解释器遇到导入语句时,如果模块存在于搜索路径中,则导入该模块。搜索路径是导入模块之前解释器搜索的目录的列表。例如,要导入模块hello.py,需要将以下命令放在脚本的顶部 –
#!/usr/bin/python3
# Import module support
import support
# Now you can call defined function that module as follows
support.print_func("Maxsu")
当执行上述代码时,会产生以下结果 –
Hello : Maxsu
不管模块被导入多少次,模块只能加载一次。这样可以防止模块执行重复发生,如果有多个导入。
2.from…import语句
Python from语句允许将模块中的特定属性导入到当前的命名空间中。 from...import具有以下语法 –
from modname import name1[, name2[, ... nameN]]
例如,要从模块 fib 导入函数fibonacci,请使用以下语句 –
#!/usr/bin/python3
# Fibonacci numbers module
def fib(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a + b
return result
>>> from fib import fib
>>> fib(100)
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
此语句不会将整个模块fib导入到当前命名空间中; 它只是将fibonacci从模块fib引入导入模块的全局符号表。
3.from…import *语句
也可以使用以下import语句将模块中的所有名称导入到当前命名空间中 –
from modname import *
这提供了将所有项目从模块导入到当前命名空间中的简单方法; 但是,这个说法应该谨慎使用。
4.执行模块作为脚本
在模块中,模块的名称(作为字符串)可用作全局变量__name__的值。模块中的代码将被执行,就像您导入它一样,但是__name__设置为“__main__”。
在模块的最后添加这个代码 –
#!/usr/bin/python3
# Fibonacci numbers module
def fib(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a + b
return result
if __name__ == "__main__":
f = fib(100)
print(f)
运行上述代码时,将显示以下输出。
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
5.定位模块
当导入模块时,Python解释器将按以下顺序搜索模块 –
- 当前目录。
- 如果没有找到该模块,Python会在shell变量
PYTHONPATH中搜索每个目录。 - 如果其他所有失败,Python将检查默认路径。 在UNIX上,此默认路径通常是
/usr/local/lib/python3/或者/usr/sbin/
模块搜索路径作为sys.path变量存储在系统模块sys中。sys.path变量包含当前目录PYTHONPATH和依赖于安装的默认值。
6.PYTHONPATH变量
PYTHONPATH是一个环境变量,由目录列表组成。 PYTHONPATH的语法与shell变量`PATH“`的语法相同。
这是一个典型的Windows系统上的PYTHONPATH –
set PYTHONPATH = c:\python34\lib;
这里是UNIX系统的典型PYTHONPATH –
set PYTHONPATH = /usr/local/lib/python
7.命名空间和范围
变量是映射到对象的名称(标识符)。 命名空间是变量名(键)及其对应对象(值)的字典。
- Python语句可以访问本地命名空间和全局命名空间中的变量。如果本地和全局变量具有相同的名称,则局部变量会影响全局变量。
- 每个函数都有自己的本地命名空间。 类方法遵循与普通函数相同的范围规则。
- Python对于变量是本地还是全局都进行了有根据的判断。它假定在函数中分配值的任何变量都是本地的。
- 因此,为了将值分配给函数内的全局变量,必须首先使用
global语句。 - 语句
global VarName告诉PythonVarName是一个全局变量。Python停止搜索本地命名空间的变量。
例如,在全局命名空间中定义一个变量Money。 在函数Money中为Money赋值,因此Python将Money作为局部变量。
但是,如果在设置之前就访问了本地变量Money的值,它会产生一个错误:UnboundLocalError。 这里可以通过取消注释global语句来解决问题。如下示例代码 –
#!/usr/bin/python3
Money = 2000
def AddMoney():
# Uncomment the following line to fix the code:
# global Money
Money = Money + 1
print (Money)
AddMoney()
print (Money)
8.dir( )函数
dir()内置函数返回一个包含由模块定义的名称的字符串的排序列表。这个列表包含模块中定义的所有模块,变量和函数的名称。 以下是一个简单的例子 –
#!/usr/bin/python3
# Import built-in module math
import time
content = dir(time)
print (content)
当执行上述代码时,会产生以下结果 –
['_STRUCT_TM_ITEMS', '__doc__', '__loader__', '__name__', '__package__', '__spec__',
'altzone', 'asctime', 'clock', 'ctime', 'daylight', 'get_clock_info', 'gmtime',
'localtime', 'mktime', 'monotonic', 'perf_counter', 'process_time', 'sleep',
'strftime', 'strptime', 'struct_time', 'time', 'timezone', 'tzname']
这里,特殊的字符串变量__name__是模块的名称,__file__是加载模块的文件名。
9.globals()和locals()函数
globals()和locals()函数可用于返回全局和本地命名空间中的名称,具体取决于它们被调用的位置。
- 如果
locals()从一个函数中调用,它将返回从该函数本地访问的所有名称。 - 如果从函数中调用
globals(),它将返回从该函数全局访问的所有名称。
这两个函数的返回类型是字典。 因此,可以使用keys()函数提取名称。
10.reload()函数
当将模块导入到脚本中时,模块的顶级部分的代码只能执行一次。
因此,如果要重新执行模块中的顶级代码,可以使用reload()函数。reload()函数再次导入以前导入的模块。 reload()函数的语法是这样的 –
reload(module_name)
这里,module_name是要重新加载的模块的名称,而不是包含模块名称的字符串。 例如,要重新加载hello模块,请执行以下操作 –
reload(hello)
11.Python中的包
Python中的包是一个分层文件目录结构,它定义了一个由模块和子包和子子包组成的Python应用程序环境,等等。
在package目录中创建两个目录:pkg和pkg2, 然后分别在这两个目录中创建两个文件:a.py和b.py。该文件具有以下一行源代码 –
文件: pkg/a.py –
#!/usr/bin/python3
#coding=utf-8
# save file: pkg/a.py
def fun():
print ("I'm pkg.a.fun() ")
文件: pkg/b.py –
#!/usr/bin/python3
#coding=utf-8
# save file: pkg/b.py
def fun():
print ("I'm pkg.b.fun() ")
文件: pkg2/a.py –
#!/usr/bin/python3
#coding=utf-8
# save file: pkg2/a.py
def fun():
print ("I'm pkg2.a.fun() ")
文件: pkg2/b.py –
#!/usr/bin/python3
#coding=utf-8
# save file: pkg2/b.py
def fun():
print ("I'm pkg2.b.fun() ")
在package目录中创建一个主程序文件:main.py,用于演示如何调用包中的各个文件 –
#!/usr/bin/python3
#coding=utf-8
# save file: phone/pots.py
import pkg.a as a
import pkg.b as b
import pkg2.a as a2
import pkg2.b as b2
a.fun()
b.fun()
a2.fun()
b2.fun()
import pkg2.a
import pkg2.b
print('----------- another way -----------------')
pkg2.a.fun()
pkg2.b.fun()
整个代码的目录如下所示 –
package
|- pkg
|- __init__.py
|- a.py
|- b.py
|- pkg2
|- __init__.py
|- a.py
|- b.py
当执行上述代码时,会产生以下结果 –
I'm pkg.a.fun()
I'm pkg.b.fun()
I'm pkg2.a.fun()
I'm pkg2.b.fun()
----------- another way -----------------
I'm pkg2.a.fun()
I'm pkg2.b.fun()
在上面的例子中,将每个文件中的一个函数作为示例,但是可以在文件中编写多个函数。还可以在这些文件中定义不同的Python类,然后可以使用这些类来创建包。
第十六节 Python文件读写
在本章中将介绍Python 3中可用的所有基本文件读取I/O功能。有关更多功能,请参考标准Python文档。
打印到屏幕
产生输出的最简单方法是使用print语句,可以传递零个或多个由逗号分隔的表达式。此函数将传递的表达式转换为字符串,并将结果写入标准输出,如下所示:
#!/usr/bin/python3
print ("Python是世界上最牛逼的语言,", "难道不是吗?")
执行上面代码后,将在标准屏幕上产生以下结果 –
Python是世界上最牛逼的语言, 难道不是吗?
从键盘读取输入
Python 2有两个内置的函数用于从标准输入读取数据,默认情况下来自键盘。这两个函数分别是:input()和raw_input()。
在Python 3中,不建议使用raw_input()函数。 input()函数可以从键盘读取数并作为字符串类型,而不管它是否用引号括起来(“或”“)。
>>> x = input("input something:")
input something:yes,input some string
>>> x
'yes,input some string'
>>> x = input("input something:")
input something:1239900
>>> x
'1239900'
>>>
打开和关闭文件
在前面我们学习读取和写入标准的输入和输出。 现在,来看看如何使用实际的数据文件。Python提供了默认操作文件所必需的基本功能和方法。可以使用文件对象执行大部分文件操作。
打开文件
在读取或写入文件之前,必须使用Python的内置open()函数打开文件。此函数创建一个文件对象,该对象将用于调用与其相关联的其他支持方法。
语法
file object = open(file_name [, access_mode][, buffering])
这里是参数详细信息 –
- file_name –
file_name参数是一个字符串值,指定要访问的文件的名称。 - access_mode –
access_mode确定文件打开的模式,即读取,写入,追加等。可能的值的完整列表如下表所示。 这是一个可选参数,默认文件访问模式为(r– 也就是只读)。 - buffering – 如果
buffering值设置为0,则不会发生缓冲。 如果缓冲值buffering为1,则在访问文件时执行行缓冲。如果将缓冲值buffering指定为大于1的整数,则使用指定的缓冲区大小执行缓冲操作。如果为负,则缓冲区大小为系统默认值(默认行为)。
以下是打开文件使用的模式的列表 –
| 编号 | 模式 | 描述 |
|---|---|---|
| 1 | r |
打开的文件为只读模式。文件指针位于文件的开头,这是默认模式。 |
| 2 | rb |
打开仅用二进制格式读取的文件。文件指针位于文件的开头,这是默认模式。 |
| 3 | r+ |
打开读写文件。文件指针放在文件的开头。 |
| 4 | rb+ |
以二进制格式打开一个用于读写文件。文件指针放在文件的开头。 |
| 5 | w |
打开仅供写入的文件。 如果文件存在,则覆盖该文件。 如果文件不存在,则创建一个新文件进行写入。 |
| 6 | wb |
打开仅用二进制格式写入的文件。如果文件存在,则覆盖该文件。 如果文件不存在,则创建一个新文件进行写入。 |
| 7 | w+ |
打开写入和取读的文件。如果文件存在,则覆盖现有文件。 如果文件不存在,创建一个新文件进行阅读和写入。 |
| 8 | wb+ |
打开一个二进制格式的写入和读取文件。 如果文件存在,则覆盖现有文件。 如果文件不存在,创建一个新文件进行阅读和写入。 |
| 9 | a |
打开一个文件进行追加。 如果文件存在,则文件指针位于文件末尾。也就是说,文件处于追加模式。如果文件不存在,它将创建一个新文件进行写入。 |
| 10 | ab |
打开一个二进制格式的文件。如果文件存在,则文件指针位于文件末尾。 也就是说,文件处于追加模式。如果文件不存在,它将创建一个新文件进行写入。 |
| 11 | a+ |
打开一个文件,用于追加和阅读。 如果文件存在,则文件指针位于文件末尾。 文件以附加模式打开。 如果文件不存在,它将创建一个新文件进行阅读和写入。 |
| 12 | ab+ |
打开一个二进制格式的附加和读取文件。 如果文件存在,则文件指针位于文件末尾。文件以附加模式打开。如果文件不存在,它将创建一个新文件进行读取和写入。 |
文件对象属性
打开一个文件并且有一个文件对象后,可以获得与该文件相关的各种信息。
以下是与文件对象相关的所有属性的列表 –
| 编号 | 属性 | 描述 |
|---|---|---|
| 1 | file.closed |
如果文件关闭则返回true,否则返回false。 |
| 2 | file.mode |
返回打开文件的访问模式。 |
| 3 | file.name |
返回文件的名称。 |
注意 – Python 3.x中不支持
softspace属性
示例
#!/usr/bin/python3
# Open a file
fo = open("foo.txt", "wb")
print ("Name of the file: ", fo.name)
print ("Closed or not : ", fo.closed)
print ("Opening mode : ", fo.mode)
fo.close()
执行上面代码,这产生以下结果 –
Name of the file: foo.txt
Closed or not : False
Opening mode : wb
close()方法
文件对象的close()方法刷新任何未写入的信息并关闭文件对象,之后不能再进行写入操作。
当文件的引用对象重新分配给另一个文件时,Python也会自动关闭一个文件。但使用close()方法关闭文件是个好习惯。
语法
fileObject.close();
示例
#!/usr/bin/python3
# Open a file
fo = open("foo.txt", "wb")
print ("Name of the file: ", fo.name)
# Close opened file
fo.close()
执行上面代码,这产生以下结果 –
Name of the file: foo.txt
读取和写入文件
文件对象提供了一组访问方法,使代码编写更方便。下面将演示如何使用read()和write()方法来读取和写入文件。
write()方法
write()方法将任何字符串写入打开的文件。 重要的是要注意,Python字符串可以是二进制数据,而不仅仅是文本。
write()方法不会在字符串的末尾添加换行符(‘\n‘)
语法
fileObject.write(string);
这里,传递参数 – string 是要写入打开文件的内容。
示例
#!/usr/bin/python3
# Open a file
fo = open("foo.txt", "w")
fo.write( "Python is a great language.\nYeah its great!!\n")
# Close opend file
fo.close()
上述示例将创建一个foo.txt文件,并将给定的内容写入到该文件中,最后将关闭文件。 在执行上面语句后,如果打开文件(foo.txt),它将应该以下内容 –
Python is a great language.
Yeah its great!!
read()方法
read()方法用于从打开的文件读取一个字符串。 重要的是要注意Python字符串除文本数据外可以是二进制数据。。
语法
fileObject.read([count]);
这里,传递参数 – count是从打开的文件读取的字节数。 该方法从文件的开始位置开始读取,如果count不指定值或丢失,则尽可能地尝试读取文件,直到文件结束。
示例
下面来一个文件foo.txt,这是上面示例中创建的。
#!/usr/bin/python3
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10)
print ("Read String is : ", str)
# Close opened file
fo.close()
执行上面代码,这产生以下结果 –
Read String is : Python is
文件位置
tell()方法用于获取文件中的当前位置; 换句话说,下一次读取或写入将发生在从文件开始处之后的多个字节数的位置。
seek(offset [,from])方法更改当前文件位置。 offset参数表示要移动的字节数。 from参数指定要移动字节的引用位置。
如果from设置为0,则将文件的开头作为参考位置。 如果设置为1,则将当前位置用作参考位置。 如果设置为2,则文件的末尾将被作为参考位置。
示例
下面来一个文件foo.txt,这是上面示例中创建的。
#!/usr/bin/python3
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10)
print ("Read String is : ", str)
# Check current position
position = fo.tell()
print ("Current file position : ", position)
# Reposition pointer at the beginning once again
position = fo.seek(0, 0)
str = fo.read(10)
print ("Again read String is : ", str)
# Close opened file
fo.close()
执行上面代码,这产生以下结果 –
Read String is : Python is
Current file position : 10
Again read String is : Python is
重命名和删除文件
Python os模块提供用于执行文件处理操作(如重命名和删除文件)的方法。要使用此模块,需要先将它导入,然后可以调用任何相关的函数。
rename()方法
rename()方法有两个参数,即当前的文件名和新的文件名。
语法
os.rename(current_file_name, new_file_name)
示例
以下是一个将现有文件test1.txt重命名为test2.txt的示例 –
#!/usr/bin/python3
import os
# Rename a file from test1.txt to test2.txt
os.rename( "test1.txt", "test2.txt" )
remove()方法
使用remove()方法并通过提供要删除的文件的名称作为参数来删除文件。
语法
os.remove(file_name)
示例
以下是删除现有文件test2.txt的示例 –
#!/usr/bin/python3
import os
# Delete file test2.txt
os.remove("text2.txt")
Python中的目录
所有文件都包含在各种目录中,Python处理目录问题也很容易。 os模块有几种方法可以用来创建,删除和更改目录。
mkdir()方法
使用os模块的mkdir()方法在当前目录中创建目录。需要为此方法提供一个参数,指定要创建的目录的名称。
语法
os.mkdir("newdir")
示例
以下是在当前目录中创建一个目录:test 的示例 –
#!/usr/bin/python3
import os
# Create a directory "test"
os.mkdir("test")
使用chdir()方法来更改当前目录。 chdir()方法接受一个参数,它是要选择作为当前目录的目录的名称。
语法
os.chdir("newdir")
示例
以下是进入“/home/newdir”目录的示例 –
#!/usr/bin/python3
import os
# Changing a directory to "/home/newdir"
os.chdir("/home/newdir")
getcwd()方法
getcwd()方法用于显示当前工作目录。
os.getcwd()
示例
以下是给出当前目录的一个例子 –
#!/usr/bin/python3
import os
# This would give location of the current directory
os.getcwd()
rmdir()方法
rmdir()方法删除该方法中作为参数传递的目录。删除目录之前,应删除其中的所有内容。
os.rmdir('dirname')
示例
以下是删除“/tmp/test”目录的示例。需要给出目录的完全限定名称,否则将在当前目录中搜索该目录。
#!/usr/bin/python3
import os
# This would remove "/tmp/test" directory.
os.rmdir( "/tmp/test" )
文件和目录相关方法
有三个重要的来源,它们提供了广泛的实用方法来处理和操作Windows和Unix操作系统上的文件和目录。它们如下 –
关注右侧公众号,随时随地查看教程
Python教程目录
转载自:https://www.yiibai.com/python/python_quick_guide.html

