python 报错 ModuleNotFoundError: No module named ‘MySQLdb’
python 报错 ModuleNotFoundError: No module named ‘MySQLdb’

gis,openlayers,leaflet,gis应用,geoai,geoserver,cesium,python,arcpy,arcmap,webgis,gis可视化

python 报错 ModuleNotFoundError: No module named ‘MySQLdb’
在本章中,我们将了解如何安装和设置Scrapy。Scrapy必须与Python一起安装。 Scrapy可以通过使用 pip 进行安装。运行以...

Spider是负责定义如何遵循通过网站的链接并提取网页中的信息的类。 Scrapy默认的 Spider 如下: scrapy.Spider ...
Scrapy shell 可用于抓取数据并提示错误代码,而无需使用蜘蛛。 Scrapy shell的主要目的是测试所提取的代码,XPath或...
当刮取网页中的数据,需要通过使用XPath或CSS表达式来实现选择器机制提取HTML源代码的某些部分。选择器是在Python语言的XML和L...
项目是用于收集从网站刮取下数据的容器。 在启动蜘蛛时必须要定义项目。 要定义项目,在目录 first_scrapy自定义目录下找到编辑ite...
Scrapy进程可通过使用蜘蛛提取来自网页中的数据。Scrapy使用Item类生成输出对象用于收刮数据。 声明项目 如下图所示,您可以通过使...
从网页中刮取数据,首先需要创建Scrapy项目,用于编写存储代码。要创建一个新的目录下,运行下面的命令: scrapy startproje...
要执行蜘蛛抓取数据,在 first_scrapy 目录中运行以下命令: scrapy crawl first 在这里,first 是创建蜘蛛...
Spider定义从提取数据的初始 URL,如何遵循分页链接以及如何提取和分析在 items.py 定义字段的类。Scrapy 提供了不同类型...
项目(Item)对象是Python中的常规的字典类型。我们可以用下面的语法来访问类的属性: >>> item = Yiib...
从网页中提取数据,Scrapy 使用基于 XPath 和 CSS 表达式的技术叫做选择器。以下是 XPath 表达式的一些例子: /html...
Scrapy快速入门 最好的学习方法是参考例子,Scrapy 也不例外。出于这个原因,有一个 Scrapy 项目名为 quotesbot 例...
Scrapy是什么? Scrapy是使用Python编写的一个快速开源Web抓取框架,使用基于XPath选择器来提取网页中的数据。 历史 S...
Scrapy命令行工具用于控制Scrapy,它通常被称为“Scrapy工具”。它包括用于不同对象的参数和选项组的命令。 配置设置 scrap...
日志记录是指使用内置的日志系统和定义的函数或类来实现应用程序和库的事件跟踪。 记录日志是一个即用型的程序库,它可以在Scrapy设置日志记录...
项目加载器提供了一个方便的方式来填补从网站上刮取的项目。 声明项目加载器 项目加载器的声明类:Items。例如: from scrapy.l...
(1)Scrapy教程 (2)Scrapy安装 (3)Scrapy命令行工具 (4)Scrapy蜘蛛(Spider) (5)Scrapy选择...
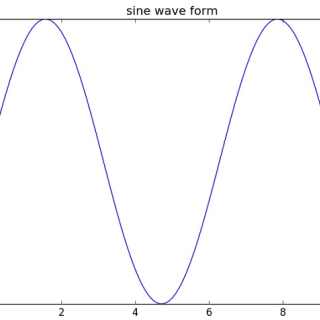
Matplotlib是一个Python库,用于通过使用python脚本创建二维图形和图表。 它有一个名为pyplot的模块,通过提供控制线条...
NumPy是代表“Numerical Python”的Python包。 它是一个由多维数组对象和一组处理数组的例程组成的库。 NumPy操作...
要在本教程中成功创建并运行示例代码,我们需要一个正确环境设置,它将包含通用Python以及数据科学所需的特殊包。 我们先看看如何安装pyth...
从CSV读取数据(逗号分隔值)是数据科学的基本需求。 通常,我们从各种来源获取数据,这些数据可以导出为CSV格式,以便其他系统可以使用这些数...
数据丢失在现实生活中是一个问题。 机器学习和数据挖掘等领域由于数据缺失导致数据质量差,因此在模型预测的准确性方面面临严峻的问题。 在这些领域...
JSON文件以可读的格式将数据存储为文本。 JSON代表JavaScript Object Notation。 使用read_json函数,...
Python的SciPy库构建NumPy数组,并提供许多用户友好和高效的数字实践,例如:数值集成和优化例程。 它们一起运行在所有流行的操作系...
Microsoft Excel是一个使用非常广泛的电子表格程序。 它的用户友好性和吸引人的功能使其成为数据科学中常用的工具。 Panadas...
我们可以连接到关系数据库以使用Pandas库分析数据,以及另一个用于实现数据库连接的额外库。 这个软件包被命名为sqlalchemy,它提供...
通常在数据科学中,我们需要基于时间值的分析。 Python可以优雅地处理各种格式的日期和时间。 日期时间库提供了必要的方法和函数来处理下列情...
Python有几种方法可用于对数据执行聚合。 它使用Pandas和numpy库完成。 数据必须可用或转换为数据框才能应用聚合功能。 在Dat...

Python具有用于数据可视化的一些很不错的类库。 Pandas,numpy和matplotlib的组合可以帮助创建几乎所有类型的可视化图表...
有一个类库叫作beautifulsoup。 使用这个库,可以搜索html标签的值,并获取页面标题和页面标题列表等特定数据。 安装Beauti...
随着越来越多的数据以非结构化或半结构化的方式来提供,需要通过NoSql数据库来管理它们。 Python也可以以与关系数据库交互的相似方式与N...
已经以行和列格式存在的数据或者可以很容易地转换为行和列的数据,以便之后它可以很好地适合数据库,这被称为结构化数据。 例如CSV,TXT,XL...
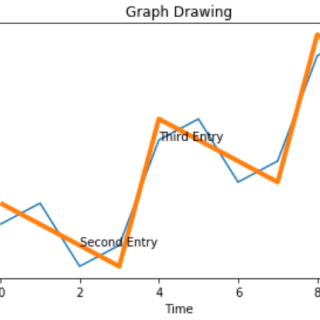
在python中创建的图表可以通过使用用于制图的库中的某些适当方法进一步设置样式。 在本课中,我们将看到注释,图例和图表背景的实现。 我们将...
单词标记是将大量文本样本分解为单词的过程。 这是自然语言处理任务中的一项要求,每个单词需要被捕获并进行进一步的分析,如对特定情感进行分类和计...
在自然语言处理领域,我们遇到了两个或两个以上单词具有共同根源的情况。 例如,agreed, agreeing 和 agreeable这三个词...
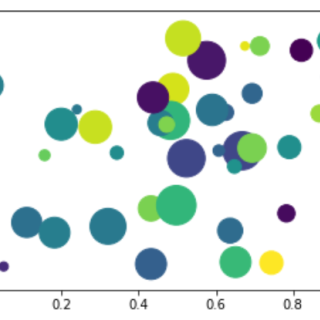
气泡图将数据显示为一组圆圈。 创建气泡图所需的数据需要具有xy坐标,气泡大小和气泡颜色。 颜色可以由库自己提供。 绘制气泡图 气泡图可以使用...
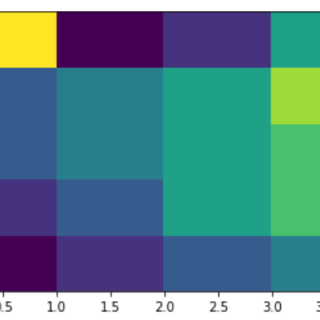
热图包含代表要绘制的每个值的相同颜色的各种阴影的值。 通常图表的较暗阴影表示比较浅的阴影更高的值。 对于非常不同的值,也可以使用完全不同的颜...
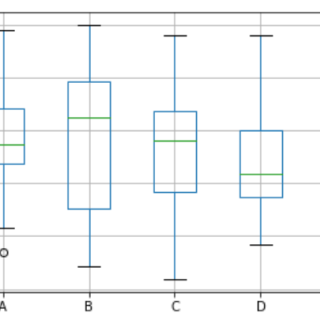
箱线图是数据集中数据分布情况的一种度量。 它将数据集划分为三个四分位数。 该图表示数据集中的最小值,最大值,中位数,第一四分位数和第三四分位...
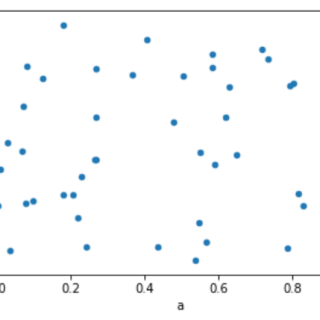
散点图显示在笛卡尔平面的多个点。 每个点代表两个变量的值。 一个变量在水平轴上选择,另一个在垂直轴上选择。 绘制散点图 可以使用DataFr...
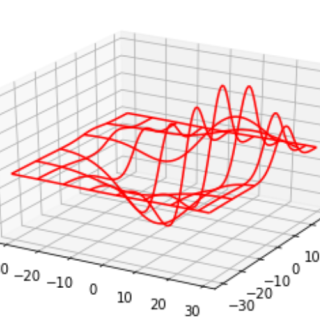
Python也能够创建三维图表。 它涉及将一个子图添加到现有的二维图并将投影参数指定为3d。 绘制3D图表 3dPlot由mpl_toolk...
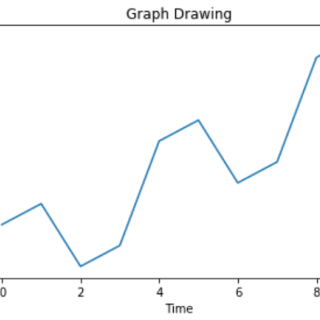
数学中心趋势意味着测量数据集中值或位置的分布。 它给出了数据集中数据的平均值的一个概念,也表明数据集中数值的扩展程度。 这反过来有助于评估新...

现在已经创建了许多开源python库来表示地理地图。 它们高度可定制,并提供各种地图,描绘不同形状和颜色的区域。 一个包是Cartopy。 ...
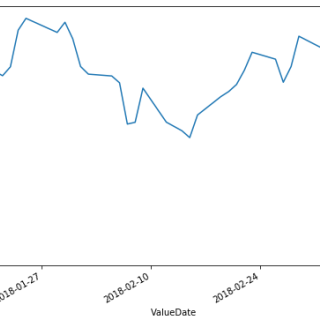
时间序列是一系列数据点,其中每个数据点与时间戳相关联。 一个简单的例子就是某个特定日子不同时间点股市中股票的价格。 另一个例子是一年中不同月...

CSGraph代表压缩稀疏图,它着重于基于稀疏矩阵表示的快速图算法。 图的表示 首先,让我们了解一个稀疏图是什么以及它在图表示中的作用。 什...
在统计中,方差是衡量数据集中的值与平均值相差多少的指标。 换句话说,它表示值的分散程度。 它通过使用标准偏差来衡量。 另一种常用的方法是偏斜...

正态分布是通过排列数据中每个值的概率分布来呈现数据的形式。大多数值保持在平均值附近,使得排列对称。 可使用numpy库中各种函数来数学计算正...
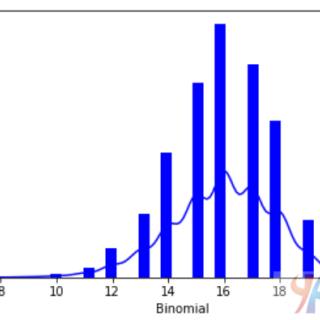
二项分布模型处理的是在一系列实验中只发现两种可能结果的事件成功概率。 例如,投掷硬币总是会产生正面或背面。 在二项分布期间估计重复抛掷硬币1...
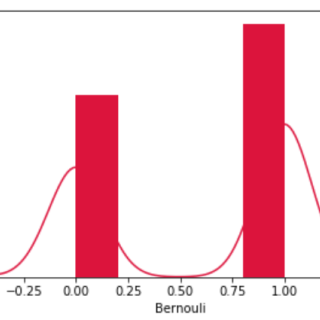
伯努利分布是二项分布的特例,其中进行了单个实验,因此观察次数为1。因此,伯努利分布因此描述了具有两个结果的事件。 在numpy库中使用各种函...
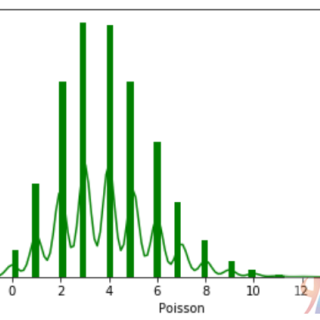
泊松分布是显示事件在预定时间段内发生的可能次数的分布。 它用于在给定的时间间隔内以恒定速率发生的独立事件。 泊松分布是一个离散函数,意味着事...
相关性是指涉及两个数据集之间相关性的一些统计关系。 依赖现象的简单例子包括父母与其后代的外表之间的相关性,以及产品价格与其供应量之间的相关性...
p值是关于假设的强度。 我们基于一些统计模型建立假设,并使用p值比较模型的有效性。 获得p值的一种方法是使用T检验。 这是对零假设的双侧检验...
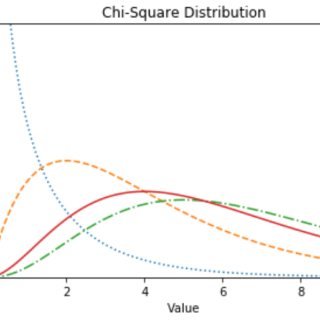
卡方检验是确定两个分类变量是否具有显着相关性的统计方法。 这两个变量应该来自相同的人口,他们应该是类似的 – 是/否,男/女,红...
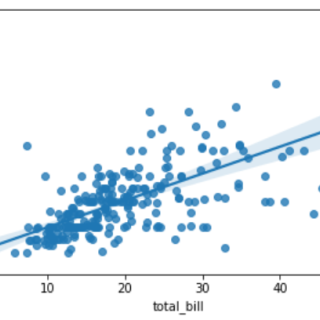
在线性回归中,这两个变量通过方程相关,其中这两个变量的指数(幂)为1。在数学上,线性关系表示绘制为图形时的直线。 任何变量的指数不等于1的非...
Python主要通过Pandas和Numpy这两个库来处理各种格式的数据。 我们已经在前面的章节中看到了这两个库的重要特征。 在本章中,我们...
数据处理涉及以各种格式处理数据,例如合并,分组,连接等,以便分析或准备将其与另一组数据一起使用。 Python具有内置函数功能,可将这些争议...
数据科学是通过组织,处理和分析数据从大量不同的数据中获取知识和洞察力的过程。 它涉及许多不同的学科,如数学和统计建模,从数据源提取数据和应用...
Pandas是一个开源的Python库,用于使用其强大的数据结构进行高性能数据处理和数据分析。 Python和Pandas在各种学术和商业领...

Python数据科学 (2)Python数据科学简介 (3)Python数据科学开发环境 (4)Python Pandas库 (5)Pyth...
决策是指在执行程序期间根据发生的情况并根据条件采取的具体操作(行动)。决策结构评估求值多个表达式,产生TRUE或FALSE作为结果。如果结果...

