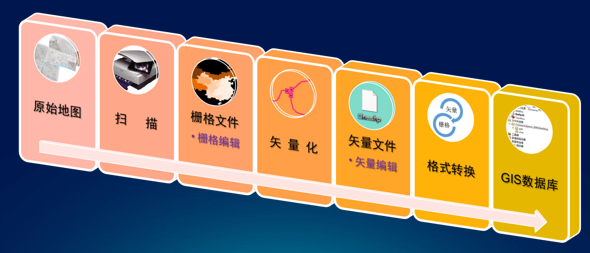
结合matlab与arcpy的土壤样点聚类与成图
matlab 进行均值聚类与分类
for i=1:1
clc
format long g
%均值聚类
opts = statset('Display','final');
[Idx,Ctrs,SumD,D] = kmeans(youjizhi,20,'Replicates',2000,'Options',opts, 'Start','uniform');
points=[Idx youjizhi];
%检验标准偏差分布
'全部样本的标准偏差'
wd=youjizhi';
std(wd,0,2)
'cluster样本差'
cluster1=[];
cluster2=[];
cluster3=[];
cluster4=[];
cluster5=[];
cluster6=[];
cluster7=[];
cluster8=[];
cluster9=[];
cluster10=[];
cluster11=[];
cluster12=[];
cluster13=[];
cluster14=[];
cluster15=[];
cluster16=[];
cluster17=[];
cluster18=[];
cluster19=[];
cluster20=[];
[row col]=size(points);
for i=1:1:row
id=points(i,1);
value=points(i,:);
if id==1
cluster1=[cluster1;value];
end
if id==2
cluster2=[cluster2;value];
end
if id==3
cluster3=[cluster3;value];
end
if id==4
cluster4=[cluster4;value];
end
if id==5
cluster5=[cluster5;value];
end
if id==6
cluster6=[cluster6;value];
end
if id==7
cluster7=[cluster7;value];
end
if id==8
cluster8=[cluster8;value];
end
if id==9
cluster9=[cluster9;value];
end
if id==10
cluster10=[cluster10;value];
end
if id==11
cluster11=[cluster11;value];
end
if id==12
cluster12=[cluster12;value];
end
if id==13
cluster13=[cluster13;value];
end
if id==14
cluster14=[cluster14;value];
end
if id==15
cluster15=[cluster15;value];
end
if id==16
cluster16=[cluster16;value];
end
if id==17
cluster17=[cluster17;value];
end
if id==18
cluster18=[cluster18;value];
end
if id==19
cluster19=[cluster19;value];
end
if id==20
cluster20=[cluster20;value];
end
end
wd=[std(cluster1(:,2)) size(cluster1)
std(cluster2(:,2)) size(cluster2)
std(cluster3(:,2)) size(cluster3)
std(cluster4(:,2)) size(cluster4)
std(cluster5(:,2)) size(cluster5)
std(cluster6(:,2)) size(cluster6)
std(cluster7(:,2)) size(cluster7)
std(cluster8(:,2)) size(cluster8)
std(cluster9(:,2)) size(cluster9)
std(cluster10(:,2)) size(cluster10)
std(cluster11(:,2)) size(cluster11)
std(cluster12(:,2)) size(cluster12)
std(cluster13(:,2)) size(cluster13)
std(cluster14(:,2)) size(cluster14)
std(cluster15(:,2)) size(cluster15)
std(cluster16(:,2)) size(cluster16)
std(cluster17(:,2)) size(cluster17)
std(cluster18(:,2)) size(cluster18)
std(cluster19(:,2)) size(cluster19)
std(cluster20(:,2)) size(cluster20)]
nh_sh=wd(:,1).*wd(:,2)
sum_nh_sh=sum(nh_sh)
everyceng=3444*nh_sh./sum_nh_sh
result=[everyceng wd(:,2)]
jian=result(:,2)-result(:,1)
marker=1;
for m=1:20
if jian(m)<0
marker=0;
break
end
end
%if marker==1
%将矩阵写入txt
save G:\cluster.txt points -ascii
%break
%
end
调用arcpy快速进行图层点的筛选与融合
import arcpy
arcpy.CheckOutExtension("GeoStats")
totalnumber=3827
#最适分配法
nh_sh= [0.138668464822287,
0.351529315237771,
1.10131171831967,
0.883106930711289,
0.648468780840982,
0.438017779616242,
0.45758716958516,
0.659750131228045,
0.815258226842102,
0.671962109599111,
0.388616937396948,
0.761279692306943,
0.527106150190267,
0.701677975374704,
1.02415120842429,
0.60959947256602,
1.21354527363413,
0.291550613209568,
0.555969630929788,
0.451522215923154]
sum_nh_sh= 12.6906797967585
yuashiceng=[ 19,
173,
234,
200,
241,
131,
151,
138,
244,
179,
176,
283,
169,
269,
242,
215,
299,
66,
235,
163]
#subset feature
inPointFeatures = workspace+"ca_ozone_pts.shp"
percentage=1
for i in range(1,21,1):
percentage=percentage*0.9
#第n次抽样时的比重
#第n次抽样时的总样本数
currentnumber=(int)(totalnumber*percentage)
#各层数量
length=len(nh_sh)
ceng=[]
cengmarker=[]
for k in range(0,length,1):
cengi=currentnumber*nh_sh[k]/sum_nh_sh
ceng.append(cengi)
cengmarker.append(1)
#调整各层数量
marker=1
while marker:
marker=0
sum=0
counter=0
stoper=0
for n in range(0,length,1):
if yuashiceng[n]-ceng[n]<0 and cengmarker[n]==1:
cengmarker[n]=0
sum+=(yuashiceng[n]-ceng[n])
ceng[n]=yuashiceng[n]
for q in range(0,length,1):
if cengmarker[q]==1:
counter+=1
if counter>0:
piece=-sum/counter
for m in range(0,length,1):
if cengmarker[m]==1:
ceng[m]+= piece
for v in range(0,length,1):
if yuashiceng[v]-ceng[v]<0 and cengmarker[v]==1:
marker=1
print 'jj\n'
for f in range(0,length,1):
ceng[f]=int(round(ceng[f]))
#开始调用工具箱
# Set local variables
time=str(i)
allceng=[]
for j in range(1,21,1):
inPointFeatures = "G:\\层"+str(j)+".shp"
outtrainPoints = "G:\\层"+str(i*10)+str(j)+".shp"
allceng.append(outtrainPoints)
outtestPoints = ""
trainData = str(ceng[j-1])
subsizeUnits = "ABSOLUTE_VALUE"
# Execute SubsetFeatures
arcpy.SubsetFeatures_ga(inPointFeatures, outtrainPoints, outtestPoints, trainData,
subsizeUnits)
#每一次subset feature完毕 执行 merge
place="G:\\第"+str(i)+"次.shp"
arcpy.Merge_management(allceng, place)
print i
结果:每一个图层都是按方差最小的分层抽样原则得到的点
转载自:https://blog.csdn.net/sisterhuang/article/details/18415401