5.轨迹抽象,关键点序列生成
研究了两篇模型,接下来继续进行轨迹抽象,试一试模型效果。再然后统计预测效果或重新研究预测模型
现在发现了几个问题:
1.转移概率是从状态序列统计出来的,那么回头验证的时候准确率肯定和转移概率一样。就是转移概率低的点肯定预测不到。需要结合其他信息预测
2.用三维矩阵统计出的马尔可夫链统计出的数量比预计的少,很多都是1,没有代表性。二维矩阵又有丢失信息,二者结合应该是个思路,那干脆更多结合好了。
找到一篇论文说低阶马尔可夫链准确率低,高阶马尔可夫链稀疏率高。
现在看起来关键点的选取没什么可研究的,能代表轨迹就行。更有研究价值的在于数据准备和预测模型,看哪边更容易突破吧。我去查预测模型相关的文献去了。
另,附上关键点序列生成的代码和结果。
代码是在之前的基础上添加的。最后会输出一个OID的序列,做成表(这步没有API,所以后面就手动了),连接上极值面要素,显示XY数据,导出成图层,XY转线,
# -*- coding: UTF-8 -*-
# Name: CreateFishnet.py
# Description: Creates rectangular cells
# import system module
import arcpy
import time
from arcpy import env
def GetDistance(lng1, lat1, lng2, lat2):
def rad(num):
return num/180*math.pi
EARTH_RADIUS = 6378137
radLat1 = rad(lat1);
radLat2 = rad(lat2);
a = radLat1 - radLat2;
b = rad(lng1) - rad(lng2);
s = 2 * math.asin(math.sqrt(math.pow(math.sin(a/2),2) +
math.cos(radLat1)*math.cos(radLat2)*math.pow(math.sin(b/2),2)));
s = s * EARTH_RADIUS;
#s = math.round(s * 10000) / 10000;
return s;
def GetMinMax(input):
fc=arcpy.SearchCursor(input)
minx=999;
maxx=0;
miny=999;
maxy=0;
for row in fc:
minx=min(minx,row.getValue("LONGITUDE_"));
maxx=max(maxx,row.getValue("LONGITUDE_"));
miny=min(miny,row.getValue("LATITUDE_D"));
maxy=max(maxy,row.getValue("LATITUDE_D"));
minx=minx-minx%0.01;
maxx=maxx-maxx%0.01+0.02;
miny=miny-miny%0.01;
maxy=maxy-maxy%0.01+0.02;
list=[0,0,0,0];
list[0]=minx;
list[1]=maxx;
list[2]=miny;
list[3]=maxy;
return list;
def nearTop(fea,search_radius):
def get(row0):
feature1.reset();
for row1 in feature1:
if(row1[0]==row0):
return row1[1];
def update(row0,str):
updateFea.reset();
for row1 in updateFea:
if(row1[0]==row0):
if(row1[1]==0):
return;
else:
row1[1]=str;
updateFea.updateRow(row1)
#arcpy.AddMessage("update:");
return;
def test():
n=0;
for row in neartable:
arcpy.AddMessage("process:"+str(row[0]));
n+=1;
if(get(row[0])>=get(row[1])):
update(row[0],1);
update(row[1],0);
if(n==-1):
return;
temp="temp"+str(int(time.time()))
arcpy.AddField_management(fea, "test", "SHORT")
arcpy.GenerateNearTable_analysis(fea, fea, temp, search_radius, 'LOCATION', 'NO_ANGLE', 'ALL','#')
neartable=arcpy.da.SearchCursor(temp,["IN_FID","NEAR_FID"])
feature1=arcpy.da.SearchCursor(fea,["OID@","Join_Count"])
updateFea=arcpy.da.UpdateCursor(fea,["OID@","test"])
test();
#arcpy.DeleteFeatures_management(temp)
def clear(fea):
updateFea=arcpy.da.UpdateCursor(fea,["OID@","test"])
for row in updateFea:
if row[1]==0:
updateFea.deleteRow()
updateFea.reset()
arcpy.CopyFeatures_management(fea,fea+"_copy")
return fea+"_copy"
def getToken(fea):
searchFea=arcpy.da.SearchCursor(fea,["NEAR_FID"])
token=""
last=0;
for row in searchFea:
if (row[0]!=last):
last=row[0]
token+=str(last)+","
return token
# set workspace environment
env.workspace = "C:\Users\panda\Desktop\轨迹预测\轨迹.gdb"
# Set coordinate system of the output fishnet
env.outputCoordinateSystem = arcpy.SpatialReference("WGS 1984")
input = arcpy.GetParameterAsText(0)
output = arcpy.GetParameterAsText(1)
isLabel=arcpy.GetParameterAsText(2)
search_radius_text=arcpy.GetParameterAsText(3)
label='NO_LABELS'
if isLabel:
label='LABELS'
#if(!(search_radius_text==''&&search_radius_text=='#'))
search_radius=float(search_radius_text)
list=GetMinMax(input);
temp="temp"+str(int(time.time()))
arcpy.CreateFishnet_management(temp, str(list[0])+' '+str(list[2]), str(list[0])+' '+str(list[2]+1), '0.01', '0.01', '0', '0', str(list[1])+' '+str(list[3]), label, '#', 'POLYGON')
#arcpy.DeleteFeatures_management(temp)
arcpy.SpatialJoin_analysis(temp, input, output, "JOIN_ONE_TO_ONE", "KEEP_COMMON", "#", "INTERSECT")
nearTop(output,search_radius)
temp="temp"+str(int(time.time()))
arcpy.GenerateNearTable_analysis(input, clear(output), temp, search_radius, 'LOCATION', 'NO_ANGLE', 'ALL','#')
arcpy.Sort_management(temp,temp+"_Sort",[["IN_FID","ASCENDING"]])
token=getToken(temp+"_Sort")
arcpy.AddMessage("token:"+token);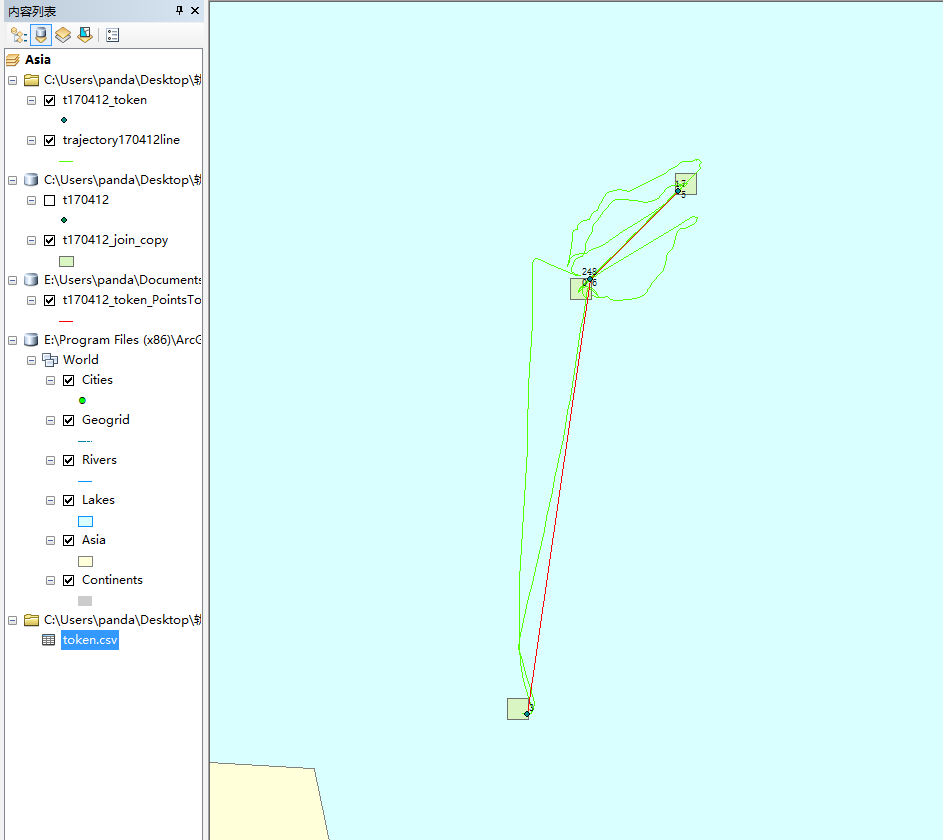
这就是结果,标记的是序号,按数字顺序就是轨迹顺序。如果关键点足够多应该抽象出来的轨迹是可以的,刚刚发现一样的代码换一台电脑跑出来的关键点数量居然不一样(所以这张图的关键点比之前实验的少了)。以后解决。现在先集中精力做理论研究。
转载自:https://blog.csdn.net/u010752777/article/details/78312963