分幅矢量数据的下载及基于arcpy的分幅数据批量处理
目录
获取原始矢量数据是进行地理分析的重要前提,因此,原始数据的完整性和准确性是影像地理分析结果的决定性因素之一。
笔者在进行了一周的实践周实训之后,掌握了一种较为可行的原始矢量数据下载和一些基于arcpy模块包的python脚本批量处理原始数据的编程技术。
为此,笔者将所学到的技术都会在下文中进行分享~~
1.原始矢量数据的下载
全国地理信息资源目录服务系统
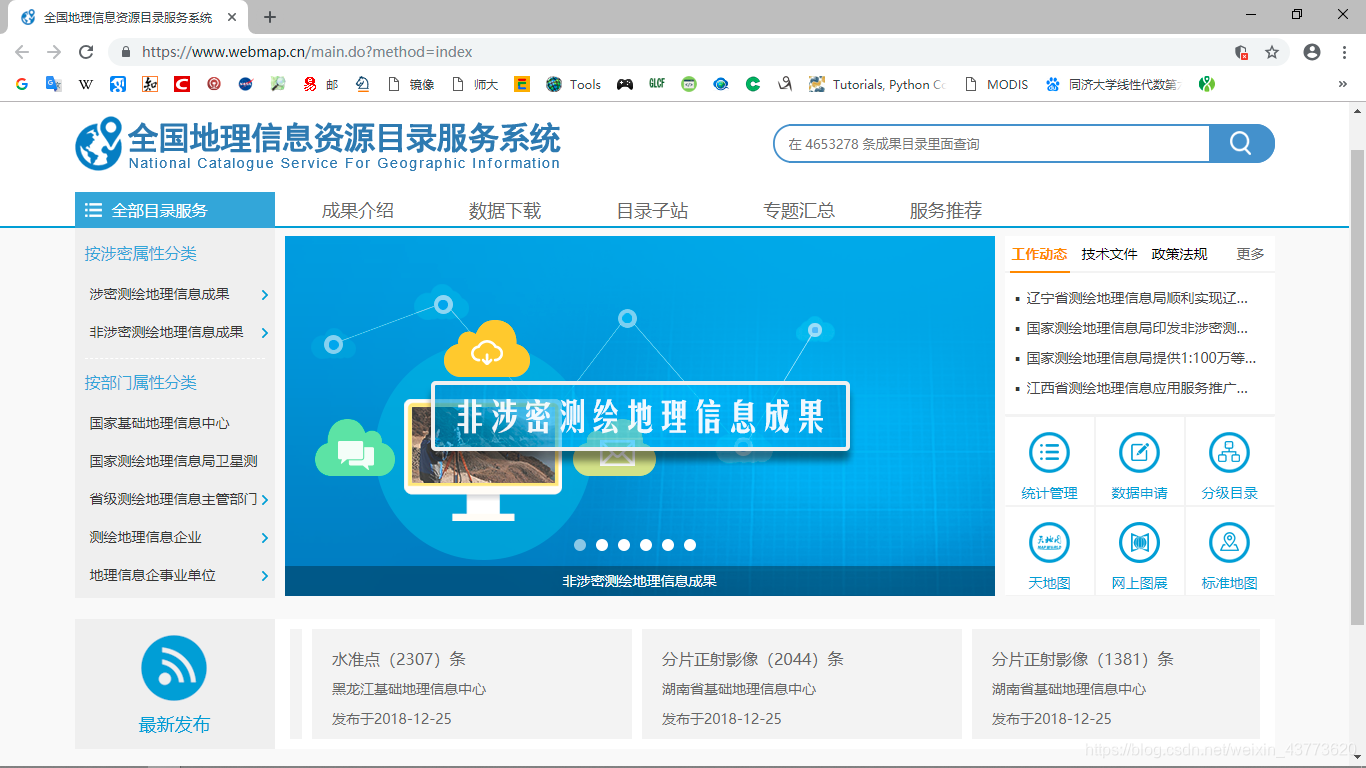
该网站可以涉及许多地理数据,获得许可后均可进行下载,其中,最主要的模块有30m全球地表覆盖数据、1:100万全球基础地理数据库、1:25万全球基础地理数据库。笔者将以1:100万全球基础地理数据库作为例子进行实验。
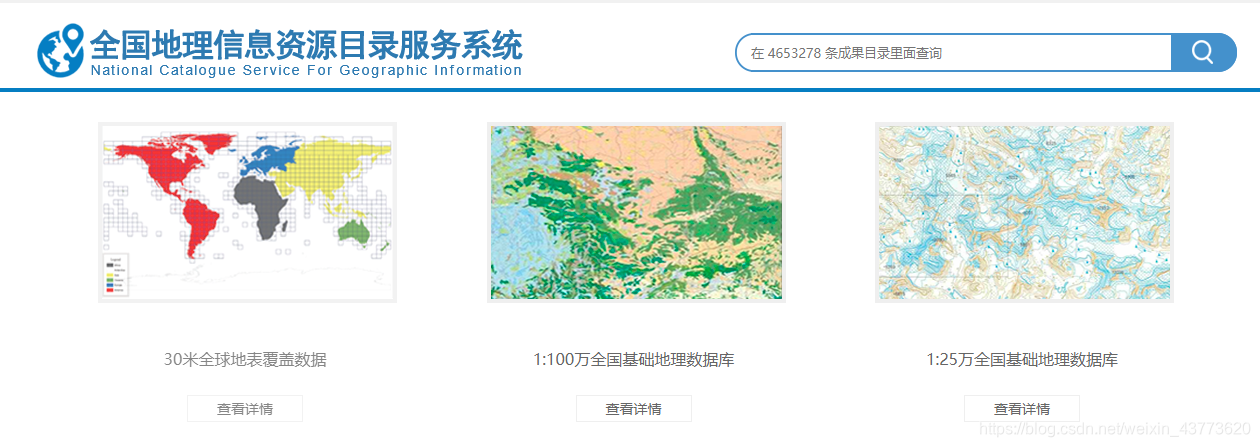
该数据以分幅作为组织形式,因此可以根据实际的研究范围进行分幅区域的选择下载,下载的文件格式是文件型数据库
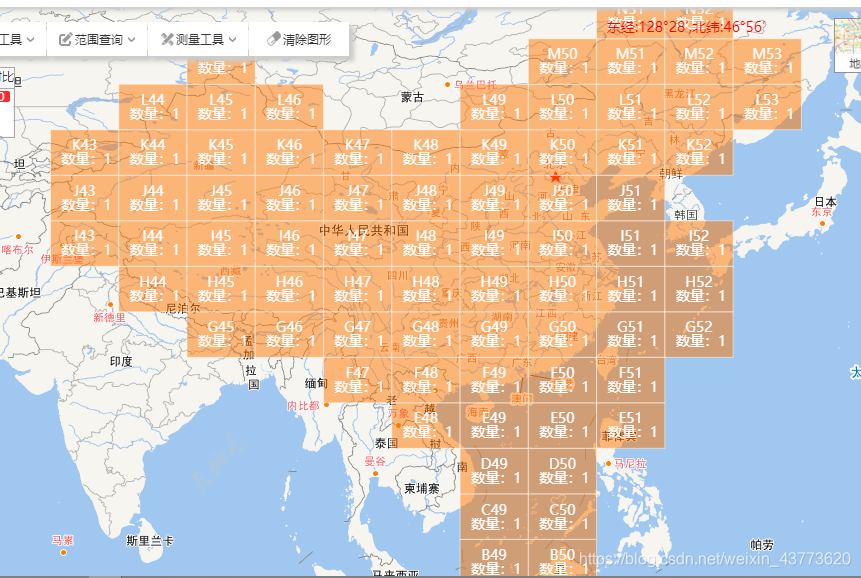
本文将以I50、I51、H50、H51分幅数据作为例子进行实验,并用arcpy对分幅数据进行批量的合并、融合、关联、裁切等的处理,最终获得其中长三角地区矢量数据。
原始数据如下图
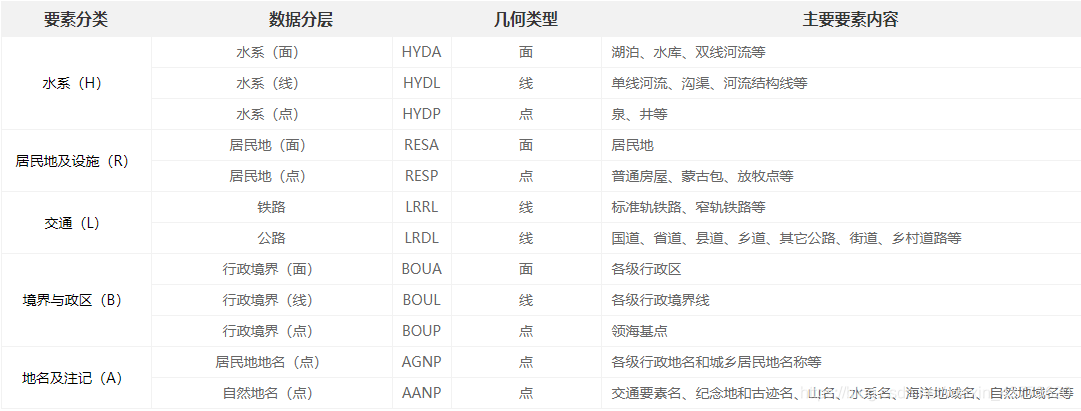
数据说明
2.基于arcpy的分幅数据批量处理过程
2.1arcpy模块包及相关变量的准备
# -*- coding: utf-8 -*-
import arcpy #导入arcpy包
arcpy.gp.overwriteOutput=1 #允许重名文件覆盖
#设置工作空间
arcpy.env.workspace = "C:\\Users\\GISER\Desktop\\实践周_分幅拼接\\华东长三角"
#矢量数据的要素类
datas = ["AANP", "AGNP", "BOUA", "BOUL", "BOUP", "HYDA", "HYDL", "HYDP", "LRDL", "LRRL", "RESA", "RESP"]
datasets = [] #数据集名称集合
b = ["H", "I"] #分幅编号字母位,当分幅较多时,可运用循环遍历部分ascii码定义
filegdb = "result_yan.gdb" #工作数据库名称
2.2创建数据库及相关要素集
#创建文件型数据库
arcpy.CreateFileGDB_management(arcpy.env.workspace, filegdb) #创建文件型数据库
#数据库要素集坐标系获取
pjsion = arcpy.Describe("H50.gdb\\AANP")
coord_sys = pjsion.spatialReference
#创建数据库要素集
for i in b:
a = 50 #分幅编号最小数值位
while a <= 51: #分幅编码最大数值位
output = i + str(a)
arcpy.CreateFeatureDataset_management(filegdb, output, coord_sys)
datasets.append(i + str(a))
a = a + 1
2.3 把分幅数据分幅导入相应分幅编号的数据库要素集中
for i in datasets:
n = 0
datas_buffer = []
output = filegdb + "\\" + i
while n < 12:
datas_buffer.append(i + ".gdb\\" + datas[n])
n = n + 1
arcpy.FeatureClassToGeodatabase_conversion(datas_buffer, output)
2.4 分幅数据合并
merge_Dataset = "merge"
arcpy.CreateFeatureDataset_management(filegdb, merge_Dataset, coord_sys)
merge_datas = []
for i in datas:
n = 0
datasets_buffer = []
output = filegdb + "\\" + merge_Dataset + "\\merge_" + i
while n < 4:
suffix = ""
if n == 0:
suffix = ""
else:
suffix = "_" + str(n)
datasets_buffer.append(filegdb + "\\" + datasets[n] + "\\" + i + suffix)
n = n + 1
arcpy.Merge_management(datasets_buffer, output)
merge_datas.append(output)
2.5 对合并后的数据进行融合以及字段关联
dissolve_datas = []
n = 0
for i in datas:
input_mg = merge_datas[n]
output = filegdb + "\\" + dissolve_Dataset + "\\" + "dissolve_" + i
if i == "BOUA":
arcpy.Dissolve_management(input_mg, output, "PAC", "","SINGLE_PART")
arcpy.JoinField_management(output, "PAC", input_mg, "PAC", "NAME")
dissolve_datas.append(output)
elif i == "BOUL":
arcpy.Dissolve_management(input_mg, output, "GB", "","SINGLE_PART")
dissolve_datas.append(output)
elif i == "HYDA":
arcpy.Dissolve_management(input_mg, output, "NAME;GB", "","SINGLE_PART")
arcpy.JoinField_management(output, "NAME", input_mg, "NAME", "HYDC;PERIOD;VOL")
dissolve_datas.append(output)
elif i == "HYDL":
arcpy.Dissolve_management(input_mg, output, "NAME;GB", "","SINGLE_PART")
arcpy.JoinField_management(output, "NAME", input_mg, "NAME", "HYDC;PERIOD")
dissolve_datas.append(output)
elif i == "LRDL":
arcpy.Dissolve_management(input_mg, output, "NAME;GB", "","SINGLE_PART")
arcpy.JoinField_management(output, "NAME", input_mg, "NAME", "RN;RTEG;TYPE")
arcpy.FeatureToLine_management(output,output + "_")
dissolve_datas.append(output + "_")
elif i == "LRRL":
arcpy.Dissolve_management(input_mg, output, "NAME;GB", "","SINGLE_PART")
arcpy.JoinField_management(output, "NAME", input_mg, "NAME", "RN;TYPE")
arcpy.FeatureToLine_management(output,output + "_")
dissolve_datas.append(output + "_")
elif i == "RESA":
arcpy.Dissolve_management(input_mg, output, "GB", "","SINGLE_PART")
dissolve_datas.append(output)
else:
arcpy.FeatureClassToGeodatabase_conversion(input_mg, filegdb + "//dissolve")
dissolve_datas.append(input_mg)
n = n + 1
2.6 GB或CLASS字段含义导入
arcpy.TableToGeodatabase_conversion("C:\\Users\\GISER\\Desktop\\实践周_分幅拼接\\华东长三角\\CLASS_A.csv", filegdb) #CLASS
arcpy.TableToGeodatabase_conversion("C:\\Users\\GISER\\Desktop\\实践周_分幅拼接\\华东长三角\\GB.csv", filegdb) #GB
n = 0
for i in datas:
print i
if i == "BOUA":
#对BOUA行政面数据添加分级字段属性
field_name = ["PROVINCE", "CITY"]
for j in field_name:
arcpy.AddField_management(dissolve_datas[n], j, "TEXT")
if j == "CITY":
arcpy.CalculateField_management(dissolve_datas[n], j, "Right(Left([PAC], 4), 2)", "VB")
else:
arcpy.CalculateField_management(dissolve_datas[n], j, "Left([PAC], 2)", "VB")
elif i == "AGNP" or i == "AANP":
arcpy.JoinField_management(dissolve_datas[n], "CLASS", filegdb + "\\CLASS_A", "CLASS", "MEAN")
else:
arcpy.JoinField_management(dissolve_datas[n], "GB", filegdb + "\\GB", "GB", "MEAN")
n = n + 1
2.7 批量裁切获取长三角区域范围数据
geo_Range = filegdb + "//" + "geo_Range"
arcpy.Select_analysis(dissolve_datas[2], geo_Range, "PROVINCE = '31' OR PROVINCE = '32' OR PROVINCE = '33' OR PROVINCE = '34'")
clip_Dataset = "clip"
arcpy.CreateFeatureDataset_management(filegdb, clip_Dataset, coord_sys)
clip_datas = []
n = 0
for i in datas:
output = filegdb + "//" + clip_Dataset + "//clip_" + i
arcpy.Clip_analysis(dissolve_datas[n], geo_Range, output)
clip_datas.append(output)
n = n + 1
有待完善…
转载自:https://blog.csdn.net/weixin_43773620/article/details/85639078