ArcSDE数据迁移方法实践说明
每次用户问道ArcSDE数据怎么迁移,我们都会给用户推荐使用ArcGIS的方法来迁移,所谓ArcGIS的方法就是

将SDE数据导出到FGDB,然后FGDB可以导入任意操作系统、任意版本、任意数据库的ARcSDE里面
所谓导出我们推荐
1:如果使用ArcCatalog,使用Copy/Paste
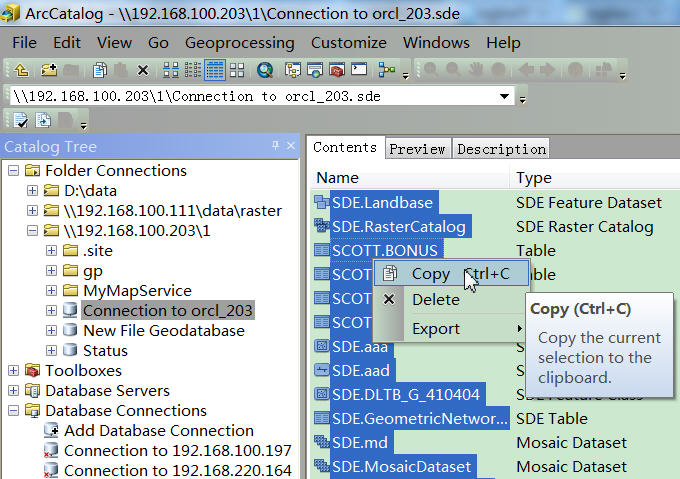
copy/paste推荐使用ArcCatalog方法,虽然你在ArcMap也可以,但是ArcCatalog可以批量拷贝。
注意:使用上述方法可能会出现的问题
a:如果用户是注册版本,而且对版本的数据进行保留的话,可能在使用过程中只迁移的是Default版本的数据,其他子版本的数据是不会迁移的。
b:假如用户的字段的精度有要求,可能用这种方法也有问题
比如原来的ArcSDE for Oracle要素类字段是double (20,2),如果直接将该要素类再导入另外的SDE,这个字段属性是不会修改的,但是将SDE导出到FGDB,那么因为文件存储和数据库存储的原理不一样,所以尽管FGDB能存储相关数据,但是关于原来的字段double(20,2)是不会记录的,那么将FGDB同数据导入到新的SDE,你会看到这个字段属性变为double(38,8),所以FGDB导入新的SDE,按照Oracle默认的最大Double存储。
解决方法:ArcGIS10.2可以直接进行字段属性修改
使用Oracle方法进行迁移
2:如果使用脚本,就是本博客推荐用户的Python脚本,使用这个脚本可以定时自动执行
说明一下Python脚本
我们在ArcSDE存储的对象一般包括三种
- Dataset:FeatureDataset(FeatureClass、Topology、Relationship、Geometric Network etc)、MosaicDataset、RasterDataset、RasterCatalog
- FeatureClass:FeatureClass Not In FeatureDataset
- Table:Attribute Table
import arcpy, os, string
#拷贝数据集对象
def CopyDatasets(start_db,end_db,num):
try:
#Set workspaces
arcpy.env.workspace = start_db
wk2 = end_db
datasetList = arcpy.ListDatasets()
#for feature classes within datasets
for dataset in datasetList:
print "Reading: {0}".format(dataset)
name = arcpy.Describe(dataset)
new_data=name.name[num:]
if arcpy.Exists(wk2 + os.sep + new_data)==False:
arcpy.Copy_management(dataset, wk2 + os.sep + new_data)
print "Completed copy on {0}".format(new_data)
else:
print "Dataset {0} already exists in the end_db so skipping".format(new_data) #如果有同名的就Skip
#Clear memory
del dataset
except Exception as e:
arcpy.AddError(e.message);
#拷贝单个要素类对象,不再数据集内的要素类
def CopyFeatureClasses(start_db,end_db,num):
try:
#Set workspaces
arcpy.env.workspace = start_db
wk2 = end_db
datasetList = arcpy.ListDatasets()
#for feature classes within datasets
for fc in arcpy.ListFeatureClasses():
print "Reading: {0}".format(fc)
name = arcpy.Describe(fc)
new_data=name.name[num:]
if arcpy.Exists(wk2 + os.sep + new_data)==False:
arcpy.Copy_management(fc, wk2 + os.sep + new_data)
print "Completed copy on {0}".format(new_data)
else:
print "Feature class {0} already exists in the end_db so skipping".format(new_data)
#Clear memory
del fc
except Exception as e:
arcpy.AddError(e.message);
#拷贝普通属性表
def CopyTables(start_db,end_db,num):
try:
#Set workspaces
arcpy.env.workspace = start_db
wk2 = end_db
datasetList = arcpy.ListDatasets()
#for feature classes within datasets
for table in arcpy.ListTables():
print "Reading: {0}".format(table)
name = arcpy.Describe(table)
new_data=name.name[num:]
if arcpy.Exists(wk2 + os.sep + new_data)==False:
arcpy.Copy_management(table, wk2 + os.sep + new_data)
print "Completed copy on {0}".format(new_data)
else:
print "Table {0} already exists in the end_db so skipping".format(new_data)
#Clear memory
del table
except Exception as e:
arcpy.AddError(e.message);
if __name__== "__main__":
start_db =r'\\192.168.100.203\1\New File Geodatabase.gdb' #源工作空间
end_db = r'\\192.168.100.203\1\Connection to orcl_203.sde' #目的工作空间
num =0 # (例如: sde.sde. is 8)
CopyDatasets(start_db,end_db,num)
CopyFeatureClasses(start_db,end_db,num)
CopyTables(start_db,end_db,num)Python脚本的目的就是将获得源工作空间和目的工作空间,里面有一个Num的选择,根据数据库不一样来记录要素类或者数据集前的字符串:
- SQL Server:sde.sde.featureclass或者sde.dbo.featureclass
- 那么只记录sde.sde.(sde.dbo.)一共8个字符,num=8
- Oracle:test.featureclass
- 那么只记录test.一共5个字符串,num=5
- FGDB,没有前缀,num=0
>>>
Reading: Landbase
Completed copy on Landbase
Reading: RasterDataset
Completed copy on RasterDataset
Reading: RasterCatalog
Completed copy on RasterCatalog
Reading: MosaicDataset
Completed copy on MosaicDataset
Reading: GeometricNetwork_BUILDERR
Completed copy on GeometricNetwork_BUILDERR有了这个脚本,加上定时自动运行,用户的备份工作也非常方便的解决了。
——————————————————————————————————-
版权所有,文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!
——————————————————————————————————-
转载自:https://blog.csdn.net/linghe301/article/details/8556417