白话空间统计之二十五:空间权重矩阵(二)
上一回说到使用距离对点数据取临近要素,如果不考虑标准化这个参数,那么每个要素对其临近的就只有相邻和不相邻两种情况。实际上在使用距离为空间关系概念的空间分析里面,经常使用的是反距离这种方法,所谓的反距离,就是取距离的倒数,我们来看看实际上反距离权重的情况是怎么样的。
数据还是上一篇的北京医院的数据,利用反距离参数制作空间权重矩阵且进行连线示意图之后,是这样的: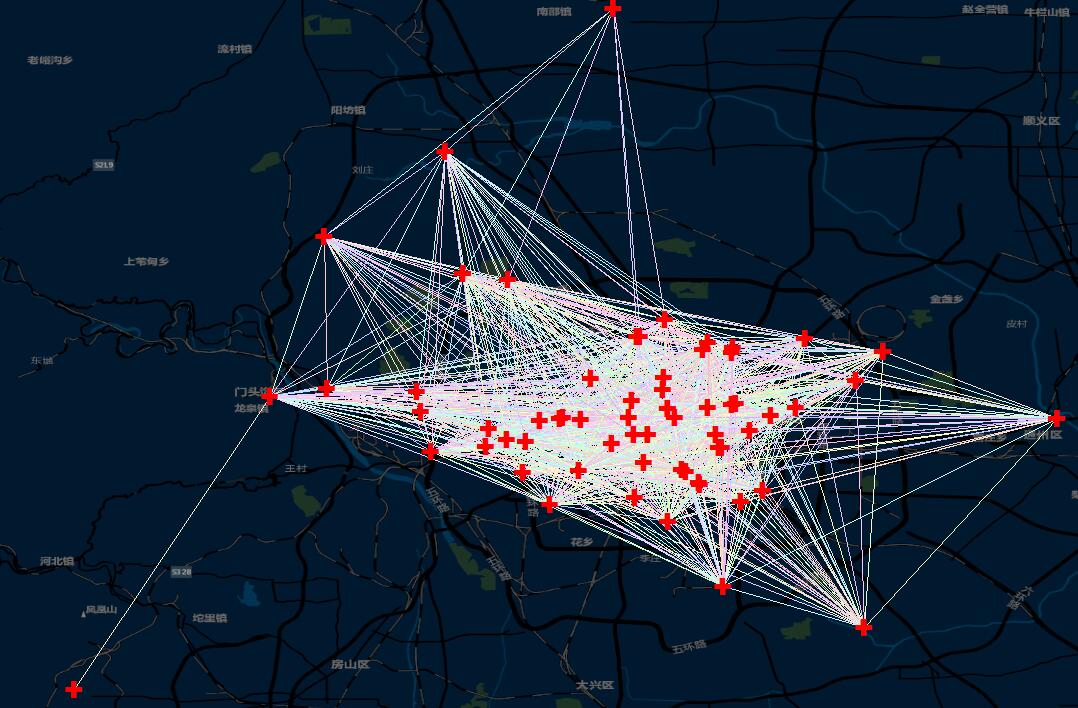
打开临近表之后,可以看见空间权重: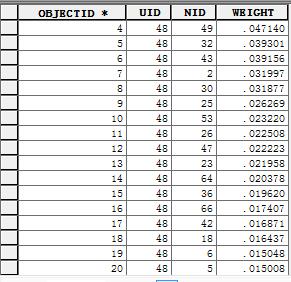
还是一样,看表格非常的不直观,下面我把这个数据映射到地图上去,选择比较中心的一个点,看看它和与它临近的数据的情况: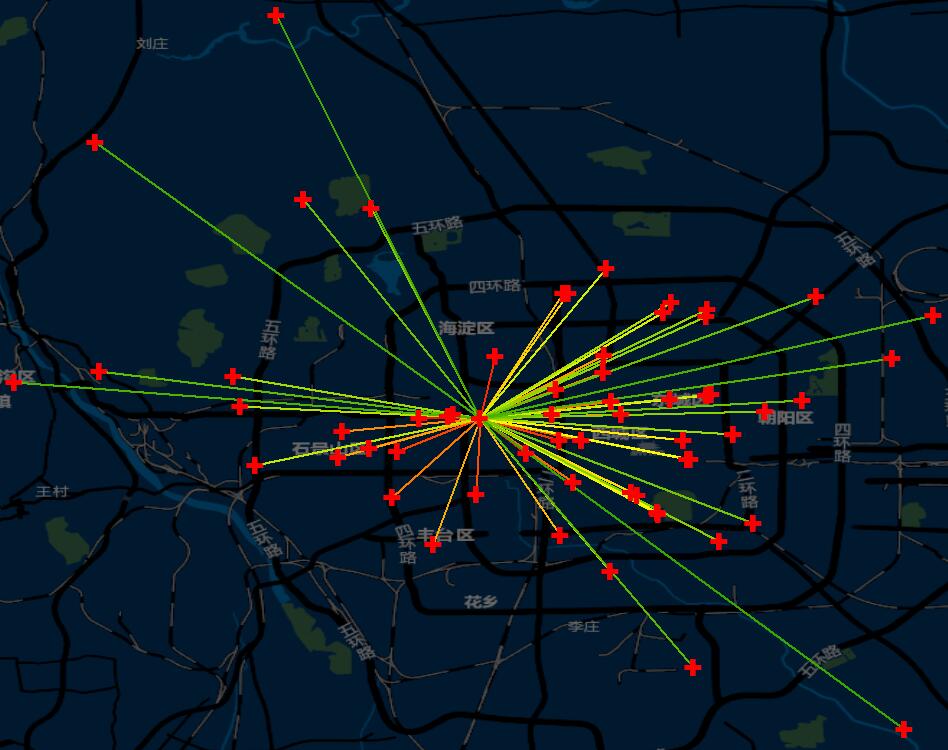
如果使用红黄绿色带代表影像力的权重(红色最高,绿色最低),大家会发现,他们的影响力正好与距离成反比,越远的,影响力越小,做成散点图,可以看出来: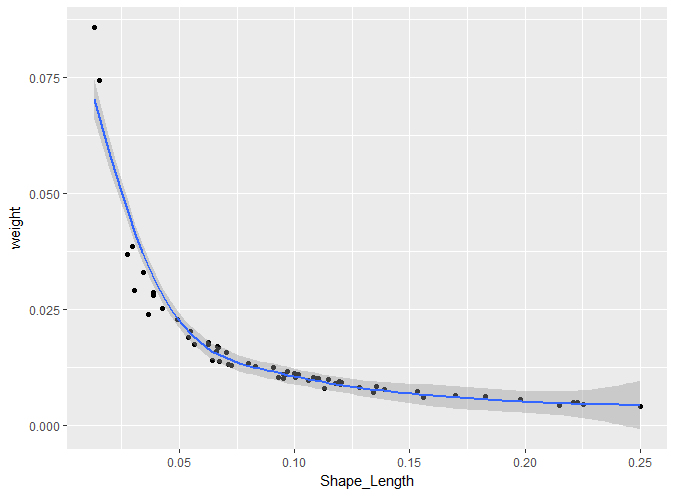
随着距离的增加,权重不断的下降。
下面我们换几种空间关系来制作空间权重矩阵,看看效果。
首先,先换成k临近: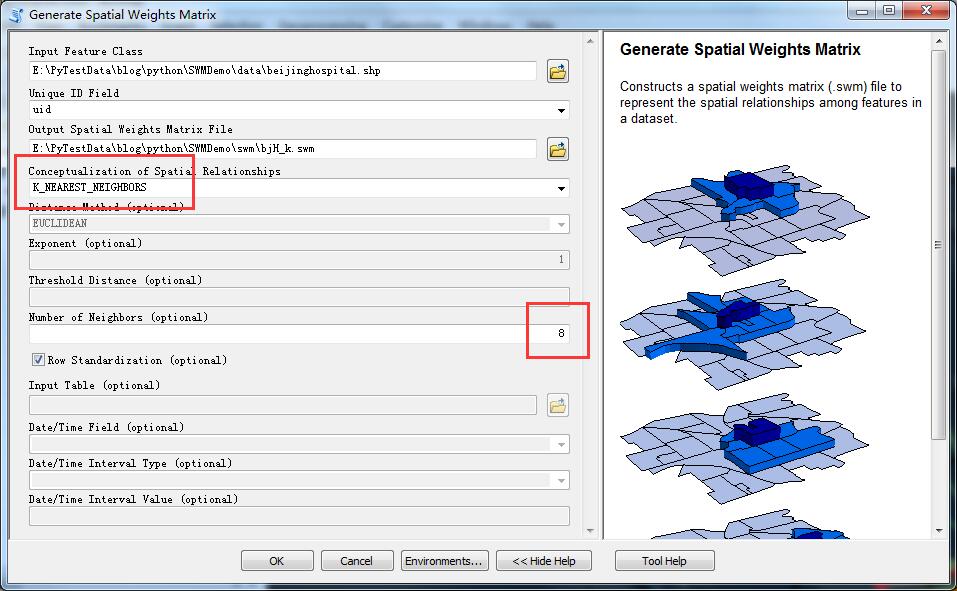
建成之后,统计结果如下: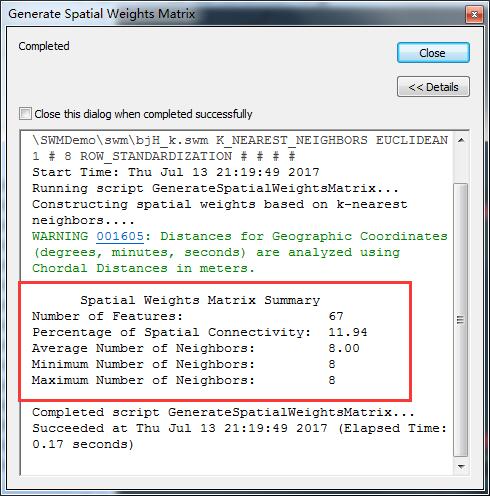
然后我们同样做成连线看看: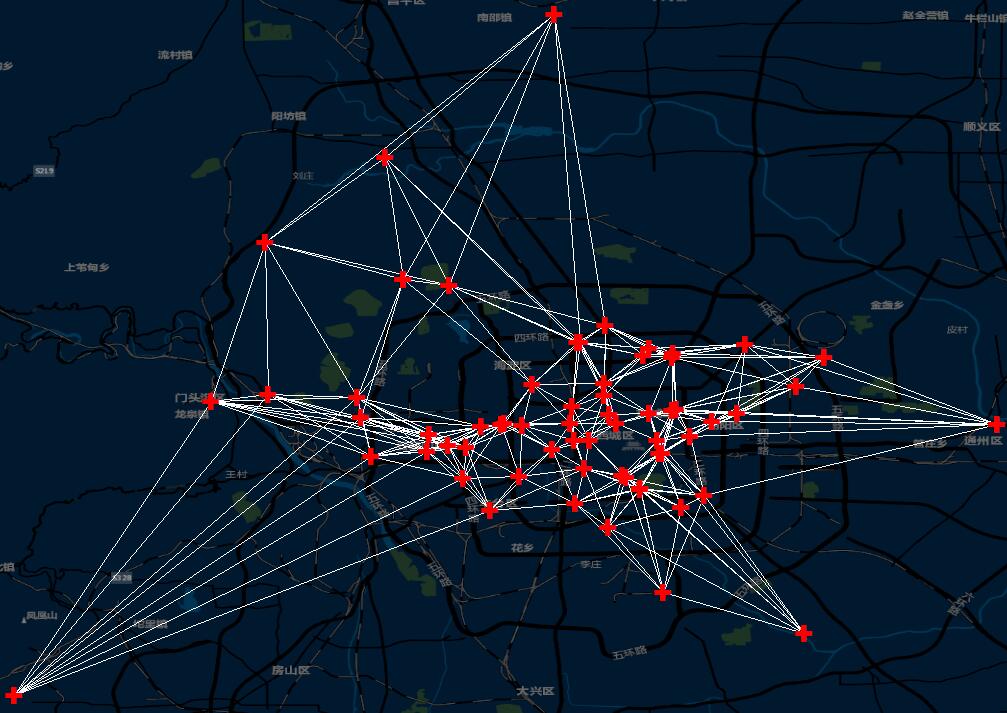
因为k临近忽略距离,仅寻找设备最近的数目,这里设置为8个点,所以每个点都去寻找离自己最近的8个点,效果就像上面这个图了,所有的权重都是一样(1/8 = 0.125):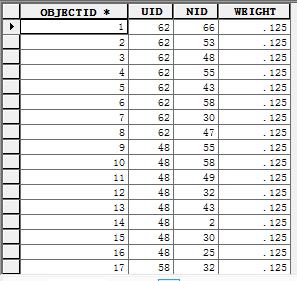
实际上还有很多方法,有兴趣的同学去看老文章“空间关系概念化”。
我们换不同的空间关系,来计算一下空间自相关,看看有啥不同。
因为我们的数据里面有“日门诊量”这个值,很多情况,这个值都作为医院的一个主要指标,所以我用这个值来计算一下空间自相关,看看北京的医院分布情况:
首先,选择用反距离关系做的全局空间自相关: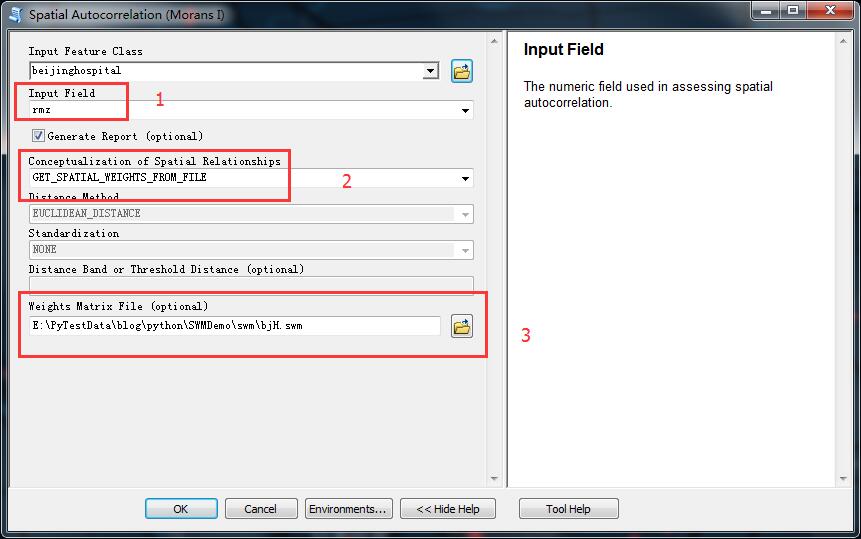
圈出红圈的三个地方,分别就是我们要设置的地方:
1、是进行全局空间自相关分析的字段。
2、选择使用预先生成的空间权重矩阵文件来作为空间关系。
3、选定之前制作好的空间权重矩阵关系文件。
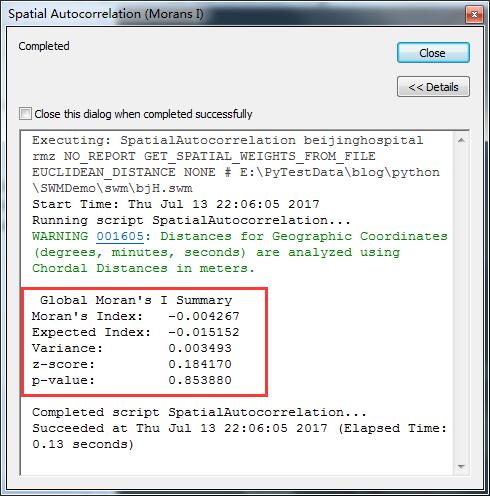
啥都不用看了直奔P值……大于0.8的p值,基本上就不用往下看其他的参数了,表示没有通过零假设,也就是说,这份数据从日门诊量这个维度上来看,与空间的分布没有任何关系。
完美的随机。
随机表示了无可预测,机会均等。从空间关系为距离的模式来看,医院的日门诊量与他们的空间位置基本上没有任何关系,表示在任何位置、任何距离的医院,他们的日门诊量情况都是机会均等的。
通俗说来,就是(在26公里范围内)不管热得发烫挤在在一堆的医院,还是方圆几十公里孤苦伶仃只有一根独苗的医院,他们的日门诊量都是机率均等的,不存在泊松分布的关系。
下面换为k临近试试: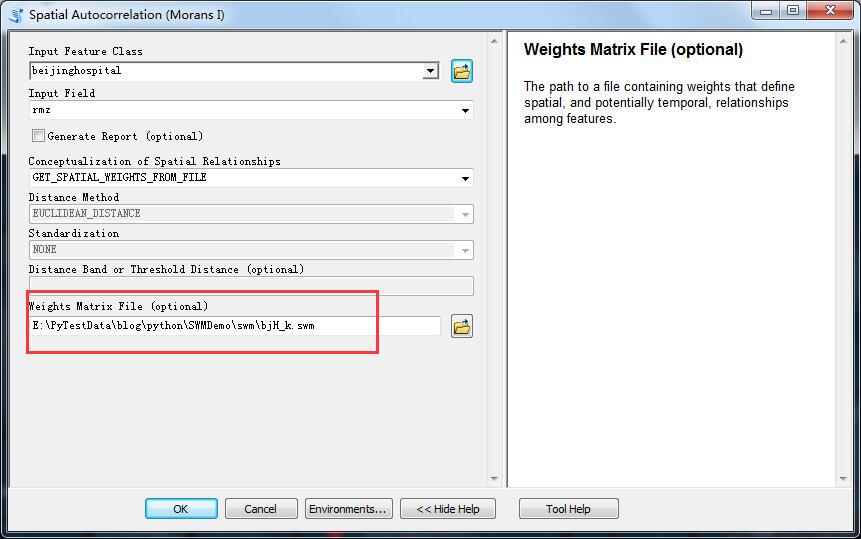
结果如下:
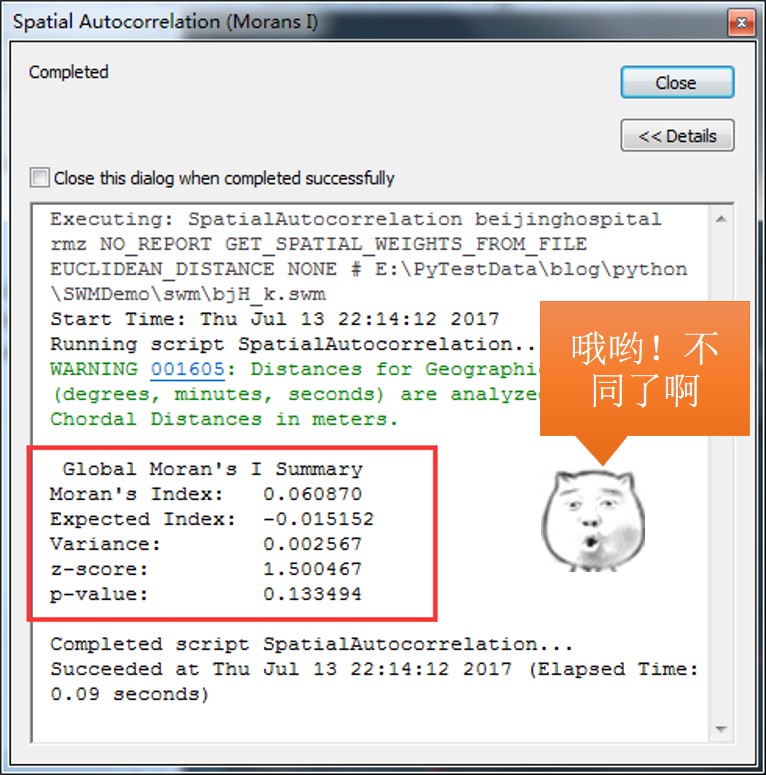
当我们将空间关系转换为k临近的时候,发现P值降到了0.133……嗯,虽然还是没有通过零假设检验,但是与上一次分析对,可以看出,如果将临近关系限制为最近的8家医院为临近的话,随机的程度会降低很多,而且已经接近了聚集分布模式了(z值为正,莫兰指数为正)。
从上面的例子可以看出来,使用不同的空间权重,空间统计的相关算法,会发生天翻地覆的变化。
从下一篇开始,我们开始讲,如何自定义ArcGIS的空间权重关系。
更多内容以及需要相关数据的,请关注虾神公众号:

转载自:https://blog.csdn.net/allenlu2008/article/details/75093944