白话空间统计二十三:回归分析番外-ArcGIS中的OLS(一)
在讲GWR的ArcGIS应用之前,首先讲讲ArcGIS里面的OLS(Ordinary least squares:普通最小二乘法)工具的应用和解读,毕竟GWR是从回归分析里面演化出来的,OLS又是回顾分析里面最简单的算法,如果不了解OLS的意义,那么GWR结果的最后意义一样没没理解。
关于回归分析和OLS的基础算法,我就不在这里赘述了,大家有兴趣去看相关资料和我以前的文章,这篇就直接扣住ArcGIS来讲。另外我以前也讲过和R语言相关的,有兴趣的同学回头去翻以前的内容。
ArcGIS的OLS工具,在如下位置:ArcGIS Toolbox ——空间统计工具箱——空间关系建模工具集——普通最小二乘法:
工具打开之后,是这个样子的: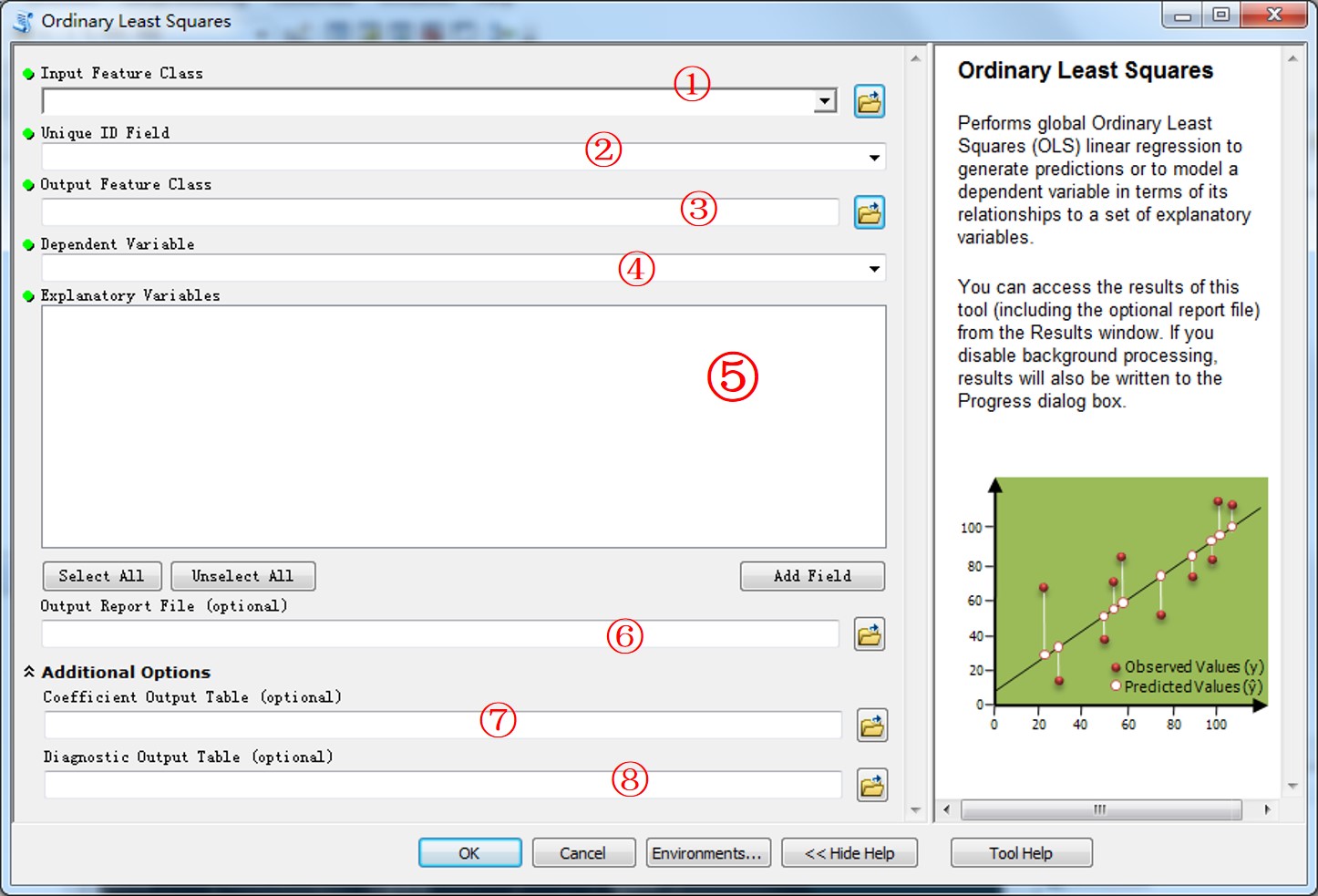
下面我就分别多8个参数做一个简单的介绍:
1、输入要素。
与R语言不同的是,在ArcGIS里面绝大部分工具都要输入的是一个要素类,熟悉ArcGIS的同学都知道,所谓的要素类,其实就是一个所谓的“图层”,需要有空间信息和属性信息两大类所组成。当然,在这个工具里面,你的要素类是点或者是线或者是面都无所谓,因为空间信息在这个工具里面,仅作为可视化来用。
然后肯定会有同学问我,如果我仅有一个属性表,能不能用ArcGIS这个工具呢?当然可以,仅需要稍微变通一下就可以了,比如你的属性表里面有100条记录,在这个属性表里面增加两个字段分布设为X/Y,然后随便给个坐标就行(比如都给0就可以了,反正不用),有坐标了,ArcGIS就可以直接把这个属性表格转换为要素类了。当然,要是这样做出来的要素类,仅能用于OLS,不能用于GWR(废话,空间信息是随便给的,怎么做GWR)。
2、唯一ID。
这字段主要是用来进行标识的,所以任何一个唯一标识符都行,但是有一个比较有意思的限制:在ArcGIS里面,只要要求输入唯一ID字段的地方,都不能使用ArcGIS自带的ObjectID(OID类型,在shape file里面一般设为fid,在空间数据库里面,叫做OBJECTID),这是因为这个OID字段,在使用ArcGIS的工具处理过这个图层之后,是会发生变化的。比如用排序工具排序之后,这个OID就发生变化了。所以,只要使用唯一ID的地方,都不允许使用OID字段。
如果属性表里面没有唯一字段怎么办?好办啊,新增一个字段,然后把OID字段里面的值给这个新字段就行,那么这个新的字段就是唯一ID字段了,且不会发生随便变化。
3、输出要素类。
输出计算结果的要素类,此要素类也是用来做可视化的。输出的结果后面再说。
4、因变量
因变量的字段。
5、自变量(解释变量)
解释变量的列表,注意,这里的解释变量仅会显示数值型的字段。
注意:这个关于因变量和自变量,ArcGIS里面有一个限制,就是不能有参与计算的字段的值完全相等,比如下面这种情况:
如果有这样一个字段参与到回归计算中,那么OLS就无法求解了。
6、输出报表文件:(可选)
输出一个PDF的报告文件,这个文件记录了分析过程中的所有信息,如果不选择这个参数, 这些信息仅作为分析结果在result显示。
7、系数输出表(可选)
这个系数输出表,会把各解释变量的模型系数、标准化系数、标准误差和概率都写入到这个表里面。
8、诊断输出表(可选)
整个模型的诊断信息,被写入到这个表里面,具体的意义后面再说。
下面通过一贯以来的山东数据进行分析,来简单讲解一下整个工具的使用。
每次我用山东的数据作为分析之后,都有同学问:虾神你为什么老用山东啊?用北京不好么?其实我也想用北京,但是北京能够比较容易获取的数据也就是区县级别的数据……北京只有16个区县,而做任意空间统计分析,经验值告诉我们,最少需要30个样本要素,才能获得比较好的结果……所以只能pass掉北京,改用山东了。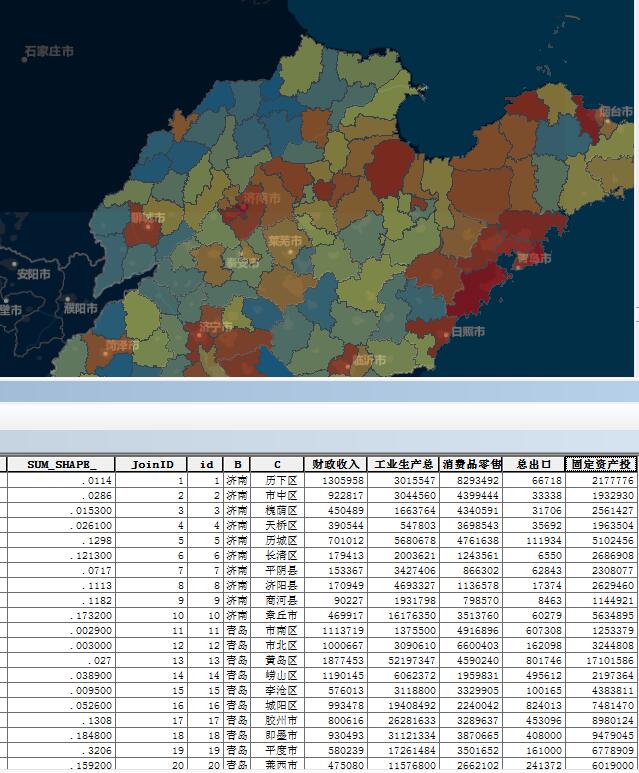
执行分析:
分析的结果首先可以在message里面显示出来,如下: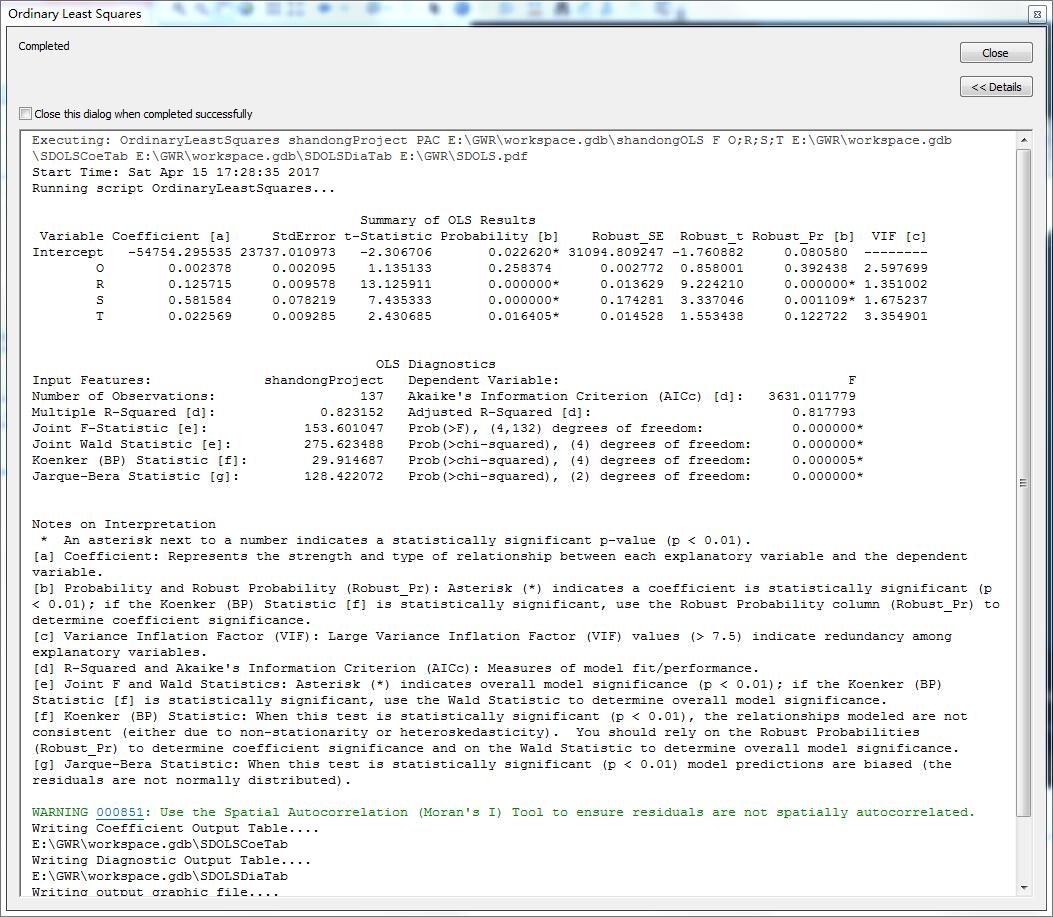
这些信息,如果选择了输出报表的话,会把上面的内容输出一个PDF文档,如下:
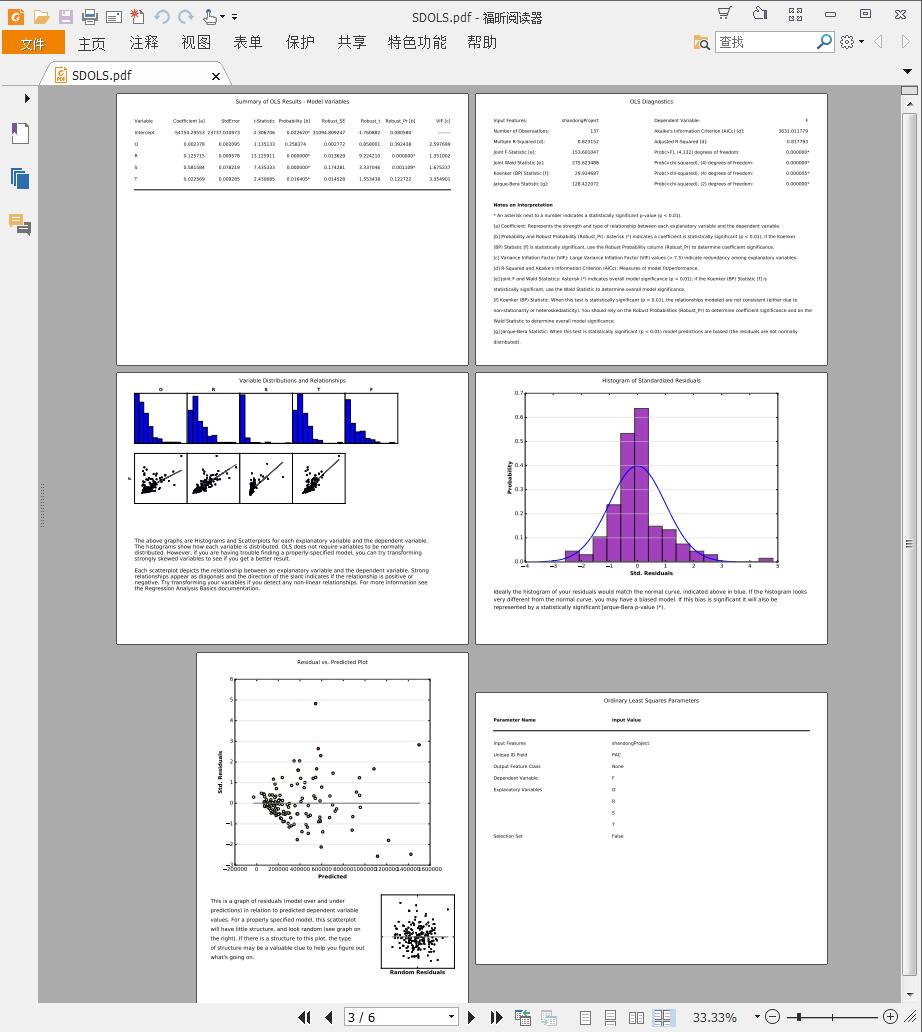
下面我们首先来对这个分析报告进行解释,看看里面到底是些啥内容:
首先,第一页是回归分析里面的标准输出表:
七个字段的说明及意义如下:
1、Coefficient 系数
回归分析的系数代表了每个自变量对因变量的贡献度,系数的绝对值越大,表示该变量在模型里面贡献越大,也表示了该自变量与因变量的关系越紧密。
另外这些系数的值表明了自变量与因变量的关系,比如S(总出口)的系数为0.58,则表示当总出口每增加一个单位,在其他自变量的值不发生改变的时候,因变量财政收入会增加0.58个单位。
而且这个系数也表示了自变量与因变量之间的关系类型,即它分为正向和负向,系数为正,表示正相关,系数为负,表示负相关。如下图所示:
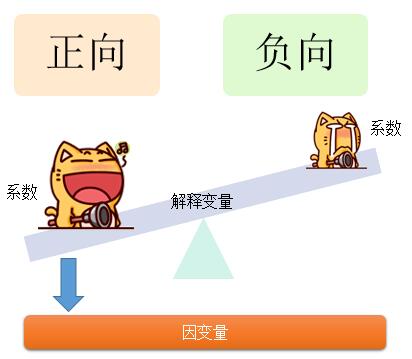
不管是正向大还是负向大,越大,表示与因变量的关系强度越大,只不过是正相关还是负相关的问题。
该参数是整个回归模型里面最重要的参数,没有之一。
2、StdError:回归系数的标准差
回归的标准误是模型中随机扰动项(误差项)的标准差的估计值。它的平方误差项的方差的无偏估计量,实际上又叫做误差均方,等于残差的平方和/(样本容量-待估参数的个数)。
这个值越小,表示模型的预测越准。
3、t-Statistic T统计量
在统计学里面,T统计量是假设检验的重要枢轴量,多用于两样本均值检验,回归模型系数显著性检验。
T-Statistic=平均值 / 标准误
一般来来说,这个值表示,与P-value意义差不多,都是在验证零假设的情况下,模型的显著性,但是有些时候P-value会有一些问题,比如丢失一些信息。计算机里面进行统计验证的时候,T统计量越大,表示越显著。
4、Probability 概率:
这个就是P值,关于它的解释,翻以前的文章,这里不多说。
5、6、7:Robust_SE Robust_t Robust_Pr [b]这三个字段,分别表示了标准差的健壮度、T统计量的健壮度和概率的健壮度。
在统计学里面,Robust Test通常被翻译稳健性检验,一般来说,就是通过修改(增添或者删除)变量值,看所关注解释变量的回归系数和结果是否稳健。
8、VIF (方差膨胀因子(Variance Inflation Factor,VIF)),这个值主要验证解释变量里面是否有冗余变量(即是否存在多重共线性)。一般来说,只要VIF超过7.5,就表示该变量有可能是冗余变量。
本来想一气说完的,发现有点高估自己了……好吧,那就分成两篇吧。
(待续未完)
转载自:https://blog.csdn.net/allenlu2008/article/details/70186312