白话空间统计二十:相似性搜索(三)
昨天简单的写了写相似性搜索的主要方法,这些方法对于学GIS的同学来说,实在是太简单了,所以很多同学反应:虾神泥垢了!科普也要有点深度可好,你是在凑字数么!!
好吧,我觉得上篇文章是有点点问题……我们要向前看,反正已经发出去了,这篇文章就扔那里吧,作为存档用。
今天继续写相似性搜索,昨天说了6种方法,简单是简单,但是大道至简,所有的分析算法,都是从这些简单的内容里面发展来的。不过还缺了一点点没有说完,就是所谓的匹配方法。
比如怎么比较两个数值,认为他们相似?
有的同学说,这还不容易么,我把数据一排序,越近就越相似了。没错,这是主要的方法之一,但是我举下面一个例子就可以看出来了:
有这样一个宠物体重表格:
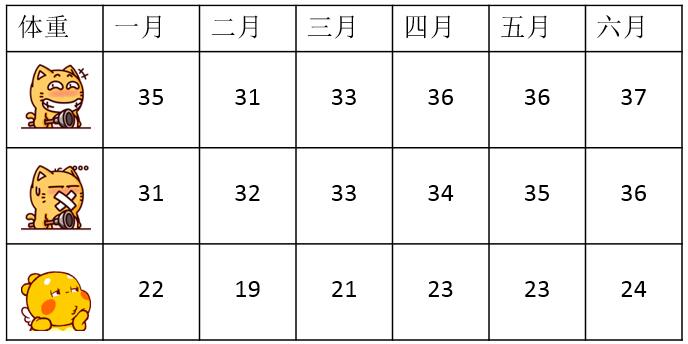
首先如果不计算,直接利用无敌瞎猜大法,凭着直觉,来看看哪两个相识度高呢?这还用说,当然是两个皮搋子猫了啊,如下:
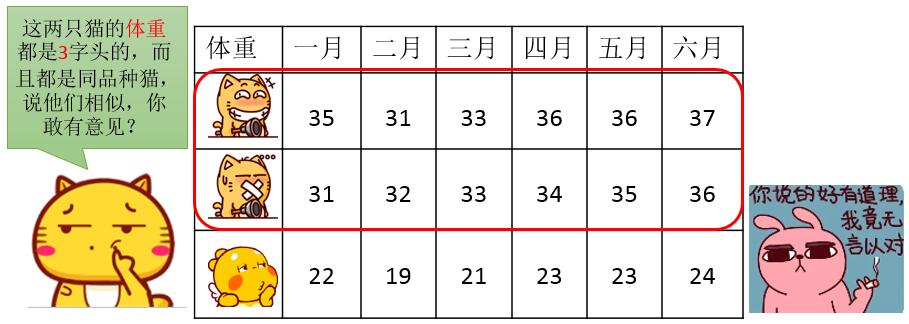
其实大家的预感和计算结果是一样的,但是如果我要研究的并非绝对数据呢,比如,我要研究的月份之间的变化趋势——这份数据是一份趋势数据,属于动态变化的,从变化的趋势,可以看出很多内容,比如:宠物喂食量?宠物的
心情?气候影响……等等等等,所以当我们画出趋势变化来之后,变成了如下情况:
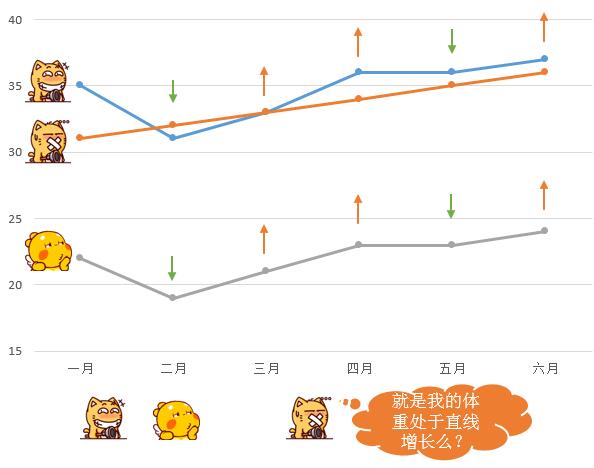
第一只傻笑猫和那个比丘龙的体重,响应的上升和下降趋势几乎完全一样,而第二种闭嘴猫的体重处于直线上升的状态(怎么这么像虾神的趋势呢?),所以不管从趋势上来看,还是从研究意义上来看,要进行相似性搜索的话,傻笑猫和比丘龙当之无愧的被归类到了相似里面。
上面举出的这个例子,可以看出,首先感觉是不可靠的(此次应有掌声)……其次就是不同的研究目的,应该采用不同的分析算法。
下面我就来介绍一下在ArcGIS里面,提供的集中不同的相似性搜索算法:
一、属性值相似性搜索法:
在ArcGIS里面,提供了ATTRIBUTE_VALUES
这样一个参数,选择这个参数进行相似性搜索的话,会忽略空间关系,直接通过选定的属性进行计算。计算方法如下:
对于每个候选要素,将从目标要素中减去标准化值(标准化值在ArcGIS里面,采用平均数),求得平方,然后再将每个结果相加。相加的总和即为该候选要素的相似性指数。所有候选要素经处理后,按照指数从小(最相似)到大(最不相似)的顺序对候选要素进行分级。计算过程如下:
(注意:在ArcGIS的帮助文档里面squaresthe
differences翻译成了:平方差,这是错误的,如下:)


但是实际上用的是差的平方:即(a-b)的平方,而非数学上面的平方差(a的平方-b的平方)
这里一定要注意,否则计算的时候会发现你的手动计算出来的结果和最终结果完全不一样……切记切记。
最后计算过程如下:

计算结束之后,可以看出来,如果仅仅是按照绝对数据进行计算,我们的感觉和结果是一样的,闭口猫的相似性系数为0.8,而比丘龙的相似性系数到达33,相似性系数越小,表现越相似,如果等于0,就表示他们完全相等。
而前面我说那种关于趋势变化的相关性,我们在下次继续。
转载自:https://blog.csdn.net/allenlu2008/article/details/50669827