白话空间统计十七:聚类和异常值分析(Anselin Local Moran’s I)
前面我们聊的各种指数,无论是莫兰指数还是P值Z得分,都是整体数据的结论,也就是所谓“全局莫兰指数(Globe Moran’s I)”,也就说,不管我给你多少数据,最后你就吐出一个来给我!这算神马!当然,从名字上来看,全局数据嘛,有一个给你就不错了。实际上作为我们玩GIS的人,最喜欢的就是出一张花花绿绿的地图,比如这样的:
或者是这样的:

所以我们更希望的是将我们输入的数据,标示出明显的数值来,比如我输入1000个要素,那么你别就给我1个数据啊,怎么也得吐出1000个数据来吧,甭管什么莫兰指数,P值Z得分啥的,不能给我省了。所以这里就要用到今天我们说的Anselin LocalMoran’s I方法了,而它与GlobeMoran’s I的区别,如下:
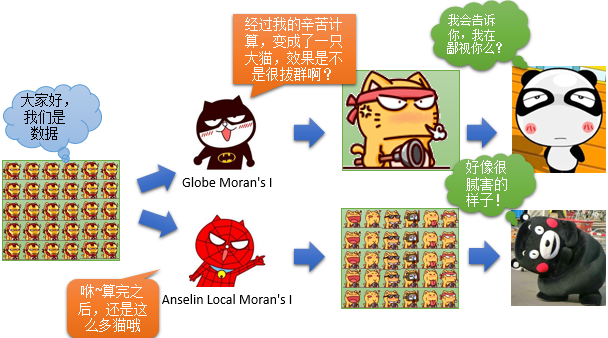
所以,这种算法比较符合我们做GIS的人的思维,那么这种可视为地理信息强迫症的特效药的Anselin Local Moran’s I算法,是哪位大爷提出来的呢?下面进入我们的算法科普时间:

上面这个脑门像土豆神一样明亮的老帅哥,就是ASU(美国亚利桑那州立大学)的地理与规划学院院长Luc Anselin教授,也是Anselin Local Moran’I算法的提出者,所以也就用了他的大名来标示这种算法。
如果做地理分析的,一定听说一个叫做GeoDa的软件,这个软件就是Anselin教授领导的ASU的地理空间分析和计算中心弄出来的神器。后来他的这个中心,就一直被人称为“GeoDa Center”
他在2008年的时候,当选为了美国科学院院士,与中国一样,当选院士被认为是美国学术界最高荣誉之一。
好了,起源介绍完了,下面我们来看看这种算法有些啥神奇的地方。
首先,他还是会计算各种常规的指数,比如Moran’s I以及P值Z得分啥的,但是他是针对整份数据中,每一个要素都会去记录一个相应的值,算出来就会变成这个样子:
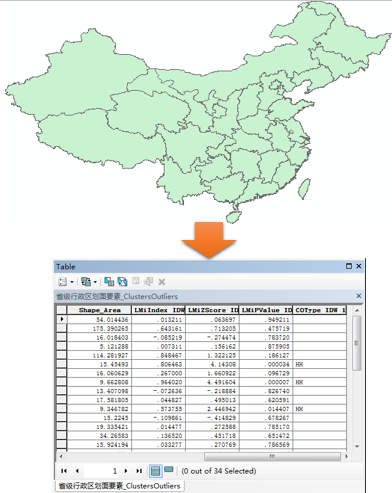
用中国每个省的GDP进行计算,算完对每一个省都会对应有一系列数据,前面三个就是每个省的Moran’s I和Z得分以及P值,这个就不解释了,大家有兴趣去看以前的文章,Anselin Local Moran’s I最强大的地方,就是他能够用自己身的数据,与周边的数据进行比较,生成COType这样一个字段。
COType是:聚类/异常值类型的简写(clustering / outlier Type),这个东西是啥东东呢,我们来看下面的解释:
首先,正常情况下,聚类我们认为是这样的:
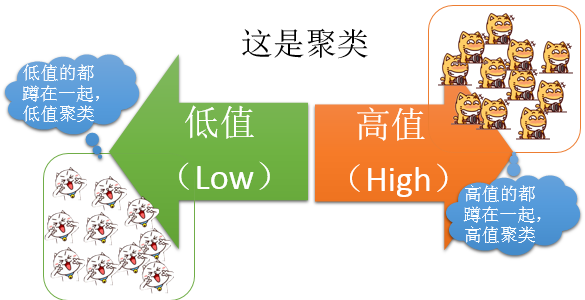
就是相同的类别会被放到一起。但是我们这个工具不但要计算聚类类型,还要计算的是异常的类型,何谓异常呢?异常自然就是下面这样的情况:
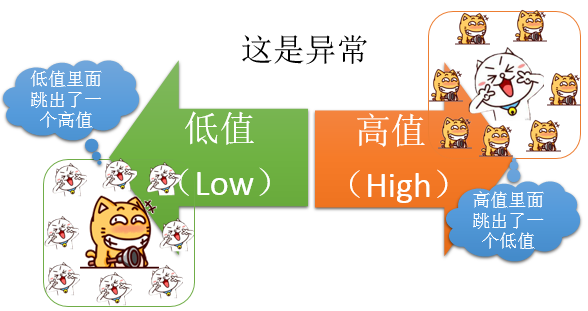
当然,还有一种情况,就是随机了,如下:
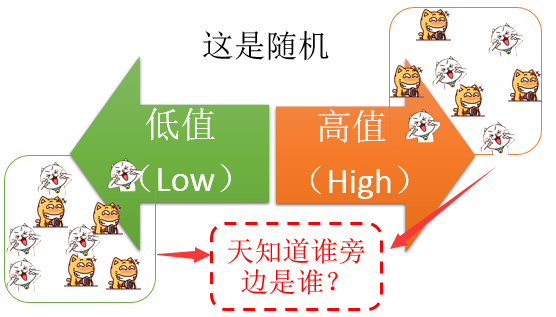
抛开随机不谈,我们谈聚类和异常的话,就会出现4种组合,如下:

而因为在地理空间上,不同的要素之间会出现相邻或者包围这种情况,所以就用了如下这种描述:周围一圈都是低值,围绕一个高值,这种情况被表示为HL,反之,周围都是一圈高值,围绕着一个低值,那么就表示为LH。
这种方式,能够明确的发现空间数据以及参与计算字段值中的一些规律,比如采用2008年的各省GDP进行计算的结果如下:
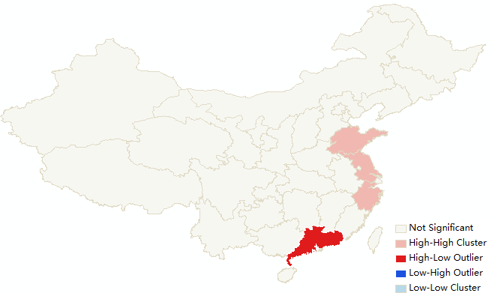
山东、江苏、浙江出现了明显的高值聚类,也就是说,他们的GDP与空间分布,不但自己的GDP处于高位,且旁边省份的GDP也是在高位。
而全国唯一个高值被低值包围的省,就是广东省,HL的意思是他自身的GDP处于高位,但是在空间分布上,它身边的省份都处于低值的情况。
从这里可以看出,采用AnselinLocal Moran’s I能够在更细粒度的范围下,对空间关系进行探索,至于如何使用这个工具,我们下次再说。
待续未完。
转载自:https://blog.csdn.net/allenlu2008/article/details/48470719