
白话空间统计二十:相似性搜索(四)
今天把相似性搜索写完……很多时候都能够严重的体会为什么网络上那么多小说,要么烂尾,要么太监了,最后这点结局真不好写。
今天的文章主要谈ArcGIS的空间统计模块中相似性搜索剩下的两种算法……本文有公式,有数学恐惧症的同学慎入。
上一次(相似性搜索三)我们写了属性值相似性搜索法,忘记了的同学回去翻历史记录……中间隔的有点多,需要有耐性,或者直接去翻虾神的博客:http://blog.csdn.net/allenlu2008
如果说属性值搜索用的是简单粗暴的平均数算法的话,第二种算法“等级属性值”,就相对没有那么粗暴了,当然……仅仅是没有那么粗暴而已。二者的粗暴程度,对比如下,一个是50米以内的猫,一个是100米以内的……那种电影里面被航弹在身边爆炸,依然健步如飞的……虾神只能说呵呵了。
本质上基本上没有改变……好吧,下面进入算法时间:
在ArcGIS里面,等级属性值算法的参数是:RANKED_ATTRIBUTE_VALUES ,也叫做分级属性值,方法非常简单,就是所有属性值,按照分级排序的方式进行归类,得出每一个属性所处的类别。
单个属性值非常容易理解,但是如果有多个属性值怎么办呢?方法有是和属性值搜索一样了,采用差的平方计算相似度,然后进行多个相似度累加……只不过计算的时候用的是类别,如下图所示:
所有要素的等级指数计算完成之后,把这些指数从小到大进行排序,排序完成之后,就是相似度的排名。等级指数的计算方法如上图。排名越靠前(数值小)的,表示越相似,越靠后(数值大)的,表示越相异。
第三种相似度就是在自然语言处理领域里面最常用的“属性剖面”方法了,也叫做“余弦相似性搜索”,在ArcGIS里面,它的参数叫做“ATTRIBUTE_PROFILES ”。
余弦相似度在数学表达里面是对于两个向量之间相似表达最优的一种解,表达和公式如下: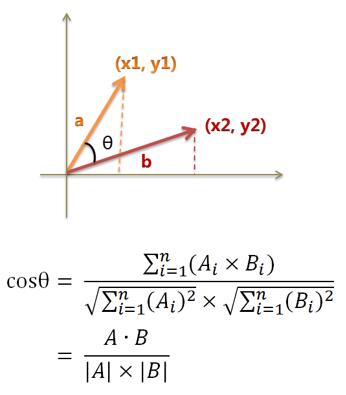
这个算法我最早是在《数学之美》里面看到过,网络上对于这种算法的解释也都是汗牛充栋了,所以我这里就不做详细的解答,大家自己搜索一下就好。
ArcGIS利用余弦相似度来计算两个要素的相似度的时候,一定要最至少有两个属性,而不像前面两个算法一样,最少一个属性就可以了。
运算过程如下:
1、对所有数据进行向量标准化。
2、计算余弦相似度。
3、等级排序
如下所示:(在Excel里面进行计算)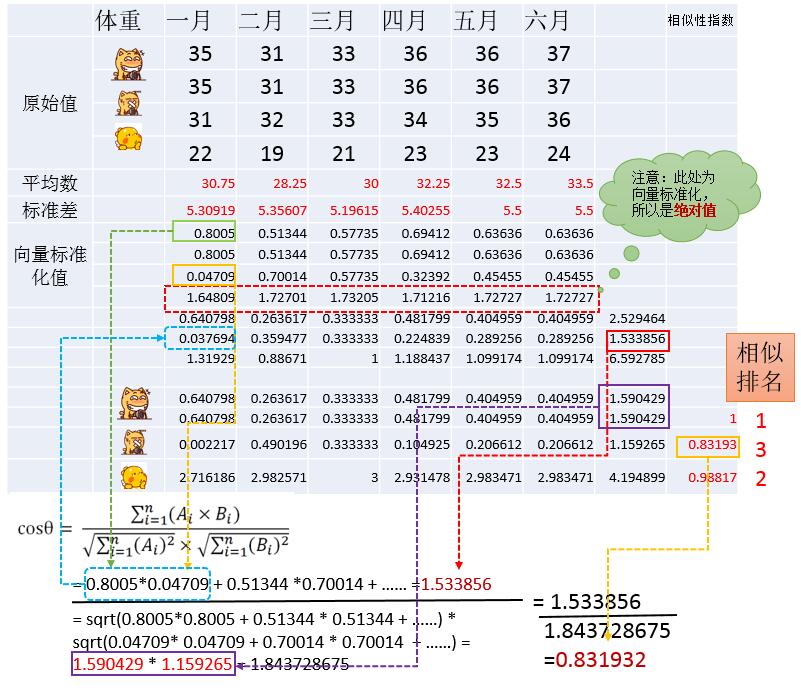
ArcGIS里面的计算结果如下: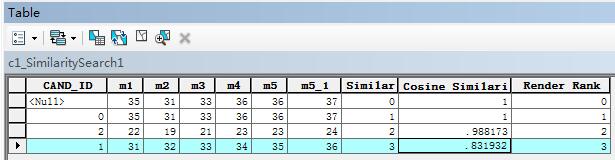
余弦相似度搜索,就和数据本身没有多大关系了,因为使用向量的方式,所以更关注数据之间的变化,如下所示:
最后,有同学可能想起来了……虾神,你写的不是空间统计么?为什么整个儿都是属性计算……空间哪里去了……好吧,其实这个工具主要就是用来进行属性相似性搜索的,如果要加入空间因素,有以下两个办法:
1、利用面积或者周长一类的空间属性,加入到相似性搜索的参数中去。
比如我们知道某濒危物种在某地(面区域)生存很好,如果希望找到该物种也可能茁壮成长的其他地方。这样就需要搜索与物种成功存活环境相似的地方,而且可能还需要这些地方足够大,足够紧凑以保证物种成活。这一种此分析中,我们就可以计算每个面区域的紧凑性指标(一般紧凑性测量基于与圆圈区域具有相同周长的面的面积)。运行相似性搜索工具时,紧凑性测量和能够反应面的尺寸 (Shape_Area) 的属性包括在追加到输出的字段参数中。
2、利用空间权重矩阵,生成相应的空间权重,加入计算。
又比如或许我是一个准备对扩大业务零售商。而且已经有了个成功店铺,那么我要开下家店铺的时候,我就想找到一些能够反映成功关键特征的属性来帮助我查找扩大业务的候选位置。比如我销售的产品对大学生最有吸引力,并且还想避免靠近我的现有店铺以及还要远离远离竞争者。那么就可以使用近邻分析工具创建空间变量:与大学或大学生密度较大处之间的距离、与现有店铺的距离以及与竞争者的距离。再进行相似性搜索时,可以将这些空间变量包括在追加到输出的字段参数之中。
转载自:https://blog.csdn.net/allenlu2008/article/details/50914309




